总结了一些算法二叉树操作的干货 (附Python代码)
Posted 程序IT圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了总结了一些算法二叉树操作的干货 (附Python代码)相关的知识,希望对你有一定的参考价值。
注:以下所有案例均来源于LeetCode,部分源码参考他人题解。
二叉树遍历是最基本和典型的操作,主要分为2大类共4种遍历形式,分别是DFS(深度优先)和BFS(广度优先,即按层级遍历),其中DFS又具体分为前序、中序和后序遍历。这里的前中后序实际上是指根节点相对左右子节点的位置来描述的,如前序遍历就是指根节点在左右节点之前,中序则是根节点在左右子节点之间,后序则是根节点在最后。
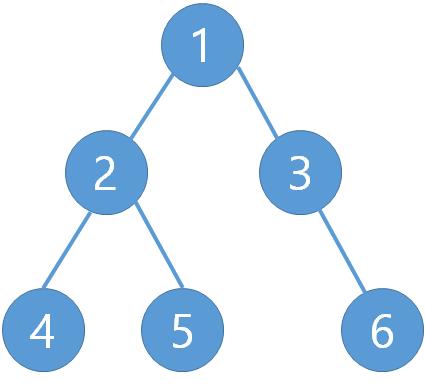
如图中的二叉树所示,则其不同遍历方式的结果分别为:
前序:1-2-4-5-3-6
中序:4-2-5-1-3-6
后序:4-5-2-6-3-1
层级遍历:1-2-3-4-5-6
1class Solution:
2 def preorderTraversal(self, root: TreeNode) -> List[int]:
3 self.res = []
4 self.dfs(root)
5 return self.res
6
7 def dfs(self, node):
8 if not node: return
9 self.res.append(node.val)
10 self.dfs(node.left)
11 self.dfs(node.right)
1class Solution:
2 def preorderTraversal(self, root: TreeNode) -> List[int]:
3 return [root.val]+self.preorderTraversal(root.left)+self.preorderTraversal(root.right) if root else []
上面代码中,只要稍微更改主程序中递归调用的先后顺序,即可很容易改写成其他遍历方式。
用递归可以实现的操作,一般来说迭代也可以,二叉树的遍历也不例外。
1class Solution:
2 def preorderTraversal(self, root: TreeNode) -> List[int]:
3 stack = [root]
4 values = []
5 while stack:
6 s = stack.pop()
7 if s:
8 values.append(s.val)
9 stack.append(s.right)
10 stack.append(s.left)
11 return values
1class Solution:
2 def inorderTraversal(self, root: TreeNode) -> List[int]:
3 res = []
4 stack = []
5 p = root
6 while p or stack:
7 while p:
8 stack.append(p)
9 p = p.left
10 p = stack.pop()
11 res.append(p.val)
12 p = p.right
13 return res
1class Solution:
2 def postorderTraversal(self, root):
3 if root is None:
4 return []
5 result = []
6 stack = [root]
7 while stack:
8 p = stack.pop()
9 result.append(p.val)
10 if p.left:
11 stack.append(p.left)
12 if p.right:
13 stack.append(p.right)
14 return result[::-1]
1class Solution:
2 def preorderTraversal(self, root: TreeNode) -> List[int]:
3 nodes = [(root, False)]
4 res = []
5 while nodes:
6 node, seen = nodes.pop()
7 if not node:
8 continue
9 elif seen:
10 res.append(node.val)
11 else:
12 nodes.append((node.right, False))
13 nodes.append((node.left, False))
14 nodes.append((node, True))
15 return res
1class Solution:
2 def levelOrder(self, root: TreeNode) -> List[List[int]]:
3 nodes, res = [root], []
4 while nodes:
5 res.append([node.val for node in nodes if node])
6 nodes = [n for node in nodes for n in [node.left, node.right]]
7 return res
对称二叉树是指二叉树具有镜像的特点,即对称位置的节点具有相同值。
最直观的想法是递归判断:若一棵二叉树是镜像的,那么要求:
左右节点取值相等
左节点的左子树与右节点的右子树镜像
左节点的右子树与右节点的左子树镜像
1class Solution:
2 def isSymmetric(self, root: TreeNode) -> bool:
3 def helper(l_tree, r_tree):
4 if l_tree and r_tree:
5 return l_tree.val == r_tree.val and helper(l_tree.left, r_tree.right) and helper(l_tree.right, r_tree.left)
6 if not l_tree and not r_tree:
7 return True
8 else:
9 return False
10 if not root: return True
11 return helper(root.left ,root.right)
1class Solution:
2 def isSymmetric(self, root: TreeNode) -> bool:
3 def check(l, r):
4 if l and r and l.val == r.val:
