Redis 大数据内存优化 (RoaringBitmap)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 大数据内存优化 (RoaringBitmap)相关的知识,希望对你有一定的参考价值。
参考技术A 最近碰到手机设备匹配的业务, 用户在我司后台可以上传人群包, 里面存放的是设备的MD5标识符; 一个人群包大概有千万级的MD5数据, 与广告请求所携带设备标识进行匹配.尝试插入1kw条数据, key为设备MD5值, value为1, 此时Redis中存在1kw条key-value键值对.
通过 info 指令查看内存占用:
8bit = 1b = 0.001kb
bitmap即位图, 就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。
一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。
场景: 有用户id分别为1, 2, 3, 4, 5, 6, 7, 8的用户, 其中用户2, 5在今日登录, 统计今
日登录用户
采用位图存储: 用户id为偏移量, 可以看做是在位图中的索引, value为true
通过 bitcount 获取登录用户数为2:
测试offset从1-1kw连续整数时候的内存占用:
可以发现内存占用仅为 1.19MB, 1个亿的数据也才12MB, 极大的减少了内存;
由于我们的业务没有如此完美的情况出现, 采用设备MD5的hash做Offset, 不会出现连续正整数的情况;
各常用Hash函数性能对比: https://byvoid.com/zhs/blog/string-hash-compare/
所以我们接下来测试1kw条MD5数据的位图内存占用:
查看Redis内存占用:
问题: 为什么同样1kw的bitmap, MD5数据的Hash占用会比 测试一 的多200倍?
将32位无符号整数按照高16位分桶,即最多可能有216=65536个桶,称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中。也就是说,一个RBM就是很多container的集合。
图中示出了三个container:
1kw条MD5数据的插入:
Redis分片主从哨兵集群,原理详解,集群的配置安装,8大数据类型,springboot整合使用
文章目录
- Redis介绍
- Redis分片
- Redis主从
- Redis哨兵
- Redis集群
- Redis持久化策略
- Redis内存策略
- Redis集群一致性hash数据挂载&特性
- Redis集群常见知识点
- 缓存穿透&缓存击穿&缓存雪崩
- Redis 8大数据类型&命令操作
- Redis单台安装步骤
- Redis分片伪集群安装步骤
- Redis主从->哨兵安装步骤
- Redis伪集群安装步骤
- Redis集群生产环境搭建,动态增删
Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis分片
多台服务器对数据存储,如果其中一台宏机,则整个Redis分片将不能正常的使用.。实现了内存扩容,没有高可用的效果。不推荐使用。
Redis主从
主从模式主机可读可写,从机只读,主机宏机将导致只能读。可以配置1主-2从-3从,第3级的从可以承担RDB持久化压力。不推荐使用。
Redis哨兵
解决主机宏机带来的问题,哨兵用来判断主从宏机状况,主机宏机可以选举出新的主机,让从库与主库同步,通知客户端与主库连接。实现了高可用效果, 没有实现内存数据的扩容。这种方案需要配置哨兵集群,不推荐使用。
执行流程:
1.当哨兵启动时,会动态的监控主机,之后利用PING-PONG 心跳检测机制,检查主机是否正常.
2.哨兵链接主机之后,获取相关的主从的服务信息. 方便以后选举.
3.当哨兵发现主机宕机,之后采用随机算法 选择新的主机. 之后其他节点当新主机的从.
Redis集群
redis集群是最佳使用方案。内存扩容,节点实现高可用。可配置多主多从,实现去中心化。
Redis持久化策略
RDB
RDB模式介绍:
1.RDB模式是Redis默认持久化机制。
2.RDB模式记录的是内存数据的快照,持久化效率更高.。(只会保留当前最新数据)
3.RDB模式是定期持久化. 也可以手动操作 save(同步) 用户操作可能阻塞 /bgsave 后端运行(异步)
4.由于是定期备份,所以可能导致数据丢失。
RDB配置选项解释:
save 900 1 ->900秒 1次更新,则持久化一次
