大厂面试不可不会的二叉树相关算法
Posted 技术秘宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大厂面试不可不会的二叉树相关算法相关的知识,希望对你有一定的参考价值。
大厂面试是少不了算法大关的,虽然寸山有个大厂梦,但是总是事与愿违啊,寸山现在正在努力中,希望可以在有生之年,实现个人大厂梦,为中国梦添砖添瓦。
其实在笔试过程中用到二叉树的并不多,尤其是在一些大厂的笔试基本很难碰到二叉树的相关问题,多以分治思想、动态规划、递归、回溯为主(虽然二叉树的算法很多也是递归、回溯来结题的,但是笔试中不太好出题,所以出现的较少,但是不一定就不会出哈,小概率事件也会发生的)但是在面试过程中二叉树的相关算法,会经常被问到,因此,今天寸山就来带大家学习几个二叉树相关的算法。
在开始前先给出节点类的代码:
public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) { this.val = val; }TreeNode(int val, TreeNode left, TreeNode right) {this.val = val;this.left = left;this.right = right;}}
二叉树前序遍历-力扣URL:https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
二叉树的前序遍历,就是按照 根->左子节点->右子节点 的规则遍历整棵二叉树。
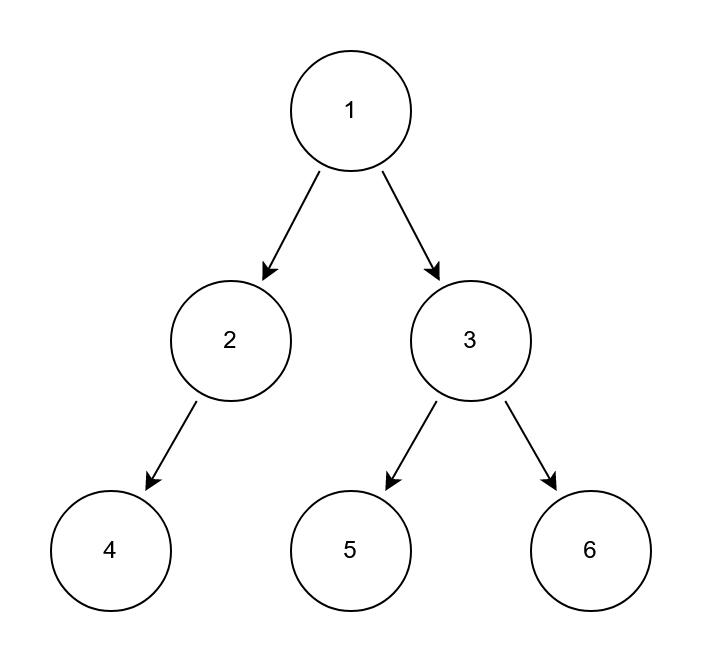
图一、一颗二叉树
如上图,用前序遍历的结果就是 1->2->4->3->5->6;
题目:给你二叉树的根节点 root ,返回该节点值的前序遍历
示例1:
输入:root = [1,2,4,null,3,5,6]
输出:[1,2,4,3,5,6]
示例2:
输入:root=[1,null,2,3]
输出:[1,2,3]
1.1 方法一:递归遍历
利用函数递归的方法来解题: 时间复杂度为:O(n) 每个节点都要遍历一次
空间复杂度为:O(n) 因为每次调用都需要在虚拟机栈中开辟一个栈帧,当有n个节点时,平均开辟logn个栈帧,最坏情况就是二叉树退化成链表形式。需要开辟n个栈帧
class Solution {public List<Integer> preorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();preorder(root,ans);return ans;}public void preorder(TreeNode root,ArrayList<Integer> ans){//1. 递归终止条件if(root==null) return;//2. 将根节点元素的值添加进入链表中ans.add(root.val);//3. 递归遍历左子节点preorder(root.left,ans);//4. 递归遍历右子节点preorder(root.right,ans);}}
1.2 方法一:递归遍历(另一种方式)
第一种形式的递归遍历,是分成了两个函数,将遍历算法抽出来,形成一个函数用来递归使用。我们也可以用List集合的addAll方法,将递归以别的形式进行。
递归方式 时间复杂度 O(n),每个节点都要遍历一遍 空间复杂度O(n),递归调用栈帧用到的空间,需要递归n次
class Solution {public List<Integer> preorderTraversal(TreeNode root) {//用来存放结果ArrayList<Integer> ans = new ArrayList<>();//递归结束条件if(root == null)return ans;//前序遍历,先将根节点加入到链表中ans.add(root.val);//遍历所有的左子节点,并将其装入到集合中ans.addAll(preorderTraversal(root.left));//遍历所有的右子节点,并将其装入到集合中ans.addAll(preorderTraversal(root.right));//返回前序遍历结果return ans;}}
1.3 方法二:非递归遍历(借用数据结构——栈)
该方法就是由双层while循环,外层循环主要是出栈后,遍历右子节点是否还存在左子节点的。内存while循环则从root节点不停的寻找左子节点,如果左子节点不为空,则将其加入到栈(先进后出的特性)中存储并将节点值存入链表中,直到到达左叶子节点,然后进入外部循环从栈中弹出一个节点元素,让root为弹出节点的右子节点(因为左子节点在上次内循环中已经处理过来了),继续重复双层循环的操作,直到不满足要求为止。
非递归方法——主要运用栈来存储中间节点
时间复杂度为O(n)每个元素都要遍历一遍
时间复杂度为O(n) 平均情况下为O(logn),因为只用存储左子节点到栈中,最坏情况(二叉树链表化时)为O(n),
递归方式其实就是隐式使用一个栈结构,而非递归方式则是显示使用一个栈结构
class Solution {public List<Integer> preorderTraversal(TreeNode root) {//存放结果ArrayList<Integer> ans = new ArrayList<>();//存放中间节点(所有的左子节点)Deque<TreeNode> stack = new ArrayDeque<>();//1. 当root不为空 or 栈不为空while(root!=null||!stack.isEmpty()){//2. 找到某个节点为跟的路径的所有左子节点,并将节点值添加到链表中while(root!=null){ans.add(root.val);stack.addLast(root);root = root.left;}//3. 从栈弹出一个节点,让root赋值为该节点的右子节点TreeNode node = stack.pollLast();root = node.right;}//4. 返回结果链表return ans;}}
