Windows 记事本的 ANSI,Unicode,UTF-8 这三种编码模式有啥区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Windows 记事本的 ANSI,Unicode,UTF-8 这三种编码模式有啥区别相关的知识,希望对你有一定的参考价值。
ANSI通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。Unicode字符分为17组编排, UTF-8用1到6个字节编码UNICODE字符。
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。表示英文字符时用一个字节,表示中文用两个或四个字节。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。
UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
参考技术AANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。表示英文字符时用一个字节,表示中文用两个或四个字节。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的 Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每 平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF- 16、UTF-32都是将数字转换到程序数据的编码方案。
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称 ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字 节编码。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。
UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁 体及其它语言(如英文,日文,韩文)。
如果是为了跨平台兼容性,只需要知道,在 Windows 记事本的语境中:
所谓的「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码。[1]
所谓的「Unicode」指的是带有 BOM 的小端序 UTF-16。[2]
所谓的「UTF-8」指的是带 BOM 的 UTF-8。[3]
GBK 等遗留编码最麻烦,所以除非你知道自己在干什么否则不要再用了。
UTF-16 理论上其实很好,字节序也标明了,但 UTF-16 毕竟不常用。
UTF-8 本来是兼容性最好的编码但 Windows 偏要加 BOM 于是经常出问题。
所以,跨平台兼容性最好的其实就是不用记事本。
建议用 Notepad++ 等正常的专业文本编辑器保存为不带 BOM 的 UTF-8。
另外,如果文本中所有字符都在 ASCII 范围内,那么其实,记事本保存的所谓的「ANSI」文件,和 ASCII 或无 BOM 的 UTF-8 是一样的。 参考技术C ASCII是古老的编码,那个时候还不区分字符集和编码,基本可以看作合二为一的东西。
Unicode严格来说是字符集,可以有多种编码。
UTF-8是一种Unicode的编码。
兼容性最好的,我记得好像是UTF-8不带BOM头。
注: 字符集(char set)就是字符的集合,收录了一定数量的字符。每个字符有对应的ID值,叫码点(code point)。实际存储的时候,不一定是直接存储字符串的码点(比如,为了节约空间),要进行转换。这个转换规则就是编码。本回答被提问者采纳
txt中的Unicode
我用汉王PDF OCR转换了一个txt文档,但我的电子词典不支持编码它的格式。
当我用记事本另存为,编码格式选择了ANSI,可是仍然有错误提示,如附图所示。若点击确定会丢失文本内容吗?
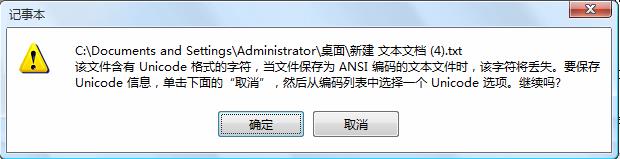
您可以用保存为utf-8或unicode格式
文件==>另存为==>编码选择 utf-8==>保存 参考技术A 应该是你的OCR识别之后有一些内容本来是正常的文字的,但被识别成了特殊的字符,反正这些字符你也看不懂是什么,转换成哪种编码的效果都差不多。 参考技术B 会,因为unicode范围超过ascii编码范围,会造成丢失。 参考技术C 这个问题我也不知道 我也想知道答案 希望高手指点一下
我在保存文件的时候 尤其是TXT格式的 有时候保存到什么字符之类的就会出现关于Unicode相关的信息
我想知道 什么样的数据是Unicode的呀 希望高手指点一二!!太谢谢了 !!
以上是关于Windows 记事本的 ANSI,Unicode,UTF-8 这三种编码模式有啥区别的主要内容,如果未能解决你的问题,请参考以下文章
求vc中ansi或unicode转utf8的函数,要求记事本验证通过的?
记事本里出现该文件含有Unicode格式的字符,当保存为ANSI编码的文本时,该字符将丢失。怎么回事啊??