save 300 10 ->300秒 10次更新 则持久化一次
save 60 10000 ->60秒 10000更新 则持久化一次
save 1 1 效率极低. 不要这样配置 压测之后进行适当的调整.
AOF
AOF模式介绍:
1.默认条件下AOF模式处于关闭状态,如果需要开启,则手动配置
2.AOF模式记录用户的操作的过程,可以实现实时的持久化操作, 持久化文件相对较大维护不易.
3.如果同时开启了 RDB与AOF模式,则默认以AOF模式为准.
4.AOF模式是一种异步的操作,不会影响程序的正常使用
5.可以通过修改AOF存储的执行过程的命令达到修改数据的目的
AOF模式持久化策略:
appendfsync always 用户执行一步操作,则持久化一次
appendfsync everysec 每秒持久化一次 性能略低于RDB模式
appendfsync no 不主动持久化
持久化方案选择
1.如果允许少量的数据丢失 首选RDB模式,速度快。
2.如果不允许数据丢失, 首选AOF模式。
3.工作中一般如何选择 主机 选用RDB模式 从机 选用AOF模式。
Redis内存策略
LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 时间T
LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 使用次数
Random算法
随机算法
TTL算法
根据剩余的存活时间,排序,根据时间少的删除数据.
修改内存优化策略
volatile-lru 在设定超时时间的数据中采用LRU算法
allkeys-lru 在所有数据中采用LRU算法
volatile-lfu 在设定了超时时间的数据采用LFU机制进行计算
allkeys-lfu 在所有数据中采用LFU算法
volatile-random 设定超时时间的随机
allkeys-random 所有数据的随机算法
volatile-ttl 在设定了超时时间的数据中,采用TTL算法
noeviction 默认规则 如果内存满了,则不做任何操作 直接报错返回.
Redis集群一致性hash数据挂载&特性
原理:
1.节点计算nodecode=hash(ip:port)
2.计算数据的位置keycode=hash(key)
3.数据挂载图解
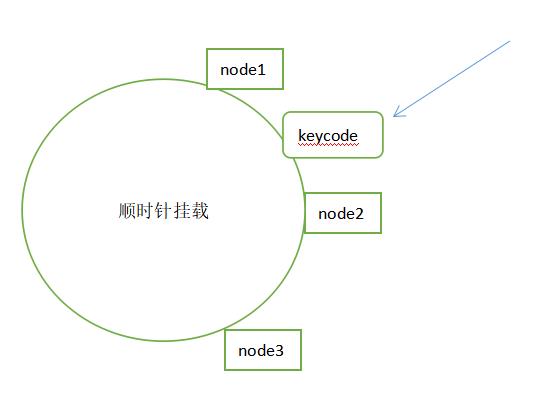
插入数据顺时针挂载到node2上。如果没有虚拟节点,这样存在节点分布不均匀可能导致挂载的数据集中到小部分的节点主机上。
平衡性:
通过虚拟节点实现数据的平衡,挂载虚拟节点使得hash结果均匀分布
单调性:
单调性是指在新增或者删减节点时,不影响系统正常运行
分散性:
分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据
Redis集群常见知识点
1.Redis集群中有16384个槽位,最多能配置16384台主机,hash(key1)%16384。
2.redis-cli -p 命令操作,从机不能写,而且数据存储严格按照分区算法完成。
3.集群的状态都已经写入nodes.conf文件中.所以集群重启之后集群恢复。
4.Redis集群崩溃的条件是主机缺失集群崩溃。(其他主机保证它最少有一台从机前提下,其他主机可以把自己多余的从机给缺少从机的主机)
如果有1主1从共3组组成了redis集群. 问题: redis节点至少宕机几台.集群崩溃?? 2台
如果有1主2从共3组组成了redis集群. 问题: redis节点至少宕机几台.集群崩溃?? 5台
缓存穿透&缓存击穿&缓存雪崩
缓存穿透:
在高并发环境下,用户长时间访问数据库中不存在的数据,称之为缓存穿透。
解决方案:
1.IP限流 单位时间内设定IP的请求的次数。
2.布隆过滤器。(需要了解自行搜索)
缓存击穿:
由于某个热点数据在缓存中失效.导致大量的用户直接访问数据库.导致数据库宕机。
缓存雪崩:
由于大量的数据在缓存中失效.导致用户访问缓存的命中率低.直接导致用户访问数据库。
Redis 8大数据类型&命令操作
String(字符串)
List(列表)
Set (集合)
Hash(哈希)
zset (有序集合)
geospatial(地理位置)
hyperloglog
bitmap(位图)
https://blog.csdn.net/UnicornRe/article/details/117572541
Redis单台安装步骤
1.上传安装包到linux目录/home/app/里
2.解压安装包
tar -xvf redis-5.0.4.tar.gz