非递归的遍历顺序如下图所示:
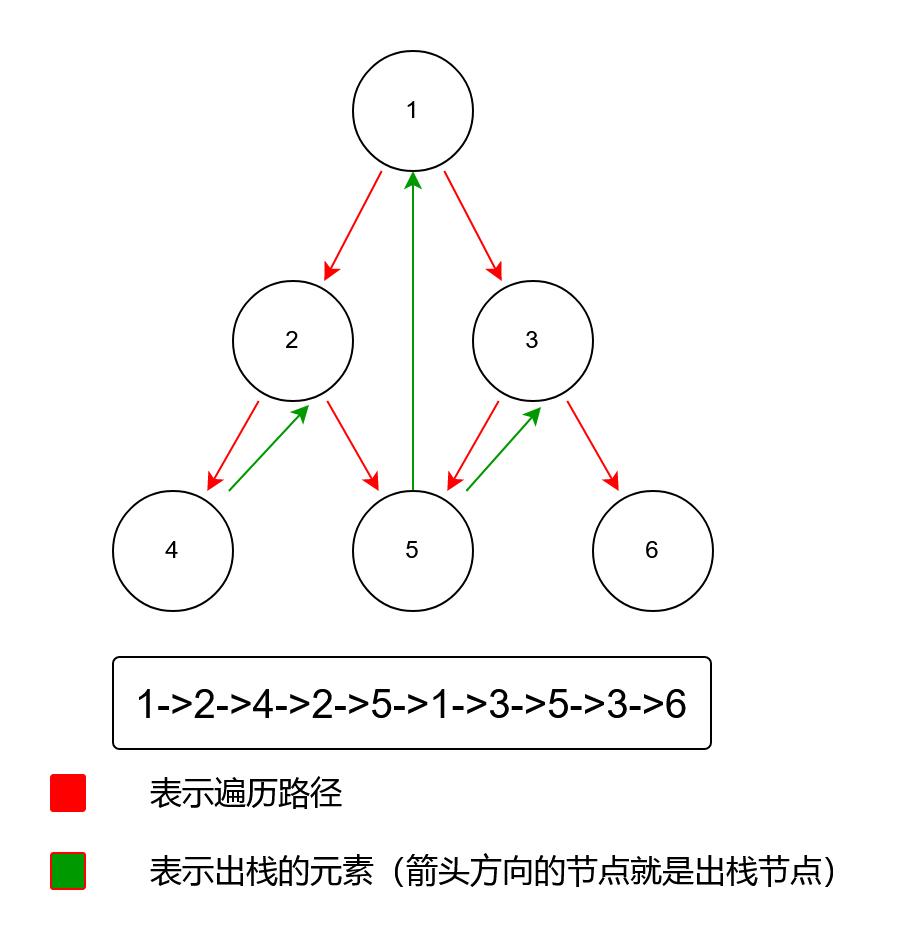

前序遍历非递归方式即迭代法,其实就是不断从根节点遍历,找到左子节点,并将其节点的val值加入到ans链表中。当循环遍历到第一个左子叶节点后,(1)开始弹出栈顶节点,并检查其有无右子节点,如果存在,则将root赋值为其右子节点并遍历其右子节点所在支路是否存在左子节点,存在则入栈,继续找到下一个左子叶节点之后,再弹出栈顶节点。若不存在,继续(1)处的操作。直到当前root为空,且stack栈为空为止,则说明迭代完毕,ans中就存储了前序遍历的结果。
中序遍历和后序遍历的迭代法与前序大同小异,只是由于遍历时顺序不同,因此,需要调整某部分的代码,但是主要思路,还是相同的。

上面我们讲了二叉树前序遍历分别用了递归和非递归的方式。那么我们接下来看看如何进行二叉树的中序遍历。中序遍历的顺序是 左子节点->根节点->右子节点。在搜索二叉树中,由于规定了 左子节点≤父节点≤右子节点,因此,按照中序遍历则可以得到一组升序的节点访问顺序。
二叉树中序遍历-力扣URL:https://leetcode-cn.com/problems/binary-tree-inorder-traversal/
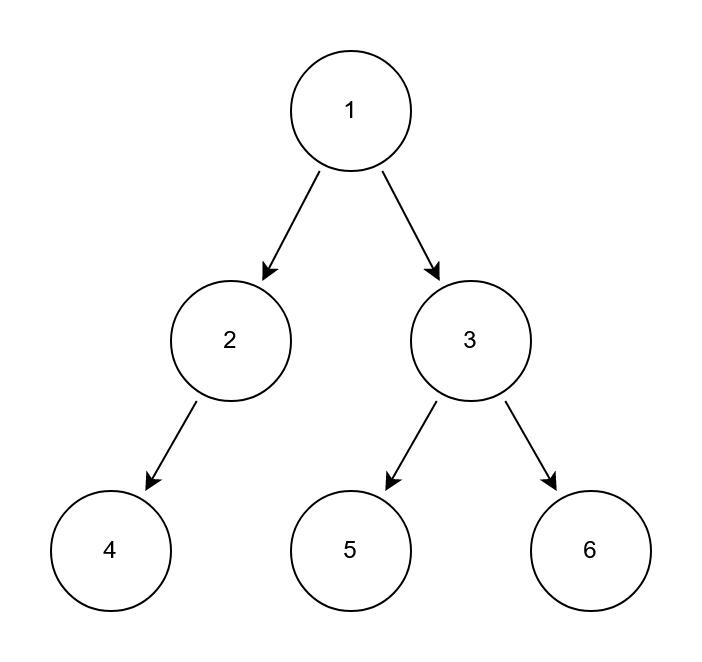
我们还是以前序遍历的案例来举例说明中序遍历
用中序遍历则是:4->2->1->5->3->6
题目:给你二叉树的根节点 root ,返回该节点值的中序遍历
示例1:
输入:root = [1,2,4,null,3,5,6]
输出:[2,3,11,5,4,6]
示例2:
输入:root=[1,null,2,3]
输出:[1,3,2]
2.1 方法一:递归遍历
我们使用递归方法,来中序遍历二叉树。结构其实和前序基本一样,只是其中遍历节点的顺序不一样罢了。在强调下,前序:根节点->左子节点->右子节点,中序:左子节点->根节点->右子节点。
递归方法
时间复杂度O(n),每个节点遍历一遍
空间复杂度O(n),调用递归方法时,虚拟机需要创建一个栈帧,因此时间复杂度为O(n)
class Solution {public List<Integer> inorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();inorder(root,ans);return ans;}public void inorder(TreeNode root,ArrayList<Integer> ans){if(root == null)return;//1. 递归遍历左子节点inorder(root.left,ans);//2. 再遍历根节点ans.add(root.val);//3. 最后遍历右子节点inorder(root.right,ans);}}
2.2 方法一:递归遍历(另一种方式)
也和前序相同只是,遍历顺序不同罢了。
class Solution {public List<Integer> inorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();//递归终止条件if(root == null)return ans;//1. 容器中装入所有左子节点,并将左子节点加入到ans中ans.addAll(inorderTraversal(root.left));//2. 遍历添加根节点ans.add(root.val);//3. 容器中装入所有右子节点,并将右子节点加入到ans中ans.addAll(inorderTraversal(root.right));//返回最后结果return ans;}}
2.3 方法二:非递归遍历(借用数据结构——栈)
非递归也和前序大同小异,所以寸山觉得掌握一种顺序的递归和非递归,其实其他的就好理解了。下面我们来看看如何非递归遍历。
class Solution {public List<Integer> inorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();Deque<TreeNode> stack = new ArrayDeque<>();//1. 当root不为空 or 链表不为空时才可进入while循环while(root!=null||!stack.isEmpty()){//2. 当root不为空时,进入循环不断寻找某枝节上的左子节点while(root!=null){stack.add(root);root = root.left;}//3. 弹出栈顶元素root = stack.pollLast();//4. 将其加入到ans链表中ans.add(root.val);//5. 遍历弹出节点的右分支root = root.right;}return ans;}}
代码3处,其实就是弹出第一个左子叶节点,它没有子节点,因此其右子节点必定为空,然后再次从栈中弹出栈顶节点,该节点为上次左子节点的根节点,然后在遍历根节点的右子节点所在的分支就这样一直下去。
具体路径如下图:
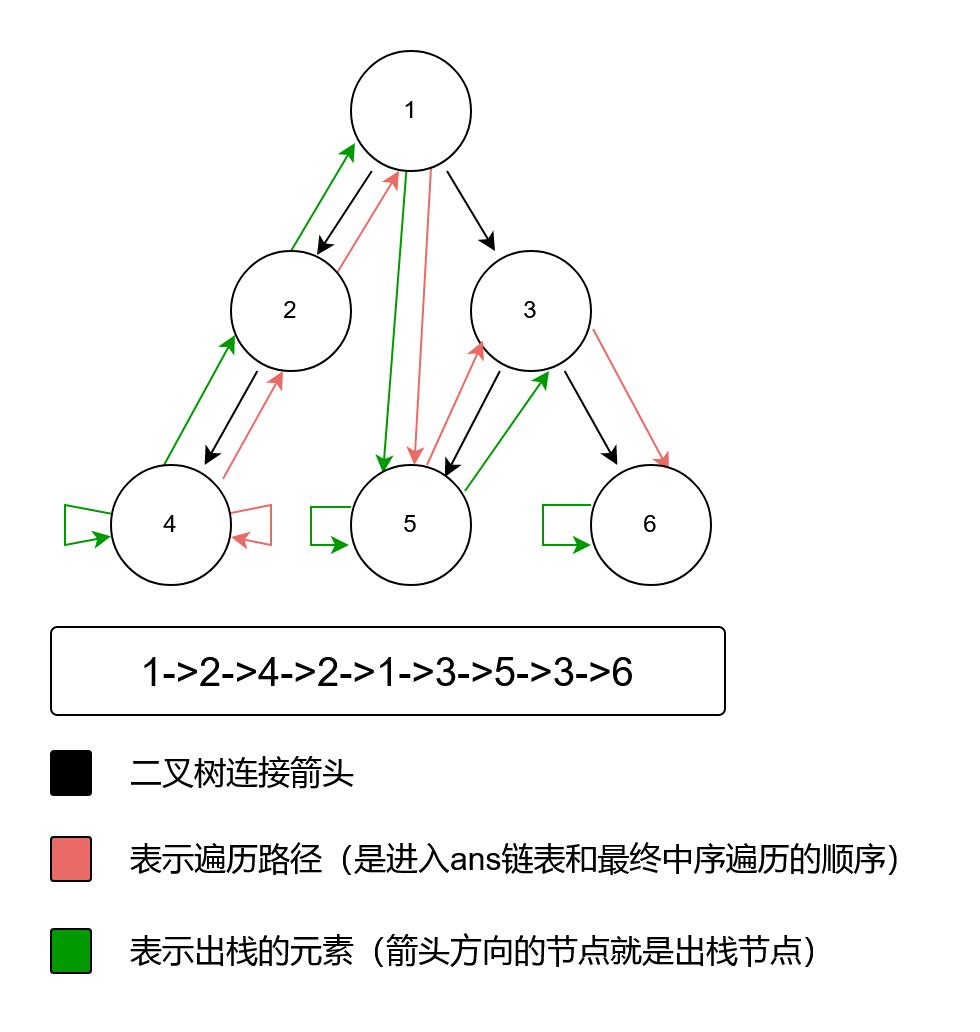
介绍完前序、中序、后序遍历也不能少啊,对吧,后序的遍历访问顺序:左子节点->右子节点->根节点。
后序遍历-力扣URL:https://leetcode-cn.com/problems/binary-tree-postorder-traversal/submissions/
我们用万年例子给大家举例后序遍历:
后序遍历的结果是:4->2->5->6->3->1.