5 return check(l.left, r.right) and check(l.right, r.left)
6 return l == r
7 return check(root, root)
1class Solution:
2 def isSymmetric(self, root: TreeNode) -> bool:
3 nodes,vals = [root], []
4 while nodes:
5 vals = [node.val if node else '' for node in nodes]
6 if vals != vals[::-1]:
7 return False
8 nodes = [n for node in nodes if node for n in [node.left, node.right]]
9 return True
1class Solution:
2 def isSymmetric(self, root: TreeNode) -> bool:
3 def check(p,q):
4 if not p and not q:
5 return True
6 if not p or not q or p.val!=q.val:
7 return False
8 return True
9
10 if not root:
11 return True
12 queue=deque()
13 queue.append((root.left,root.right))
14 while queue:
15 p,q=queue.popleft()
16 if not check(p,q):
17 return False
18 if p:
19 queue.append((p.left,q.right))
20 queue.append((p.right,q.left))
21 return True
一个对称二叉树的判断就有这么多思路,不得不说二叉树的操作实在是太精妙了。
前面提到3种遍历方式会产生不同的遍历结果,那么根据遍历结果也可以反向构建相应的二叉树。这里,要求至少具有中序遍历,外加前序或者后序方可反向构建。否则会存在歧义。
1class Solution:
2 def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
3 def helper(left=0, right=len(inorder)-1):
4 if right<left:
5 return None
6 rootVal = postorder.pop()
7 index = inorder.index(rootVal)
8 root = TreeNode(rootVal)
9 root.right = helper(index+1, right)
10 root.left = helper(left, index-1)
11 return root
12 return helper()
1class Solution:
2 def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
3 maps = {val:index for index, val in enumerate(inorder)}
4 def helper(left=0, right=len(inorder)-1):
5 if right<left:
6 return None
7 rootVal = postorder.pop()
8 index = maps[rootVal]
9 root = TreeNode(rootVal)
10 root.right = helper(index+1, right)
11 root.left = helper(left, index-1)
12 return root
13 return helper()
稍加改写即可实现前序+中序反向构建的写法。
1class Solution:
2 def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
3 if root is None or root==p or root==q:
4 return root
5 left=self.lowestCommonAncestor(root.left,p,q)
6 right=self.lowestCommonAncestor(root.right,p,q)
7 if left==None and right==None:
8 return None
9 elif left!=None and right!=None:
10 return root
11 else:
12 if left==None:
13 return right
14 if right==None:
15 return left
1class Codec:
2 def serialize(self, root):
3 data = []
4 nodes = [root]
5 while nodes:
6 data.append([node.val if node else 'null' for node in nodes])
7 nodes = [n for node in nodes if node for n in [node.left, node.right]]
8 return data
9
10 def deserialize(self, data):
11 root = TreeNode(data[0][0]) if len(data)>1 else None
12 if not root:
13 return root
14 nodes = [root]
15 for vals in data[1:]:
16 for i in range(len(nodes)):
17 nodes[i].left = TreeNode(vals[i*2]) if vals[i*2] != 'null' else None
18 nodes[i].right = TreeNode(vals[i*2+1]) if vals[i*2+1] != 'null' else None
19 nodes = [n for node in nodes for n in [node.left, node.right] if n]
20 return root
看完这些案例,不得不再次惊叹于二叉树操作的精妙,而且这还只是其中的冰山一角而已,其精妙程度还大有潜力空间。
以上是关于总结了一些算法二叉树操作的干货 (附Python代码)的主要内容,如果未能解决你的问题,请参考以下文章