每天一个知识点:Redis 主从库如何实现数据一致?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每天一个知识点:Redis 主从库如何实现数据一致?相关的知识,希望对你有一定的参考价值。
参考技术A Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
奥妙就在于 repl_backlog_buffer 这个缓冲区。当主从库断连后,主库会把断连期间收到的写操作命令,写入 replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。刚开始的时候,主库和从库的写读位置在一起,这算是它们的起始位置。随着主库不断接收新的写操作,它在缓冲区中的写位置会逐步偏离起始位置,我们通常用偏移量来衡量这个偏移距离的大小,对主库来说,对应的偏移量就是 master_repl_offset。主库接收的新写操作越多,这个值就会越大。同样,从库在复制完写操作命令后,它在缓冲区中的读位置也开始逐步偏移刚才的起始位置,此时,从库已复制的偏移量 slave_repl_offset 也在不断增加。正常情况下,这两个偏移量基本相等。主从库的连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。在网络断连阶段,主库可能会收到新的写操作命令,所以,一般来说,master_repl_offset 会大于 slave_repl_offset。此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。需要注意的是,因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。要想办法避免这一情况,一般而言,我们可以调整 repl_backlog_size 这个参数。这个参数和所需的缓冲空间大小有关。缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl_backlog_size = 缓冲空间大小 * 2,这也就是 repl_backlog_size 的最终值。
如何验证主从数据库数据内容一致
用 pt-table-checksum 时,会不会影响业务性能?
实验
实验开始前,给大家分享一个小经验:任何性能评估,不要相信别人的评测结果,要在自己的环境上测试,并(大概)知晓原理。
我们先建一对主从:
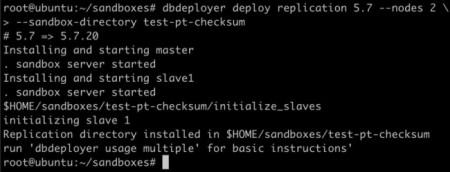
然后用 mysqlslap跑一个持续的压力:
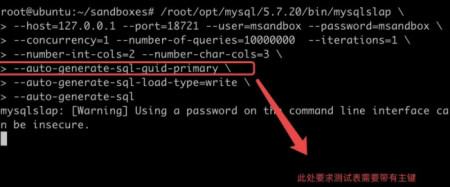
开另外一个会话,将 master 上的 general log 打开:

然后通过 pt-table-checksum 进行一次比较:
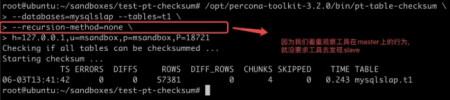
查看 master 的 general log,由于 mysqlslap 的影响,general log 中有很多内容,我们找到与 pt-table-checksum 相关的线程:

将该线程的操作单独列出来:
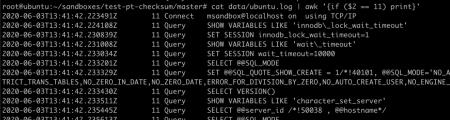
操作比较多,我们一点一点来说明:

这里工具调小了 innodb 锁等待时间。使得之后的操作,只要在 innodb 上稍微有锁等待,就会马上放弃操作,对业务影响很小。
另外工具调小了 wait_timeout 时间,倒是没有特别的作用。
工具将隔离级别调整为了 RR 级别,事务的维护代价会比 RC 要高,不过后面我们会看到工具使用的每个事务都很小,加上之前提到 innodb 锁等待时间调到很小,对线上业务产生的成本比较小。
RR 级别是数据对比的基本要求。