题目:给你二叉树的根节点 root ,返回该节点值的后序遍历
示例1:
输入:root = [1,2,4,null,3,5,6]
输出:[3,2,5,6,4,1]
示例2:
输入:root=[1,null,2,3]
输出:[3,2,1]
3.1 方法一:递归遍历
后序遍历的顺序:左子节点->右子节点->根节点。
class Solution {public List<Integer> postorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();posorder(root,ans);return ans;}public void posorder(TreeNode root,ArrayList<Integer> ans){//1. 递归终止条件if(root == null)return;//2. 先遍历左子节点posorder(root.left,ans);//3. 再遍历右子节点posorder(root.right,ans);//4. 最后遍历根节点ans.add(root.val);}}
3.2 方法一:递归遍历(另一种方式)
后序遍历——另一种递归方式
时间复杂度O(n)
空间复杂度O(n)
class Solution {public List<Integer> postorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();//递归终止条件if(root == null)return ans;//1. 将左子节点全部装入到集合中,遍历左子节点并将左子节点的val加入到ans链表中ans.addAll(postorderTraversal(root.left));//2. 将右子节点全部装入到集合中,遍历右子节点并将右子节点的val加入到ans链表中ans.addAll(postorderTraversal(root.right));//3. 遍历根节点ans.add(root.val);//4. 返回ans链表return ans;}}
3.3 方法二:非递归遍历(借用数据结构——栈)
后序遍历的非递归遍历其实会比前序和中序麻烦一些,就是因为前、中的遍历都是根节点优先于右子节点先被遍历的,因此,比较好处理,但是我们会发现,后序遍历则是右子节点优先于根节点被遍历的,因此,稍微麻烦了一些。
前序和中序,基本就是在找寻左子节点或者在出栈后就添加节点元素的val值进入ans链表中了,但是后序不是,后序还需要做特殊的判断才可以。
后序遍历-非递归方法(迭代方法)
时间复杂度O(n),每个节点遍历一次
空间复杂度O(n),每个节点都会入栈一次
class Solution {public List<Integer> postorderTraversal(TreeNode root) {ArrayList<Integer> ans = new ArrayList<>();Deque<TreeNode> stack = new ArrayDeque<>();//保存上次的root节点,用来判断右子节点是否被遍历了TreeNode prev = null;//1. 当root不为空 or 栈不为空进入循环while(root!=null || !stack.isEmpty()){//2. 迭代的通式,先找到root节点对应的左子叶节点while(root!=null){//将每次的左子节点存入栈中stack.addLast(root);root = root.left;}//3. 弹出栈顶节点root = stack.pollLast();//4. 当root.right为空表示当前根节点的右节点是空的,可以直接将其加入到ans链表中,并将prev赋值为当前的root//当root.right == prev时,表示前面我们已经遍历过当前根节点的右子节点了,因此,只需将当前节点加入ans链表即可if(root.right==null || root.right==prev){ans.add(root.val);prev = root;root = null;//5. 否则,说明当前root节点的右子节点存在且还没有被遍历}else{//先将根节点加回到栈中stack.addLast(root);//然后遍历右子节点所在的分支root = root.right;}}//6. 返回ans链表return ans;}}
