机器学习课后作业求解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习课后作业求解相关的知识,希望对你有一定的参考价值。
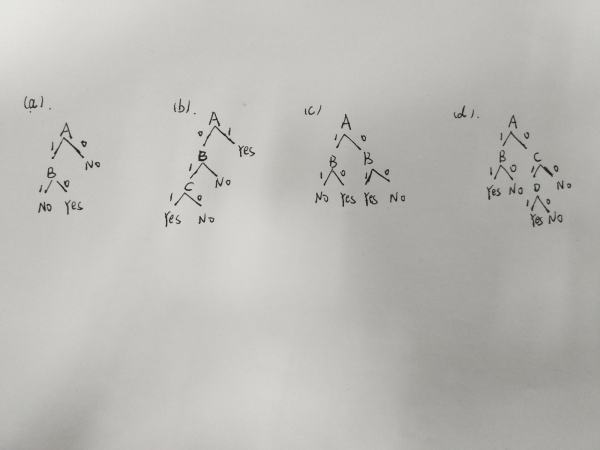
3.1 画出表示下面布尔函数的决策树:
(a)A^¬B
(b)A^[B^C]
(c)A XOR B
(d)[A^B] V [C^D]
3.2 考虑下面的训练样例集合:
实例 分类 a1 a2
1 + T T
2 + T T
3 - T F
4 + F F
5 - F T
6 - F T
(a)请计算这个训练样例集合对于目标函数分类的熵。
(b)请计算属性a2相对这些训练样例的信息增益。
高分悬赏哇,满意答案再追加50分

对于第一题 我举一个另外的例子
如图:
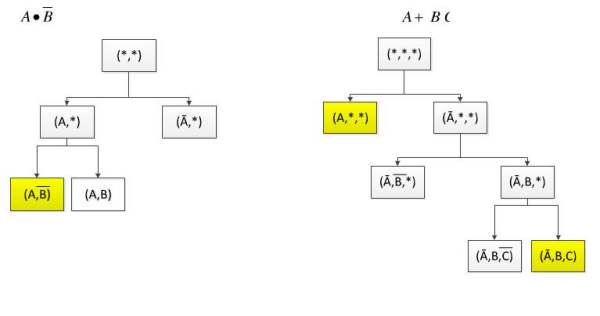
第一题是不是这样的呢 有待探讨,我原本是先列出所有的样例,然后求属性的信息增益,但是感觉很计算复杂,也分不出,望高手指点~
对于第二题,
1)第一问就是直接求熵:
3个正例,3个反例 根据公式 Entropy(S)=-3/6log2(3/6)-3/6log2(3/6) 具体得多少 自己算
2)第二问 求a2的信息增益:
分别求当a2=T和a2=F的熵
Entropy(S,a2=T)=1 (因为当a2=T时候,分类刚好一半,样例1,2,5,6 刚好两个正两个反!!,熵为1)
Entropr(S,a2=F)=1(a2=F时候,分类也是一半,样例3,4 刚好一正,一反)
所以a2的信息增益:
Gain(S,a2)=Entropy(S)-4/6Entropy(S,a2=T)-2/6Entropr(S,a2=F) 课本公式!!
以上有错望大神修正~~
参考技术A第一题:
求a2的信息增益结果是0 参考技术C kldsrjtierngieojwhtui 参考技术D 完任何
课程作业西瓜书 机器学习课后习题 : 第二章
目录

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
本文仅记录自己感兴趣的内容
说明
作业要求:每章从课后习题中选取3道题做就可以了
答案来源:题目的解答过程来自于网络,依据个人所学进行了一些修改、总结
仅供参考
2.1
数据集包含1000个样本,其中500个正例、500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
- 题目分析:根据题意,我们需要划分出350个正例和反例作为样本的训练集,150个正例和反例作为样本的测试集,因此该题是一个典型的排列组合问题。
- 答案:

2.2
数据集包含100个样本,其中正、反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
- 知识点:
十折交叉验证,英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。
留一法,假定数据集D中包含m个样本,若令k=m,则得到了交叉验证法的一个特例:留一法(Leave-One-Out,简称LOO)。显然,留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分为m个子集——每个子集包含一个样本;留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D训练出的模型很相似。因此,留一法的评估结果往往被认为比较准确。然而,留一法也有其缺陷:在数据集比较大时,训练m个模型的计算开销可能是难以忍受的(例如数据集包含1百万个样本,则需训练1百万个模型),而这还是在未考虑算法调参的情况下。另外,留一法的估计结果也未必永远比其他评估方法准确;“没有免费的午餐”定理对实验评估方法同样适用。
- 答案:
十折交叉验证:10折交叉验证时,每个训练集应该有45正例、45反例,验证集应该有5正例、5反例,由于训练集中正例、反例比例为1:1,则按照题目的预测算法,预测时会进行随机预测(因为训练样本数比例相同),所以错误率的期望为50%
留一法:留下来做验证集的样本有两种情况:正例、反例。当留下来的是正例时,训练集中反例比正例多一个,按照题目的算法会将验证集预测为反例,预测错误;留下来的是反例时同理,会将验证集预测为正例。所以错误率的期望为100%
2.3
若学习器A的 F 1 F_1 F1值比学习器B高,试分析A的BEP值是否也比B高。(不确定)
- 知识点:

参考https://www.jianshu.com/p/9d70c26b73a2
2.4
试述真正例率(TPR)、假正利率(FPR)与查准率(P)、查全率(R)之间的联系。
- 知识点:
分类结果混淆矩阵如下

分类结果混淆矩阵
- 分析:

结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

以上是关于机器学习课后作业求解的主要内容,如果未能解决你的问题,请参考以下文章