3.为方便使用把解压后的redis-5.0.4改名为redis
mv redis-5.0.4 redis
4.安装redis,跳入到redis根目录中顺序执行
(1):make
(2):make install

5.修改redis配置文件
vim redis.conf
进入编辑页面后修改
(1)将IP绑定注释

(2)关闭保护模式

(3)开启后台启动
6.启动关闭命令
(1)启动命令 redis-server redis.conf
(2)查看进程 ps -ef |grep redis
(3)进入客户端 redis-cli -p 6379
(4)关闭命令 redis-cli -p 6379 shutdown
Springboot整合Redis单台
1.maven依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
2.在工程目录resource目录下创建redis.properties文件
文件内容
redis.host=192.168.126.129
redis.port=6379
3.编写配置类
@Configuration
@PropertySource("classpath:/reids.properties")
public class RedisConfigure
@Value("$redis.host")
private String host;
@Value("$redis.port")
private int port;
@Bean
public Jedis jedis()
return new Jedis(host,port);
常用方法示例
//如果数据存在 不做任何操作,如果数据不存在则赋值
@Test
public void test0()
//也可以注入jedis
//Jedis jedis = new Jedis("192.168.126.129", 6379);
//jedis.flushAll();
//jedis.set("redis", "AAA");
jedis.setnx("redis","BBB");
System.out.println(jedis.get("redis"));
Redis分片伪集群安装步骤
安装三台分片
1.同单台开头类似
2.在redis目录下创建文件夹shards
mkdir shards
cp redis.conf shards/6379.conf
cp redis.conf shards/6380.conf
cp redis.conf shards/6381.conf
分别vim 6380.conf,6381.conf
分别修改对应端口号6380和6381
启动多台redis,进入shards目录下
redis-server 6379.conf
redis-server 6380.conf
redis-server 6381.conf
查看进程
ps -ef |grep redis
Springboot整合Redis分片
在工程目录resource目录下创建redis.properties文件
文件内容
redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
编写配置类
@Configuration
@PropertySource("classpath:/reids.properties")
public class RedisConfigure
@Value("$redis.nodes")
private String nodes;//指定分片节点 node,node,node
@Bean
public ShardedJedis shardedJedis()
List<JedisShardInfo> shardInfos=new ArrayList<>();
String[] nodeArray=nodes.split(",");
for (String node:nodeArray)
String[] s=node.split(":");//host:port
JedisShardInfo jedisShardInfo=new JedisShardInfo(s[0],Integer.parseInt(s[1]));
shardInfos.add(jedisShardInfo);
return new ShardedJedis(shardInfos);
Redis主从->哨兵安装步骤
前提:要保证集群数据一致,如果有dump.rdb,appendonly.aof文件需要先删除,通常这些文件会在要启动的配置文件xxx.conf同目录下
先将分片实现主从挂载
1.同单台开头类似
2.在redis目录下创建sentinel文件夹
mkdir sentinel
cp redis.conf sentinel/6379.conf
cp redis.conf sentinel/6380.conf
cp redis.conf sentinel/6381.conf
启动多台redis,进入sentinel目录下
redis-server 6379.conf
redis-server 6380.conf
redis-server 6381.conf
3.实现主从挂载
主机: 6379
从机: 6380/6381
主从挂载步骤
(1)进入6380客户端 redis-cli -p 6380
(2)执行slaveof 192.168.126.131 6379 (语法:slaveof ip port)
(3)查看主从关系 info replication (role:slave自己为奴隶从)
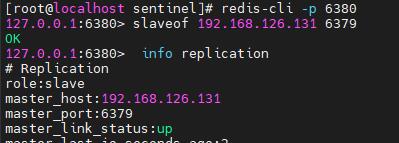
(4)把6381也挂到6379的从,同理步骤执行即可
(5)进入6379客户端 redis-cli -p 6379 查看主从关系info replication
主从总体和分片比较相似,只是多了主从挂载
接下来安装哨兵,哨兵用来管理主机选举新主机
1.复制文件,在redis目录下
cp sentinel.conf sentinel
2.修改哨兵配置文件
进入sentinel目录
vim sentinel.conf
关闭保护模式
开启后台启动
监控主机(主机ip 主机端口 哨兵选举票数)

设定哨兵选举的时间

3.启动哨兵
redis-sentinel sentinel.conf
查看

现在可以关闭redis主机6379(强杀kill -9 39829),一段时间(上面配置了30s)后哨兵会选举新的从机当主机。
Springboot整合Redis哨兵
在工程目录resource目录下创建redis.properties文件
文件内容(地址端口皆为哨兵而不是主机)
redis.sentinel=192.168.126.129:26379
配置类
@Configuration
@PropertySource("classpath:/reids.properties")
public class RedisConfigure
@Value("$redis.sentinel")
private String sentinel;
@Bean
public JedisSentinelPool jedisSentinelPool()
//1.设定连接池大小
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMinIdle(5); //设定最小的空闲数量
poolConfig.setMaxIdle(10); //设定最大空闲数量
poolConfig.setMaxTotal(100); //最大链接数
//2.链接哨兵的集合,上面只安装了单台哨兵
Set<String> sentinels = new HashSet<>();
sentinels.add(sentinel);
return new JedisSentinelPool("mymaster",sentinels,poolConfig);
//使用
Jedis jedis = jedisSentinelPool.getResource();
Redis伪集群安装步骤
搭建三主三从
1.与单台安装类似
2.在redis目录下创建文件夹cluster
mkdir cluster
3.在cluster文件夹中分别创建7000-7005文件夹
mkdir 7000 7001 7002 7003 7004 7005
4.复制配置文件
将redis根目录中的redis.conf文件复制到cluster/7000/ 并以原名保存
cp redis.conf cluster/7000/
先修改7000目录下的配置文件
注释本地绑定IP地址(69行)
关闭保护模式(88行)
开启后台启动 (136行)
修改端口号(92行)
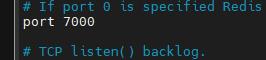
修改pid文件(存储进程号)(158行)