代码4处,其实就是在两种情况下才会把节点加入到ans链表中。
第一种就是当前节点的右子节点不存在,那就不需要遍历右节点了,直接将弹出的根节点再次加入到链表中就可以了。如下图所示:
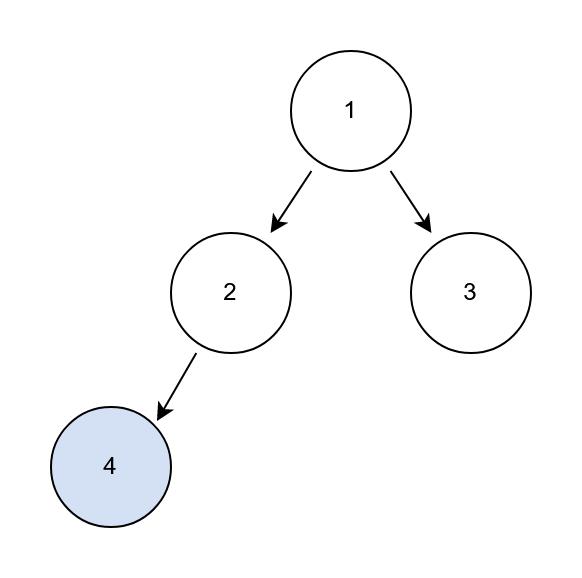
蓝色节点,就是左子叶节点,而其父节点2,没有右子节点,当我们将节点4,加入到ans后,弹出节点2,而节点2,的right节点为null,因此,就直接将节点2也加入到ans链表中了。
另一种情况则是,当我们第一次弹出父节点时,如果它存在右子节点,则将其再次加入stack栈中,先遍历其右子节点,遍历完后,再次将这个根节点从栈中弹出,此时它的右子节点不为空,但是prev是它的右子节点,证明它的右子节点已经遍历过了。因此,当前节点可以被加入到ans中。如下图:
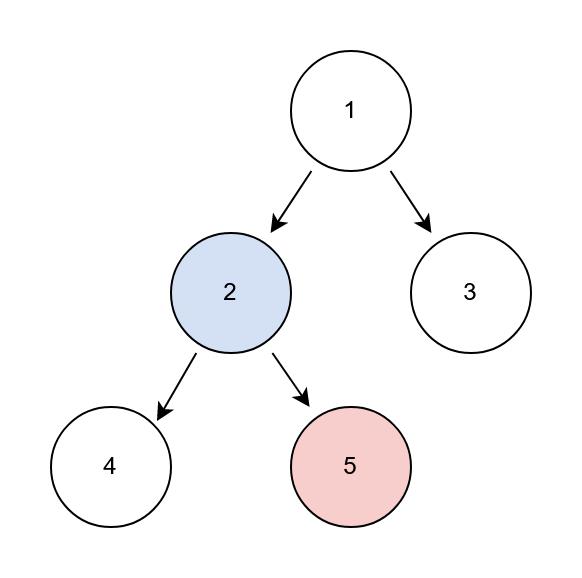
当右子节点5已经遍历完后,再次从栈中弹出的父节点2,它的右子节点已经遍历完成,此时,父节点2则可以被加入到ans链表中。
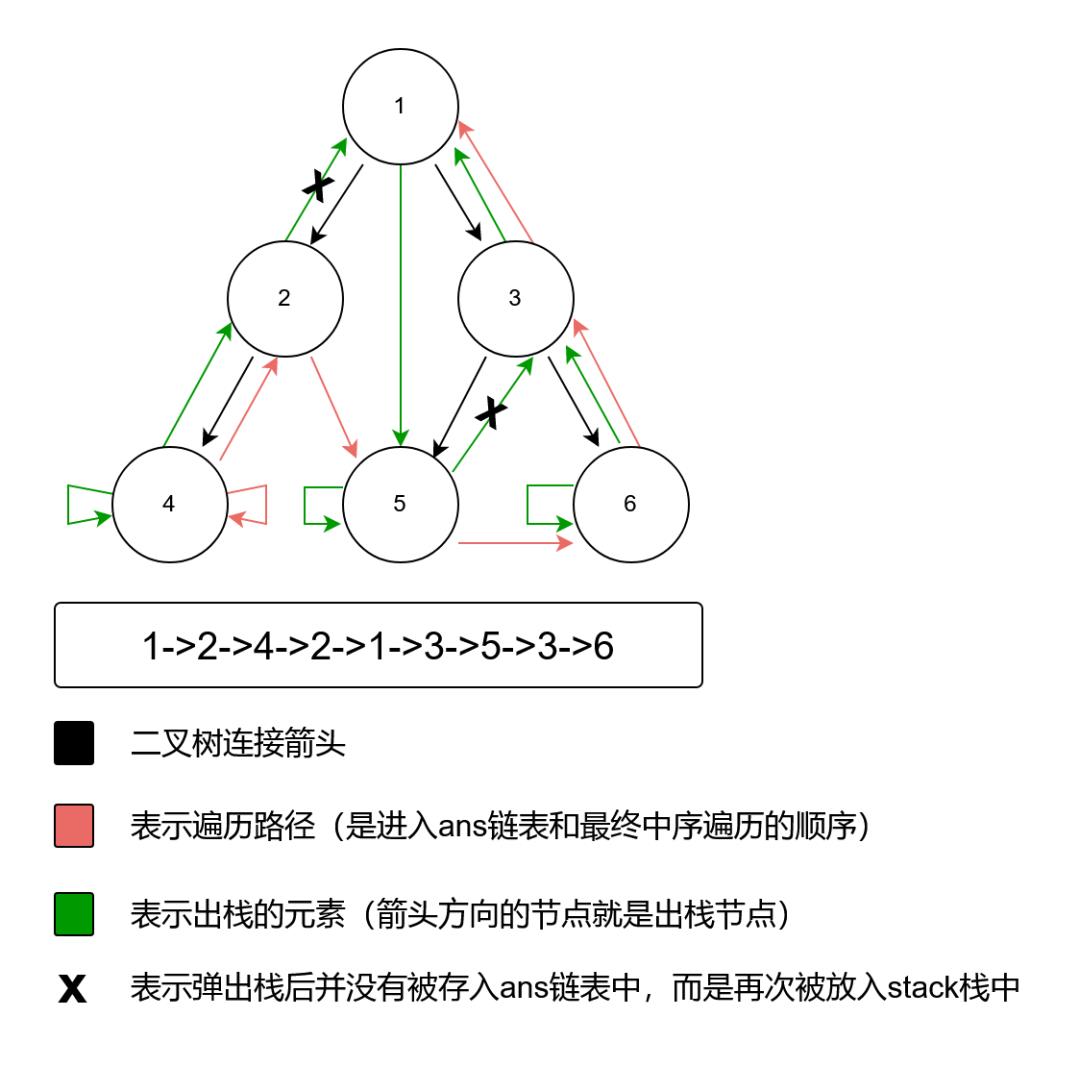
我们在以最开头的案例,画一张整个节点出栈,以及遍历顺序的图。
上面我们讲了二叉树的前、中、后序遍历,那么接下来我们来讲一下什么是二叉树的层次遍历,其实二叉树的层次遍历,就是表面意思,一层一层的来遍历。
翠花,上例子了:
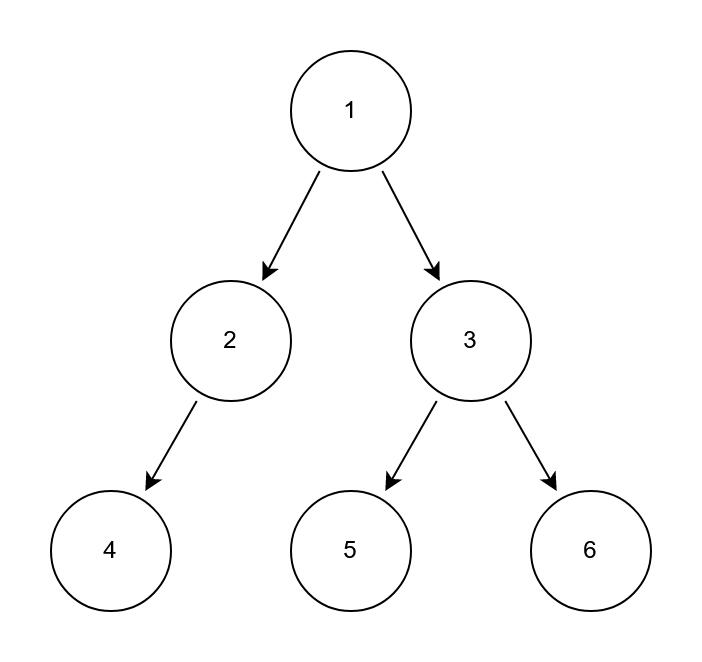
按照层次遍历的方式,其实就是1->2->3->4->5->6;
4.1 二叉树之层次遍历
题目:给你二叉树的根节点 root ,返回该节点值的后序遍历
二叉树之层次遍历——力扣URL:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/submissions/
示例1:
输入:root = [1,2,4,null,3,5,6]
输出:{
[1],
[2,3],
[4,5,6]
}
示例2:
输入:root=[1,null,2,3]
输出:{
[1],
[2],
[3]
}
小伙伴,心里大概有个谱了嘛,其实层次遍历就是这样从根节点所在的层,开始,一层一层的去遍历整棵二叉树。这个通常都是借助一个队列来完成的,就是用队列保存每层的节点,然后不断出栈,添加到一个链表中,然后在根据该层节点将下一层的节点添加进队列中。
二叉树层次遍历
时间复杂度O(n)
空间复杂度O(2^(n-1)) 每一层最多的节点数为2^(n-1),其中n为二叉树的深度
class Solution {public List<List<Integer>> levelOrder(TreeNode root) {Deque<TreeNode> queue = new ArrayDeque<TreeNode>();ArrayList<List<Integer>> ans = new ArrayList<>();//1. 如果root不为空,则加入到queue中,表示第一层的节点if(root!=null)queue.addLast(root);//2. 如果queue不为空,则继续循环遍历while(!queue.isEmpty()){//3. 获得当前层的节点数,并将其按FIFO顺序加入到list链表中,并判断出队列的节点是否有左右子节点,将其加入queue中int size = queue.size();//这里每次进入while循环都会创建一个链表用于存储该层节点List<Integer> list = new ArrayList<>();for(int i=size;i>0;i--){TreeNode node = stack.pollFirst();list.add(node.val);if(node.left!=null) queue.addLast(node.left);if(node.right!=null) queue.addLast(node.right);}//4. 将每层节点装入到汇总链表中ans.add(list);}return ans;}}
代码3处,我认为是比较关键的一个细节,因为,很多小伙伴的思路会从这里断开,一般有点经验的小伙伴可能都能想到借助队列来进行层次遍历,但是却不知道将一层节点添加到队列中后,如何访问下一层节点?
