高并发--Nginx+lua是如何扛住的
Posted EffectiveCoding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发--Nginx+lua是如何扛住的相关的知识,希望对你有一定的参考价值。
提到高并发或者抗压力,有这种高qps经验的同学第一反应大都是nginx + lua + Redis,网上也满天非那种高并发架构方案大都是这种,但是Nginx + lua 来做接入层到底是怎么抗住压力的呢?
本篇顺序:
1、Nginx 如何抗住的高并发,工作模式是怎样的,利用了哪些技术
2、常见的IO模型及 异步非阻塞IO的优势
3、epoll相对于其他模型为何这么强大
第一阶段:
Nginx 不同于 Apache 的一点就是,Nginx 采用单线程,非阻塞,异步 IO 的工作模型,并不会每一个新进程都会起一个新的进程或者线程来处请求,Nginx利用的是epoll模型。然后来看一下Nginx的工作模型:
nginx 工作模型有两种实现方式:
单工作进程是指,一个工作进程中有多个工作线程,只有一个工作进程 + master进程
多工作进程是指,一个工作进程中只有一个工作线程,然后有多个工作进程 + master进程
就是下面这种机遇epoll 模型构建的单线程,非阻塞,异步 IO的 单线程处理多链接工作模型来抗住的压力,下面来仔细的看看Nginx的内部实现。
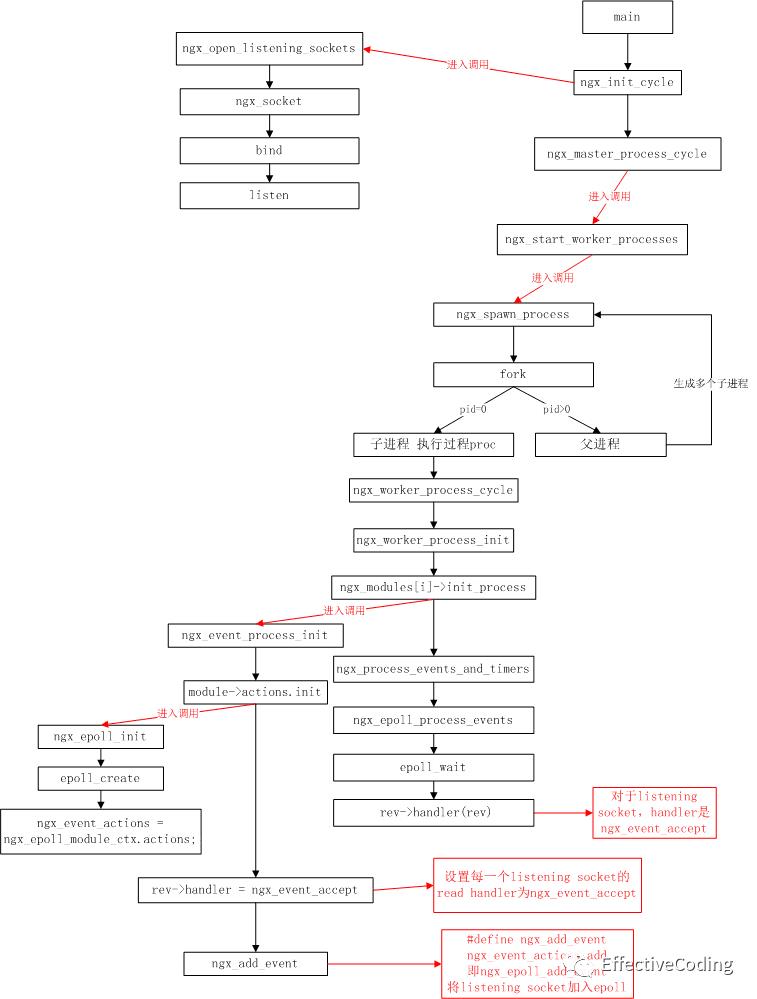
master 主要负责,接受管理员信号向worker发送指令,负责worker进程的生命周期,通知的类型有:worker 不再接受新请求、worker 退出&销毁等,可以把master 看作一个worker 的管理器,我们和master交互来间接管理worker。nginx一些无损重启或者reload配置文件等就是这么来实现的。
worker 顾名思义是处理具体网络事件的,从初始化nginx开始讲:
首先被创建的是master,在创建时先建立好需要listen的socket(listenfd),然后从master从fork出多个worker ,这样相当于master listenfd就被继承过来了,所以说所有的worker会在新连接到来时变得可读,为保证只有一个进程处理链接,所有的worder进程在注册listenfd读事件发生时会先去抢占accept_mutex,抢到互斥锁的那个worker进程才会注册listenfd读事件,在读事件里面调用accept接受连接,然后就开始读取请求、解析请求、处理、产生响应、断开连接。处理过程中如果碰到了IO操作,就开始使用基于epoll的非阻塞,异步 IO工作模式,发生IO时work会先把这个socket夯在哪里 去处理别的请求,等IO完成后再处理剩下的逻辑。nginx 就这么抗住了大量的连接并且充分利用cpu进行处理的。
然后从网上盗两张图来看一下nginx 创建监听到accept的流程:
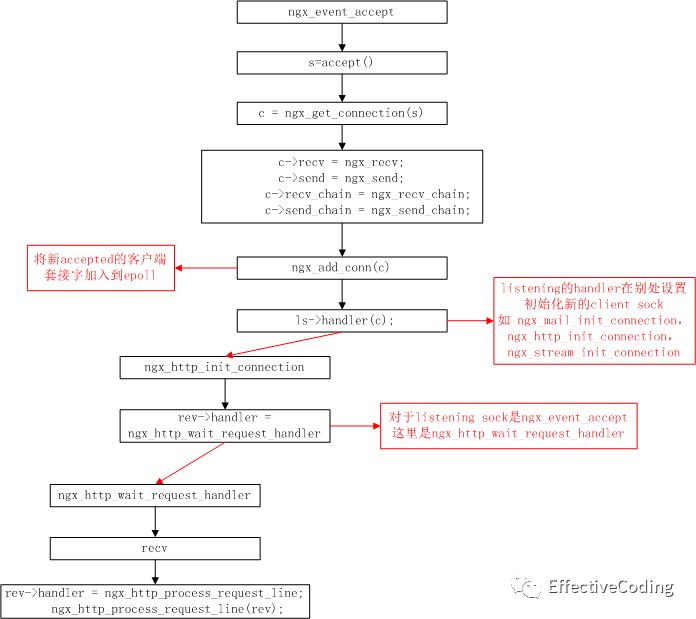
然后监听字ngxeventaccept 的处理流程:
第二阶段:
所提到的异步 非阻塞IO 及常见几种IO的差别:
两阶段式IO:
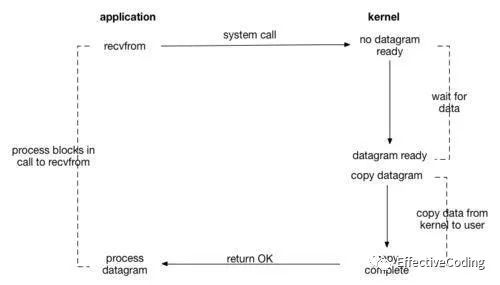
【阻塞 blocking IO】:
recvfrom -> [syscall -> wait -> copy ->] return OK!