工具通过一系列操作,了解表的概况。工具是一个数据块一个数据块进行校验,这里获取了第一个数据块的下边界。

接下来工具获取了下一个数据块的下边界,每个 SQL前都会 EXPLAIN 一下,看一下执行成本,非常小心翼翼。

之后工具获取了一个数据块的 checksum,这个数据块不大,如果跟业务流量有冲突,会马上出发 innodb 的锁超时,立刻退让。
以上是 pt-table-checksum 的一些设计,可以看到这几处都是精心维护了业务流量不受影响。
工具还设计了其他的一些机制保障业务流量,比如参数 --max-load 和 --pause-file 等,还有精心设计的数据块划分方法,索引选择方法等。大家根据自己的情况配合使用即可达到很好的效果。
总结
本期我们介绍了简单分析 pt-table-checksum 是否会影响业务流量,坊间会流传工具的各种参数建议或者不建议使用,算命的情况比较多,大家都可以用简单的实验来分析其中机制。
还是那个观点,性能测试不能相信道听途说,得通过实验去分析。
参考技术A percona-toolkit-2.2.8-1.noarch.rpm有两个工具可以验证MySQL主从数据的一致性
安装tookkit需要一些依赖包
yum install perl perl-DBI perl-DBD-MySQL perl-IO-Socket-SSL perl-Time-HiRes -y
实验环境

在Master上初始化实验数据
create database mvbox;
use mvbox;
create table test(id int primary key,name varchar(20));
insert into test values(1,'a'),(2,'b'),(3,'c'),(4,'d');
因为主从环境已经搭建,这些数据会自动同步到Slave上。
在Slave从库添加一个数据,模拟主从数据不一致的场景。
insert into test values(5,'e');
在Master主库执行pt-table-checksum命令。
它会使用concat_ws函数将数据合并为一行,然后使用crc32函数生成校验码,最后将其插入percona库的checksums表中。
因为主从环境,这个数据会复制到Slave
也就是说Slave的percona.checksums表,存放的是主库数据的校验码。
所以在Slave对数据执行同样的校验,然后比对checksums表中的数据,就可以验证主从是否一致。
所以执行pt-table-checksum命令的帐号,至少需要有全库的只读权限和percona库的读写权限。
create user xx;
GRANT SELECT, PROCESS, SUPER, REPLICATION SLAVE ON *.* TO 'xx'@'%' IDENTIFIED BY 'xx';
grant all privileges on percona.* TO 'xx'@'%' IDENTIFIED BY 'xx';
查看主从一致的情况

TS :完成检查的时间。
ERRORS :检查时候发生错误和警告的数量。
DIFFS :0表示一致,1表示不一致。当指定--no-replicate-check时,会一直为0,当指定--replicate-check-only会显示不同的信息。
ROWS :表的行数。
CHUNKS :被划分到表中的块的数目。
SKIPPED :由于错误或警告或过大,则跳过块的数目。
TIME :执行的时间。
TABLE :被检查的表名。
常用参数
--nocheck-replication-filters :不检查复制过滤器,建议启用。后面可以用--databases来指定需要检查的数据库。
--no-check-binlog-format : 不检查复制的binlog模式,要是binlog模式是ROW,则会报错。
--replicate-check-only :只显示不同步的信息。
--replicate= :把checksum的信息写入到指定表中,建议直接写到被检查的数据库当中。
--databases= :指定需要被检查的数据库,多个则用逗号隔开。
--tables= :指定需要被检查的表,多个用逗号隔开
h=127.0.0.1 :Master的地址
u=root :用户名
p=123456:密码
P=3306 :端口
可以看到这个工具已经检测到了主从不一致的情况。
如果发生不一致,可以使用pt-table-sync命令修复。
需要注意的是这个命令需要在Slave从库执行。
使用print参数,他会在屏幕显示修复的SQL语句。然后可以手工确认并执行。
也可以通过这个命令自动执行,不过这样会修改从库的数据,感觉不是太安全。
需要特别注意的是这两个命令执行的过程中,会对表上共享锁,所以生产环境要慎重选择执行时间。
本回答被提问者和网友采纳以上是关于每天一个知识点:Redis 主从库如何实现数据一致?的主要内容,如果未能解决你的问题,请参考以下文章