如果将一层的节点都装入队列,然后用for(int i = queue.size(); i>0; i--)来遍历,你就会发现问题,因为队列的长度是不断在变化的,当你从queue中弹出一个节点时,如果它存在左右子节点,就会将其添加到queue队列中,那么queue.size()就会不断变化,程序就会出现问题。因此,我们需要借助一个size的int类型的局部变量,来存储每一层的节点数,这样就算queue的长度变化,我们也能保证此次while循环处理的是同一层的节点了。
按照层次遍历那万年的案例,是如下图的这个样子的:
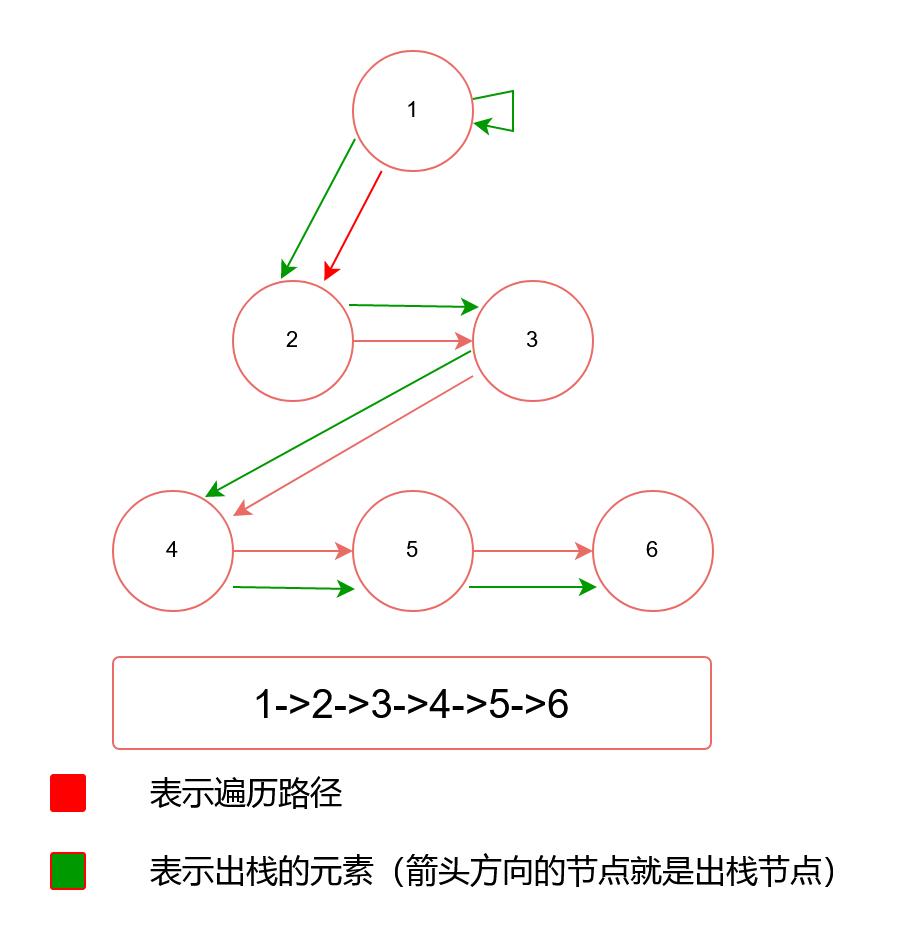
这里我们就简单的介绍了二叉树的层次遍历,其实层次遍历还有很多变向题,这里我们就先不讨论了,后面寸山会帮小伙伴们总结一波。并且多叉树其实也和二叉树类似,只是多叉树可能或存在多个孩子的情况,我们只需要在将孩子节点添加到queue队列时,做相对的操作就可以了。
根据排列组合我们也可以想到会有三种组合构造方式[前、中],[前、后],[中、后]。我们来依次分析一下,为啥,寸山会按照前、中、后、层次遍历,然后前、中、后序组合构造二叉树来讲,原因其实很简单,因为这是一套组合拳,小伙伴发现没有,寸山反正在面试的过程中就被这套组合拳KO了,整个人就点难受。
或许某天某位小伙伴就会被问到这样一套组合拳,在某个阳光明媚的下午,一位风度翩翩的秃头男人,坐在你面前,手握掉漆保温杯,慈祥的看了你一眼,便开始了你们的面试:

面试官:那么咱们开始今天的面试吧,请先做个自我介绍吧
爱德华:面试官,你好,我是爱德华,毕业于XXOO,balabala ......


面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......

面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......
面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......
面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......
面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......
面试官:好的,那接下来,介绍一下你的XX项目吧。
爱德华:balabala......
面试官:好,那接下来我们来玩玩算法吧,二叉树的前中序遍历会吧,手下一下吧。
爱德华:就是用递归 or 迭代就可以了,balabala......
面试官:那就用你写好的前序遍历和中序遍历构造成一颗唯一的二叉树,并且和原始的二叉树比较看是否为同一颗树。
爱德华:这有点为难我胖虎了
面试官的最后一句官方话语就不用我说了吧,因此,想要接下这一套组合二叉树算法题。我们需要真正掌握这些算法的思想,并多多练习。寸山帮兄弟伙总结下来,希望大家多多练习。
5.1 前序遍历和中序遍历构造的二叉树
从前序与中序遍历序列构造二叉树——力扣URL:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
示例:
输入:
前序遍历 preorder = [3, 9, 20, 15, 7]
中序遍历 inorder = [9, 3, 15, 20, 7]
输出:
新树的root
如下的树:
3
/
9 20
/
15 7
用前序遍历和中序遍历构造的二叉树时,我们会发现前序遍历的第一个节点就是整个原始树和新树的根节点,然后在中序遍历中找到这个节点,在中序数组中,这个节点之前的所有节点都是根节点的所有左节点,而之后的则是该根节点的所有右子节点。我们需要计算根节点所有的左子节点的个数leftNum,然后用分治的思想将数组分为两部分,分别递归构造左子树和右子树,直到p_start=p_end,则说明数组遍历完了,新树构造好了,返回新树的root即可
5.1.1 递归方法(采用for循环寻找中序数组根节点的下标)
递归+分治思想
时间复杂度O(nlogn) 首先n个节点都需要遍历一遍,其次每次寻找中序数组的根节点最坏情况下需要logn
空间复杂度O(n) 递归栈的空间
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {return buildTreeHelper(preorder, 0, preorder.length, inorder, 0, inorder.length);}public TreeNode buildTreeHelper(int[] preorder, int p_start, int p_end, int[] inorder, int i_start, int i_end){//1. 递归终止条件,说明已经将前序数组遍历完成了if(p_start == p_end)return null;//2. preorder第一个元素就是根节点,并创建新树的根节点int root_val = preorder[p_start];TreeNode root = new TreeNode(root_val);//3. 在中序数组中找到当前根节点,从当前的i_start开始,从i_end结束int i_root_val = 0;for(int i=i_start;i<i_end;i++){if(root_val == inorder[i]){i_root_val = i;break;}}//4. 计算当前根左子节点的个数int leftNum = i_root_val-i_start;//5. 利用分治思想分别递归构造左子树和右子树root.left = buildTreeHelper(preorder, p_start+1, p_start + leftNum + 1, inorder, i_start, i_root_val);root.right = buildTreeHelper(preorder, p_start + leftNum + 1, p_end, inorder, i_root_val + 1, i_end);//6. 返回当前新树的根节点return root;}}
5.1.2 优化的递归方法(采用HashMap寻找中序数组根节点的下标)
递归+分治思想+HashMap
时间复杂度O(n),每个节点都遍历一遍
空间复杂度O(n),递归栈所需的空间
class Solution {private HashMap<Integer,Integer> map = new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {//将中序数组的元素和对应的下标存入到HashMap中for(int i=0;i<inorder.length;i++){map.put(inorder[i],i);}return buildTreeHelper(preorder, 0, preorder.length, inorder, 0, inorder.length, map);}public TreeNode buildTreeHelper(int[] preorder, int p_start, int p_end, int[] inorder, HashMap<Integer,Integer> map){//1. 递归终止条件,说明已经将前序数组遍历完成了if(p_start == p_end)return null;//2. preorder第一个元素就是根节点,并创建新树的根节点int root_val = preorder[p_start];TreeNode root = new TreeNode(root_val);//3. 利用HashMap从中序数组中找到当前根节点int i_root_val = map.get(root_val);//4. 计算当前根左子节点的个数int leftNum = i_root_val-i_start;//5. 分别递归构造左子树和右子树root.left = buildTreeHelper(preorder, p_start+1, p_start + leftNum + 1, inorder, i_start, i_root_val, map);root.right = buildTreeHelper(preorder, p_start + leftNum + 1, p_end, inorder, i_root_val + 1, i_end, map);//6. 返回当前新树的根节点return root;}}
我们看到利用HashMap可以用O(1)的时间复杂度去寻找中序数组中当前根节点的下标。时间复杂度由原来的 O(nlogn) 变为 O(n)。
5.1.3 深度优化的递归方法(采用stop变量巧妙替换HashMap寻找中序数组根节点的下标)
该算法是由StefanPochmann 大神提供的,主要想优化就是可以省下HashMap占用的空间,可以在不使用HashMap的情况下找到根节点的位置。(具体寸山在这里先不讲了,推荐大家看:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by--22/)
本身寸山也稀里糊涂的,因此,就先停留在这里了,等后面有时间寸山在多转转大脑,看能不能茅塞顿开,带大家通俗易懂的理解大神的思路。