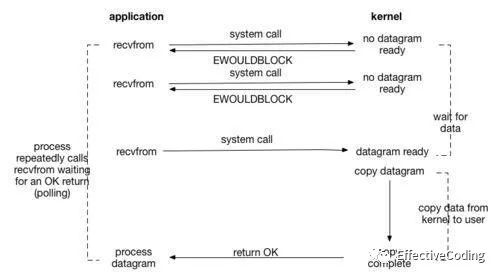
【非阻塞 nonblocking IO】:
recvfrom ->[syscall -> wait -> ] return no data ready
recvfrom ->[syscall -> wait -> ] return no data ready
recvfrom ->[syscall -> wait -> ] return data ready
recvfrom ->[syscall -> copy -> ] return OK!
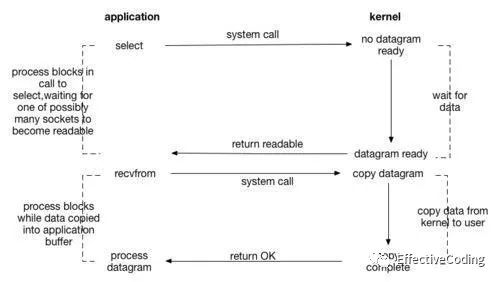
【多路复用IO multiplexingIO】
其中每个IO都是非阻塞IO,先使用poll/select 轮训IO句柄,如果有准备好的,开始第二阶段IO(阻塞读数据)
select/poll -> [syscall -> wait -> ] return readable
recvfrom -> [syscall -> copy -> ] return OK!
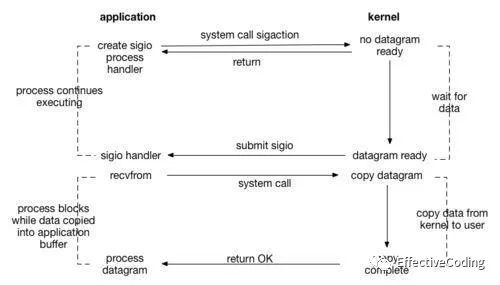
【信号驱动IO signal driven IO】
首先构建一个信号处理器,然后第二阶段阻塞读数据
signal handle -> [syscal -> wait -> ] return
[syscall -> ] signal handle-> recvfrom -> [syscall -> copy -> ] return OK!
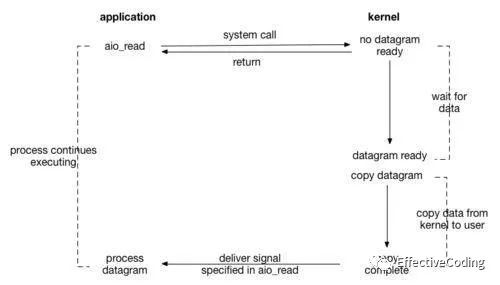
【异步IO asynchronous IO】
两个阶段都是非阻塞的
aio_read -> [syscall -> wait -> ] return
[syscall -> copy -> ] aio_readCallback
【对比】
第三阶段:
select /poll/ epoll 对比
单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,
select不足的地方:
1 每次select都要把全部IO句柄复制到内核
2 内核每次都要遍历全部IO句柄,以判断是否数据准备好
3 select模式最大IO句柄数是1024,太多了性能下降明显
poll:
poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在FDSETSIZE为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
epoll的特点
1 每次新建IO句柄(epoll_create)才复制并注册(epoll_register)到内核
2 内核根据IO事件,把准备好的IO句柄放到就绪队列
3 应用只要轮询(epoll_wait)就绪队列,然后去读取数据
只需要轮询就绪队列(数量少),不存在select的轮询,也没有内核的轮询,不需要多次复制所有的IO句柄。因此,可以同时支持的IO句柄数轻松过百万。
详细的可以看一下这篇文章:
https://zhuanlan.zhihu.com/p/39970630
以上是关于高并发--Nginx+lua是如何扛住的的主要内容,如果未能解决你的问题,请参考以下文章
高并发 Nginx+Lua OpenResty系列——Lua模版渲染
高并发 Nginx+Lua OpenResty系列——Lua模版渲染
高并发 Nginx+Lua OpenResty系列(10)——商品详情页