修改持久化文件路径(rdb,aof存储文件都在这个目录)(263行)

设定内存优化策略,其他类型选择上述文章有解释(597行)

关闭AOF模式(699行)
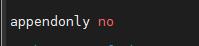
开启集群配置(838行)
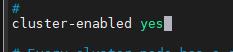
开启集群配置文件(846行)

修改集群超时时间(852行)
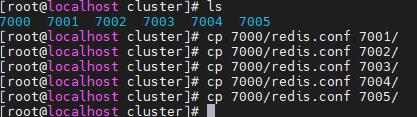
将7000文件夹下的redis.conf文件分别复制到7001-7005中
批量修改,把复制过来的配置文件的7000端口改成自己响应的端口(92行,158行,263行)
5.在cluster目录下创建启动脚本
vim start.sh
#!/bin/sh
redis-server 7000/redis.conf &
redis-server 7001/redis.conf &
redis-server 7002/redis.conf &
redis-server 7003/redis.conf &
redis-server 7004/redis.conf &
redis-server 7005/redis.conf &
同理也可以创建关闭脚本(自行操作)
在cluster目录下运行脚本
sh start.sh
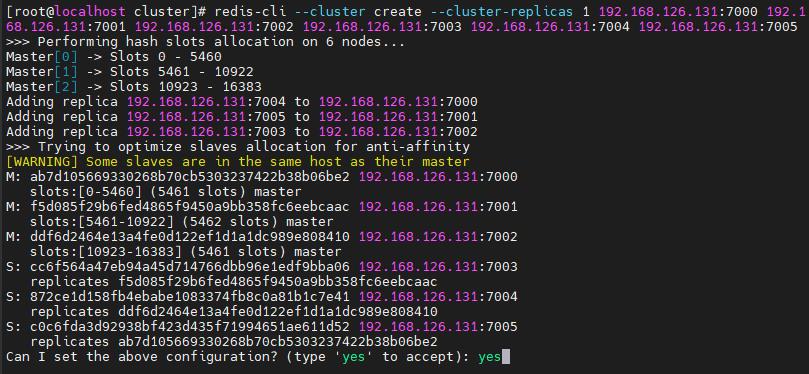
6.创建redis集群
#5.0版本执行 使用C语言内部管理集群,执行命令
redis-cli --cluster create --cluster-replicas 1 192.168.126.131:7000 192.168.126.131:7001 192.168.126.131:7002 192.168.126.131:7003 192.168.126.131:7004 192.168.126.131:7005
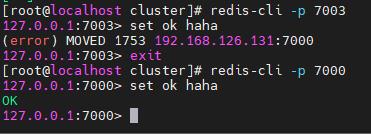
从机只能读不可写,key的hashcode%16384顺时针顺序和虚拟节点推算得到特定的主机,这个特定主机才能写这个key,比如set ok haha里的key是ok,计算出在7000主机,这个命令只能在7000主机写,其他主机写会报错
Springboot整合Redis集群
在工程目录resource目录下创建redis.properties文件
文件内容(地址端口皆为哨兵而不是主机)
(以下ip未与上述配置一致,一切按照实际情况配置)
redis.nodes=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
配置类
@Configuration
@PropertySource("classpath:/reids.properties")
public class RedisConfigure
@Value("$redis.nodes")
private String nodes;
@Bean
public JedisCluster jedisCluster()
Set<HostAndPort> set=new HashSet<>();
String [] nodeArray=nodes.split(",");
for (String node:nodeArray)
String host=node.split(":")[0];
int port=Integer.parseInt(node.split(":")[1]);
set.add(new HostAndPort(host,port ));
JedisCluster jedisCluster=new JedisCluster(set);
return jedisCluster;
Redis集群生产环境搭建,动态增删
https://blog.csdn.net/UnicornRe/article/details/117571609
 CSDN 社区图书馆,开张营业!
CSDN 社区图书馆,开张营业!
 深读计划,写书评领图书福利~
深读计划,写书评领图书福利~
以上是关于Redis 大数据内存优化 (RoaringBitmap)的主要内容,如果未能解决你的问题,请参考以下文章