public TreeNode buildTree(int[] preorder, int[] inorder) {return buildTreeHelper(preorder, inorder, (long)Integer.MAX_VALUE + 1);}int pre = 0;int in = 0;private TreeNode buildTreeHelper(int[] preorder, int[] inorder, long stop) {//到达末尾返回 nullif(pre == preorder.length){return null;}//到达停止点返回 null//当前停止点已经用了,in 后移if (inorder[in] == stop) {in++;return null;}int root_val = preorder[pre++];TreeNode root = new TreeNode(root_val);//左子树的停止点是当前的根节点root.left = buildTreeHelper(preorder, inorder, root_val);//右子树的停止点是当前树的停止点root.right = buildTreeHelper(preorder, inorder, stop);return root;}
5.1.4 迭代的方法
如同前、中、后序遍历一样,我们可以采用递归和迭代两种方法解题,该题也除了使用递归的方法外也可以使用迭代的方法来解决此题。
迭代方法的思想其实就是,先建立新树的root节点,因为前序数组第一个节点元素肯定就是原始二叉树的root。然后将其存入stack栈中,然后从前序数组中开始遍历,并记录一个中序数组的inorderindex下标,每次比较当前栈顶和中序数组inorderindex下标是否相同,不相同则表明现在正在构建左子树,也就是还在遍历前序数组的左子节点,当相同时,表明左子节点已经遍历完成了,现在开始遍历右子树节点了,我们遍历到右子节点后需要判断该右子节点是属于哪一个左子节点的右子节点。因此,我们根据栈中左子节点的排序顺序刚好是中序数组中排序的倒序,栈中前者比后者的根级别高,且在中序遍历中更靠近右子节点,因此,我们只需要while循环遍历找到inorderindex下标对应的节点元素与栈顶节点不相同时的情况,此时,最后一个弹出栈的节点,便是当前右子节点的父节点。;
那我们接下来就来用玩不腻的万年例子给大家举个例子: 前序数组:[1, 2, 4, 3, 5, 6] 中序数组:[4, 2, 1, 5, 3, 6]
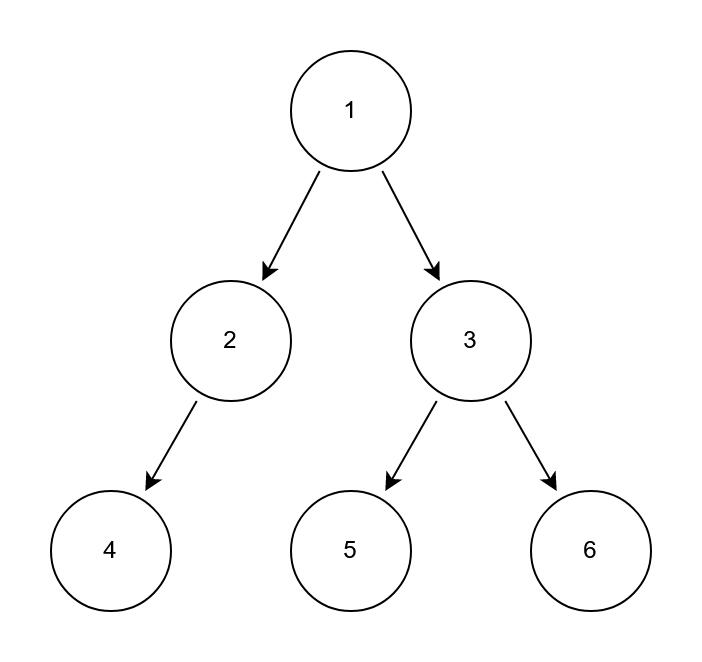
原始二叉树
首先我们存在一个辅助栈stack和inorderindex中序数组下标作为辅助,然后我们看到前序数组遍历第一个节点是 1,也是原始树的root节点。因此我们建立新树的root节点并将该节点添加进入stack栈中。
stack [1]
inorderindex = 0
我们已经知道了root根节点了,如果只知道前序数组的话,我们就无法知道节点1之后的,哪些是左子节点,哪些是右子节点了,因此我们就需要用中序数组作为辅助,帮助我们来判断某个节点是左子节点还是右子节点。
当遍历到节点2时,寸山一看就是左子节点,利用力扣官方的理解思路我们来反证一下,如果2是右子节点,那么说明root(val=1的节点)节点不存在左子节点,那么中序数组,第一个节点应该就是root节点,但是我门明显看到inorder数组中的第一个节点是4,因此,节点2就是左子节点,将其加入到栈中。
stack [1, 2]
inorderindex = 0
当遍历到节点4时,我们也可以用反证法去验证,验证下来它肯定也是左子节点,而且我们发现了一些规律,我们可以看到当我们在判断一个节点是否是左子节点的时候,我们都可以拿当前栈顶的节点和inorder数组的inorderindex下标的节点(即当前分支子树的第一个节点)做比较来判断是否相等,不相等说明,该节点是栈顶元素的左子节点。相等,则说明该节点是某个节点的右子节点,我们需要进一步去找到该右子节点具体的父节点。
stack[1, 2, 4]
inorderindex = 0
当遍历到节点3时,我们发现栈顶节点是4,而inorderindex下标的节点也是4,说明节点3是右子节点,哪么谁是它的亲生父亲呢?我们需要探究一下。首先我们先观察stack栈中所有左子节点的顺序是1,2,4,而他们在中序数组的顺序是4,2,1,我们发现刚好是反着来的,那么我们想找该右子节点的亲生父亲,肯定要找离它最近的一个左子节点了,因此,我们可以通过stack弹栈,然后中序数组顺序的方向找到离该右子节点最近的一个父节点。
1. inorderindex = 0,inorder[inorderindex] = 4 = stack.pop(),因此弹出栈元素,继续while循环。
2. inorderindex = 1,inorder[inorderindex] = 2 = stack.pop(),继续while循环。
3. inorderindex = 2,inorder[inorderindex] = 1 = stack.pop() ,继续while循环。
4. inorderindex = 3,inorder[inorderindex] = 5,但是stack.pop()空了,那么此时跳出循环,最后一次弹出栈的左子节点就是最靠近该右子节点的,因此节点3是节点1的右子节点。这里,如果栈没有空,而是存在其他元素的时候,也会因为,inorder[inorderindex] != stack.pop()而跳出循环的。
5. 此时,将节点3加入新树中,且其作为节点1的右子节点。并将节点3入栈。
stack[3]
inorderindex = 3
遍历到节点5的时候,我们发现栈顶节点为3,而inorderindex下标的节点为5,不相等,因此节点5为子树的左子节点,将节点5入栈,并将其插入到节点3的左子节点的位置(如果判断为某子树的左子节点则它是栈顶节点的左子节点)。
stack[3, 5]
inorderindex = 3
遍历到节点6的时候,我们发现
1. inorder[inorderindex] = 5 = stack.pop();因此,需要弹出节点5,inorderindex = 4,需要继续while循环遍历。
2. inorder[inorderindex] = 3 = stack.pop();需要弹出节点3,inorderindex = 5,需要继续while循环遍历。
3. inorder[inorderindex] = 6 ,但是此时stack为空,则说明最后一次弹出栈的节点3就是右子节点6的父节点。因此将节点6插入到新树节点3的右子节点上即可。并将节点6加入到stack栈中
最后返回root,就得到了由前序数组和中序数组构造的唯一的二叉树了。
看完了上面的例子,接下来我们具体看看迭代的算法怎样实现吧
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder){//前序数组为空 or 长度为0则返回 nullif(preorder==null || preorder.length==0){return null;}Deque<TreeNode> stack = new LinkedList<TreeNode>();//建立新树根节点TreeNode root = new TreeNode(preorder[0]);stack.push(root);//记录中序遍历的下标,主要用于判断是否是左子节点,后者是某个节点的右子节点int inorderindex = 0;//1. 遍历循环前序数组,然后用栈和中序数组来判断节点是左子节点,还是某个节点的右子节点for(int i=1;i<preorder.length;i++){int preorderval = preorder[i];TreeNode node = stack.peek();//1. 如果栈顶元素不等于中序遍历inorderindex下标的节点,则表明当前节点是左子树上的节点//栈中前者的节点比后者的根级别高,也就是越靠近root节点if(node.val!=inorder[inorderindex]){node.left = new TreeNode(preorderval);stack.push(node.left);}else{//2. 当栈顶元素等于inorderindex的下标时,则说明左子树遍历完成,开始遍历右子树了//判断右子节点属于哪个节点的右子节点的时候,我们发现前面入栈的左子树的节点的顺序,刚好在中序遍历是反过来的//当我们从栈中弹出的第一个节点肯定和中序数组的第一个节点相同,就这样不断弹栈,然后将inorderindex向后移动,直到第一个不相同的节点为止,那么在中序遍历中,该节点肯定是第一个右子节点,该右子节点就是最后一个出栈的节点的右子节点while(!stack.isEmpty()&&stack.peek().val==inorder[inorderindex]){node = stack.pop();inorderindex++;}//3. 将右子节点存入新树之中,node是while循环中最后一个出栈的节点,并将右节点放入栈中node.right = new TreeNode(preorderval);stack.push(node.right);}}return root;}}

总结
寸山觉得递归比较容易理解,就是找到根节点的位置,计算左子树节点的个数,然后利用分治思想继续递归就好了,在找寻根节点的下标位置时,我们可以利用HashMap搜索时间复杂度为O(1)的特点对其进行优化,其实用stop变量和迭代方法都还是要有点技巧性的,也没那么容易理解。尤其是stop变量法,因此,寸山觉得只要掌握HashMap和迭代方法应该面试的时候就可以了。
5.2 前序遍历和后序遍历构造的二叉树
5.2.1 递归方法+分治思想
其实用前序遍历和后续遍历得到的数组构建一个二叉树,寸山就不想讲的太细致了,大体方法是一致的,只是存在因为前、中、后遍历顺序的差异性而导致的某些个小环节的变动。
例子:
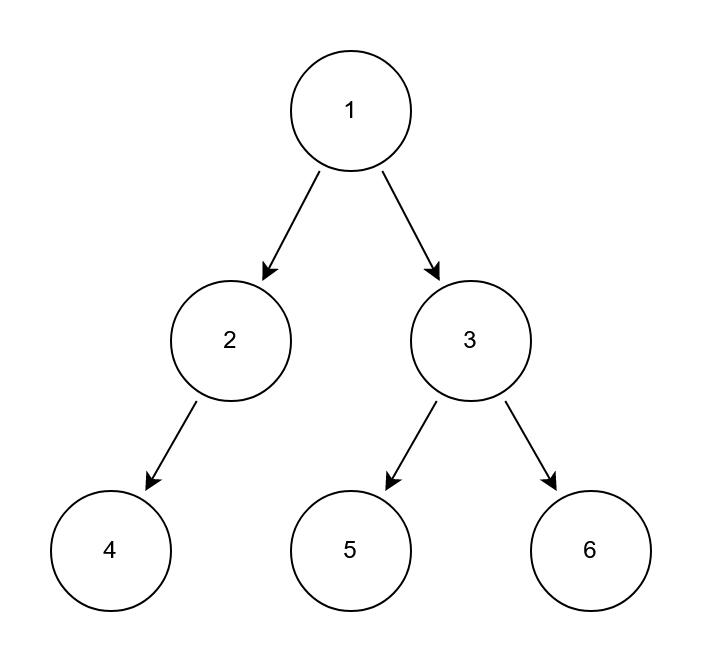
前序数组:[1,2,4,3,5,6] 按照遍历的顺序:[1]+[2,4]+[3,5,6]
后序数组:[4,2,5,6,3,1] 按照遍历的顺序:[4,2]+[5,6,3]+[1]
首先只要有前序遍历我们都能够很快的找到原始二叉树的root节点。在观察上面按照遍历顺序的两组数组,我们可以看出,后序数组在遍历左右分支时和前序数组在遍历左右分支时刚好是互为倒序的。比如前序中左分支为[2,4],后序中左分支则为[4,2]。右分支也是这样的,我们在结合分治递归的思想,其实还是比较容易想到解题思路的。我们可以遍历后序数组找到左分支节点的个数L。我们可以用pre[1:L+1]以及post[0:L]递归构造成新的二叉左分支。然后用pre[L+1:pre.length]以及post[L:post.length]递归构造新的二叉右分支。这样一颗新树就创建好了。
接下来我们就来看看这个算法的详细细节: 递归+分治思想 时间复杂度O(n^2),每次递归都需要O(n)的时间复杂度,在递归时,需要利用for循环找到左分支的长度,这需要O(n)的时间复杂度,并且每个节点被遍历一次,因此时间复杂度为O(n*n) 空间复杂度也为O(n^2),调用了Arrays.copyOfRange方法最坏需要数组的副本来9占用O(n)的空间复杂度,我们需要递归n次,因此,我们最后需要O(n^2)的空间复杂度。
class Solution {public TreeNode constructFromPrePost(int[] pre, int[] post) {//1. 创建新二叉树的root节点int len = pre.length;if(len == 0) return null;TreeNode root = new TreeNode(pre[0]);if(len == 1) return root;//2. 计算左子节点的长度,如果post[i] = pre[1], 则说明我们找到了左子节点的长度//那么在pre前序数组中,左子节点的长度范围为[1,L+1],在post后续数组中,左子节点的长度范围为[0,L]int L = 0;for(int i=0;i<len;++i){if(post[i] == pre[1])L = i+1;}//3. 用分治思想,递归找到左分支和右分支root.left = constructFromPrePost(Arrays.copyOfRange(pre,1,L+1),Arrays.copyOfRange(post,0,L));root.right = constructFromPrePost(Arrays.copyOfRange(pre,L+1,len),Arrays.copyOfRange(post,L,len));//4. 返回root根节点return root;}}
5.2.2 (采用HashMap优化 (错误解法) )递归方法+分治思想
这种方法存在问题,因为5.2.1的解法中,我们虽然使用for循环来遍历post数组,找到与pre[1]相等的节点的下标来计算左子节点的长度,但是其实在post数组中找到的节点必须是当前post副本所在的下标,而不是原始的post数组所在的下标因此没有办法一次hash,然后一直使用,那么每次生成一次post数组副本,我们都需要重新赋值HashMap数组,这样和直接遍历就没有差异了,简直就是画蛇添足。
class Solution {private HashMap<Integer,Integer> map = new HashMap<>();public TreeNode constructFromPrePost(int[] pre, int[] post) {for(int i=0;i<post.length;++i){map.put(post[i],i);}return makeTree(pre,post,map);}public TreeNode makeTree(int[] pre,int[] post,HashMap<Integer,Integer> map){//1. 创建新二叉树的root节点int len = pre.length;if(len == 0) return null;TreeNode root = new TreeNode(pre[0]);if(len == 1) return root;//2. 计算左子节点的长度,如果post[i] = pre[1], 则说明我们找到了左子节点的长度//那么在pre前序数组中,左子节点的长度范围为[1,L+1],在post后续数组中,左子节点的长度范围为[0,L]int L = 0;L = map.getOrDefault(pre[1],-1)+1;//3. 用分治思想,递归找到左分支和右分支root.left = makeTree(Arrays.copyOfRange(pre,1,L+1),Arrays.copyOfRange(post,0,L),map);root.right = makeTree(Arrays.copyOfRange(pre,L+1,len),Arrays.copyOfRange(post,L,len),map);//4. 返回root根节点return root;}}
代码2处存在错误,因为必须是获取新的post数组副本对应节点的下标才可以,因此,在后续的代码中就会出现问题。
5.2.3 (利用数组起始位置和长度优化数组副本)递归方法+分治思想
该方法其实就是利用pr_start和po_start两个变量来分别记录pre数组和post数组的每次递归的起始点,然后再用len记录每次递归的数组长度,然后计算每次递归时,数组所拥有的左子节点个数,利用分治的思想将数组划分为左子树和右子树,在分别递归,对于每个节点来说都会递归寻找其左右子节点。
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {private HashMap<Integer,Integer> map = new HashMap<>();public TreeNode constructFromPrePost(int[] pre, int[] post) {return makeTree(pre,post,0,0,pre.length);}public static TreeNode makeTree(int[] pre,int[] post,int pr_start,int po_start, int len){if(len==0) return null;TreeNode root = new TreeNode(pre[pr_start]);if(len==1) return root;//1. 计算左子节点的长度int L =1;for(;L<len;++L){if(post[po_start+L-1] == pre[pr_start+1]){break;}}/*** 2. 递归遍历每一个节点的左右子节点,有则返回,没有则返回null* pr_start表示每次pre开始的位置,po_start表示post数组开始的位置,len表示当前数组的长度* 记录数组的起始点和长度就可以变向的得到数组的副本*/root.left = makeTree(pre,post,pr_start+1,po_start,L);root.right = makeTree(pre,post,pr_start+L+1,po_start+L,len-L-1);//3. 返回root节点return root;}}
这里我们其实可以使用HashMap来做优化,但是寸山试过后,好像时间复杂度上升了,空间复杂度倒是降低了。反正就很迷,按理来说,我们应该是用空间换时间,时间复杂度应该降低的,而空间复杂度应该上升的,但是正好相反,寸山觉得非常的奇怪。明白的小伙伴可以不吝赐教哈。
class Solution {private HashMap<Integer,Integer> map = new HashMap<>();public TreeNode constructFromPrePost(int[] pre, int[] post) {for(int i=0;i<pre.length;i++){map.put(post[i],i);}return makeTree(pre,post,0,0,pre.length,map);}public static TreeNode makeTree(int[] pre,int[] post,int pr_start,int po_start, int len,Map<Integer,Integer> map){if(len==0) return null;TreeNode root = new TreeNode(pre[pr_start]);if(len==1) return root;//计算左子节点的长度int L = map.get(pre[pr_start+1])-po_start+1;/*** 递归遍历每一个节点的左右子节点,有则返回,没有则返回null* pr_start表示每次pre开始的位置,po_start表示post数组开始的位置,len表示当前数组的长度* 记录数组的起始点和长度就可以变向的得到数组的副本*/root.left = makeTree(pre,post,pr_start+1,po_start,L,map);root.right = makeTree(pre,post,pr_start+L+1,po_start+L,len-L-1,map);return root;}}
5.3 中序遍历和后序遍历构造的二叉树
首先,我们应该分析中序遍历和后序遍历的规律,中序遍历的顺序是 左子节点->根节点->右子节点,而后序遍历的顺序是 左子节点->右子节点->根节点。我们不难想到其实这道题和前序遍历+中序遍历构造二叉树的思路是一样的,后序数组的最后一个节点元素其实就是整棵二叉树的root节点。然后,我们通过在中序遍历中找到root节点,root节点左边的就是左子节点,而右边的就是右子节点,然后在继续递归。
中序遍历和后序遍历构造二叉树:力扣URL:https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/submissions/

第一种方法和 前序+中序一样可以利用Arrays.copyOfRange()方法,来直接截取出数组副本进行递归,但是这样浪费了空间复杂度,这里我们就不演示了,小伙伴们可以参照之前的代码自行动手实现。
5.3.1 (利用数组起始位置和长度优化数组副本)递归方法+分治思想
这种思路其实就是主要用两个数组的起始位置参数加上数组的长度来代替使用数组副本,以达到降低空间复杂度。接下来寸山就带领大家看看该思路的算法。
class Solution {public TreeNode buildTree(int[] inorder, int[] postorder) {return makeTree(inorder, postorder,0,0,postorder.length);}public TreeNode makeTree(int[] inorder, int[] postorder,int i_start,int p_start,int len){/*** 1. 递归终止条件* len = 0,说明上次递归已经遍历到了某个分支的叶子节点* len = 1,说明当前递归正在遍历某分支的叶子节点*/if(len==0) return null;TreeNode root = new TreeNode(postorder[p_start+len-1]);if(len==1) return root;/*** 2. 计算某个分支的左子节点的个数,or 左子节点的长度* 这里L从0开始,在前序遍历中,根先被遍历因此 L=1,而中序遍历左子节点先被遍历因此 L初始化为0*/int L = 0;for(;L<len;++L){if(inorder[i_start+L]==postorder[p_start+len-1]){break;}}/*** 3. 采用分治的思想,分别找到root节点的左子节点和右子节点* i_start 记录中序数组的起始点* p_start 记录后序数组的起始点* L是当前分支的左子节点的个数* len是当前数组的长度*/root.left = makeTree(inorder,postorder,i_start,p_start,L);root.right = makeTree(inorder,postorder,i_start+L+1,p_start+L,len-L-1);//4. 返回root节点return root;}}
5.3.2 (利用HashMap替代for循环寻找左子节点长(空间换时间))递归方法+分治思想
中序+后序数组构造二叉树
HashMap+递归+分支思想
时间复杂度O(n),每个节点都要遍历一遍
空间复杂度O(n),提前将中序数组装入map集合中,以及O(h)递归栈的时间复杂度,其中h是树的高低,由于h<n,因此,空间复杂度为O(n)
该算法是5.3.1中算法的优化,用空间换时间,之前每次都是用for循环来计算当前数组左子节点的长度。现在提前将中序数组存入map集合,然后每次都用O(1)的时间复杂度寻找当前根节点的下标,因为该根节点的下标现在只是中序数组的下标,因此还需要减去i_start的起始下标,才是当前数组的左子节点的长度。
class Solution {private Map<Integer,Integer> map = new HashMap<Integer,Integer>();public TreeNode buildTree(int[] inorder, int[] postorder) {for(int i=0;i<inorder.length;i++){map.put(inorder[i],i);}return makeTree(inorder, postorder, 0, 0, postorder.length, map);}public TreeNode makeTree(int[] inorder, int[] postorder,int i_start,int p_start,int len,Map<Integer,Integer> map){/*** 1. 递归终止条件* len = 0,说明上次递归已经遍历到了某个分支的叶子节点* len = 1,说明当前递归正在遍历某分支的叶子节点*/if(len==0) return null;TreeNode root = new TreeNode(postorder[p_start+len-1]);if(len==1) return root;/*** 2. 计算某个分支的左子节点的个数,or 左子节点的长度* 这里L从0开始,在前序遍历中,根先被遍历因此 L=1,而中序遍历左子节点先被遍历因此 L初始化为0*/int L = map.get(root.val)-i_start;/*** 3. 采用分治的思想,分别找到root节点的左子节点和右子节点* i_start 记录中序数组的起始点* p_start 记录后序数组的起始点* L是当前分支的左子节点的个数* len是当前数组的长度*/root.left = makeTree(inorder, postorder, i_start, p_start, L, map);root.right = makeTree(inorder, postorder, i_start+L+1, p_start+L, len-L-1, map);//4. 返回root节点return root;}}
5.4 前、中、后 两两排列组合构造二叉树总结
针对该类算法题寸山帮小伙伴们总结了一个模板,基本框架都差不多,就是某些细节稍微改变下,主要由于不同组合会有不同组合的特点。
-
前+中:前序数组首元素就是整棵二叉树的root节点,在计算左子节点的长度len时,直接在中序数组中找到root节点,然后用中序数组root节点的下标减去中序数组的起始位置i_start,即可计算出左子节点的长度,再用分治思想将数组分为两部分,分别递归找寻每个当前root的左右子节点即可。
-
中+后:后序数组的尾元素就是整棵二叉树的root节点,在计算左子节点的长度len时,直接在中序数组中找到root节点,然后用中序数组root节点的下标减去中序数组的起始位置i_start,即可计算出左节点的长度,再用分治思想将数组分为两部分,分别递归找寻每个当前root的左右子节点即可。
-
前+后:我们还是默认使用前序数组的首元素作为整棵二叉树的root节点,由于前序遍历是 根节点->左子节点->右子节点,而后序遍历则是 左子节点->右子节点->根节点。我们可以发现前序数组中的root节点的所有左子节点和后序数组中的root节点的所有左子节点的顺序刚好是反的,也就是说我们只要在后序数组中找到前序数组的root节点后的第一个左子节点的下标,然后再减去后序数组起始位置+1,就可以计算出左子节点的len,至于为什么+1,因为数组是从0开始的嘛,后序数组左子节点也是从0开始的。比如说找寻的下标为3,起始位置为0,则真实的左子节点是有4个,因此需要+1。找到len后,再用分治思想将数组分为两部分,分别递归找寻每个当前root的左右子节点即可。
下面我们用gif动图给大家展示下解题代码:

前面我们将了,用前、中、后中的两种排列组合构造唯一一颗新的二叉树,可以和原来的二叉树做比较,看是否相同。因此,该题是可以与前面组合成一套的算法题,寸山就带领大家熟悉一下吧。
主要分为3个部分:
递归终止条件,就是当前p、q节点都为null,说明两颗二叉树都已经被遍历完,且完全相同,则返回true
当前p、q都不为null,继续判断p、q节点是否相同,相同则返回 左右节点递归结果的与运算。
其他情况则返回false,比如p、q某一个节点为null。再比如,p、q虽然都不为null,但是p、q不相同,则说明两颗二叉树不相同。
class Solution {public static boolean isSameTree(TreeNode p, TreeNode q) {//1. 递归终止条件,如果当前p、q 同时为空,则说明遍历完了两颗二叉树,所以相同返回trueif(p==null && q==null)return true;//2. 判断当前 p、q 节点是否同时不为空,是则继续判断是否相同,相同则递归判断其左右子节点else if(p != null && q != null){if(p.val==q.val)//有一个不相同则两棵树就不相同,所以用与运算return isSameTree(p.left,q.left) && isSameTree(p.right, q.right);}/*** 3. 其他情况则说明两棵树不相同,比如有某棵树的p or q 节点,一个为null,一个不为null* 或则两个节点都不为空,但是不相同,也需要直接返回false*/return false;}}
采用深度搜索的递归方式
时间复杂度 O(min(m,n)) m、n分别指两颗二叉树的节点数,最坏情况下每个节点都需要遍历
空间复杂度 O(min(m,n)) 递归过程中递归栈的空间使用
到此,我们的这套组合拳也就结束了,从二叉树的前、中、后、层次遍历,再到前、中、后序遍历两两排列组合构造唯一的二叉树,最后再到验证两颗二叉树是否相同。希望小伙伴和寸山一起多多练习,掌握这些二叉树的基本算法,在面试中遇到相类似的题可以稳如泰山。完结,撒花
以上是关于大厂面试不可不会的二叉树相关算法的主要内容,如果未能解决你的问题,请参考以下文章