一文了解函数式查询优化器Spark SQL Catalyst
Posted 大数据真好玩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文了解函数式查询优化器Spark SQL Catalyst相关的知识,希望对你有一定的参考价值。
0. Overview
1. Catalyst工作流程
2. Parser模块
3. Analyzer模块
4. Optimizer模块
5. SparkPlanner模块
6. Job UI
7. ReferenceOverview
基于规则优化/Rule Based Optimizer/RBO
nestedLoopsJoin,P,Q双表两个大循环, O(M*N)
sortMergeJoin是P,Q双表排序后互相游标
broadcastHashJoin,PQ双表中小表放入内存hash表,大表遍历O(1)方式取小表内容
一种经验式、启发式优化思路
对于核心优化算子join有点力不从心,如两张表执行join,到底使用broadcaseHashJoin还是sortMergeJoin,目前sparkSql是通过手工设定参数来确定的,如果一个表的数据量小于某个阈值(默认10M?)就使用broadcastHashJoin
基于代价优化/Cost Based Optimizer/CBO
针对每个join评估当前两张表使用每种join策略的代价,根据代价估算确定一种代价最小的方案
不同physical plans输入到代价模型(目前是统计),调整join顺序,减少中间shuffle数据集大小,达到最优输出
Catalyst工作流程
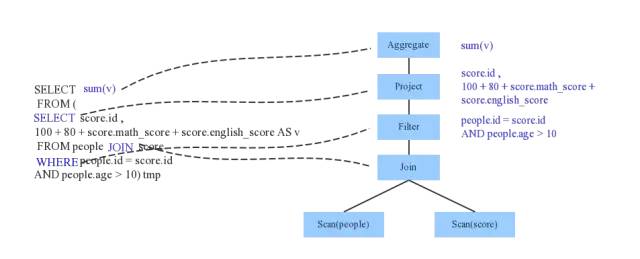
Parser,利用ANTLR将sparkSql字符串解析为抽象语法树AST,称为unresolved logical plan/ULP
Analyzer,借助于数据元数据catalog将ULP解析为logical plan/LP
Optimizer,根据各种RBO,CBO优化策略得到optimized logical plan/OLP,主要是对Logical Plan进行剪枝,合并等操作,进而删除掉一些无用计算,或对一些计算的多个步骤进行合并
other
SparkPlanner
优化后的逻辑执行计划OLP依然是逻辑的,并不能被spark系统理解,此时需要将OLP转换成physical plan
从逻辑计划/OLP生成一个或多个物理执行计划,基于成本模型cost model从中选择一个
Code generation
生成Java bytecode然后在每一台机器上执行,形成RDD graph/DAG
Parser模块
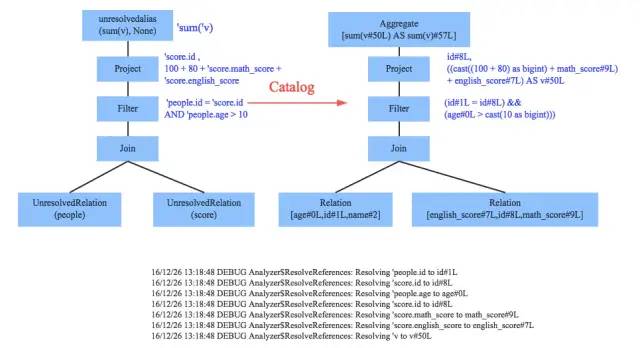
Analyzer模块
元数据信息schema catalog
来表达这些token。最重要的元数据信息就是,
表的schema信息,主要包括表的基本定义(表名、列名、数据类型)、表的数据格式(json、text、parquet、压缩格式等)、表的物理位置
基本函数信息,主要是指类信息
//org.apache.spark.sql.catalyst.analysis.Analyzer.scala
lazy val batches: Seq[Batch] = Seq( //不同Batch代表不同的解析策略
Batch("Substitution", fixedPoint,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
new SubstituteUnresolvedOrdinals(conf)),
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions ::
ResolveRelations :: //通过catalog解析表或列基本数据类型,命名等信息
ResolveReferences :: //解析从子节点的操作生成的属性,一般是别名引起的,比如people.age
ResolveCreateNamedStruct ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveMissingReferences ::
ExtractGenerator ::
ResolveGenerate ::
ResolveFunctions :: //解析基本函数,如max,min,agg
ResolveAliases ::
ResolveSubquery :: //解析AST中的字查询信息
ResolveWindowOrder ::
ResolveWindowFrame ::
ResolveNaturalAndUsingJoin ::
ExtractWindowExpressions ::
GlobalAggregates :: //解析全局的聚合函数,比如select sum(score) from table
ResolveAggregateFunctions ::
TimeWindowing ::
ResolveInlineTables ::
TypeCoercion.typeCoercionRules ++
extendedResolutionRules : _*),
Batch("Nondeterministic", Once,
PullOutNondeterministic),
Batch("UDF", Once,
HandleNullInputsForUDF),
Batch("FixNullability", Once,
FixNullability),
Batch("Cleanup", fixedPoint,
CleanupAliases)
)Optimizer模块
Optimizer是catalyst的核心,分为RBO和CBO两种。
RBO的优化策略就是对语法树进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换,即将一棵树等价地转换为另一棵树。SQL中经典的常见优化规则有,
谓词下推(predicate pushdown)
常量累加(constant folding)
列值裁剪(column pruning)
Limits合并(combine limits)
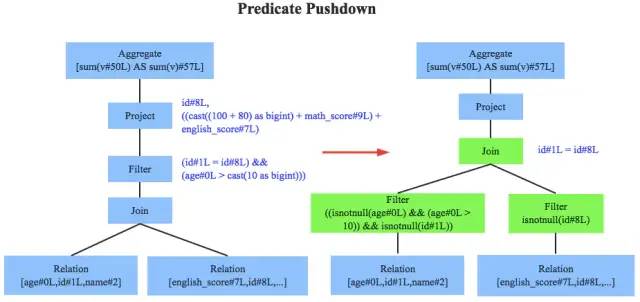
由下往上走,从join后再filter优化为filter再join
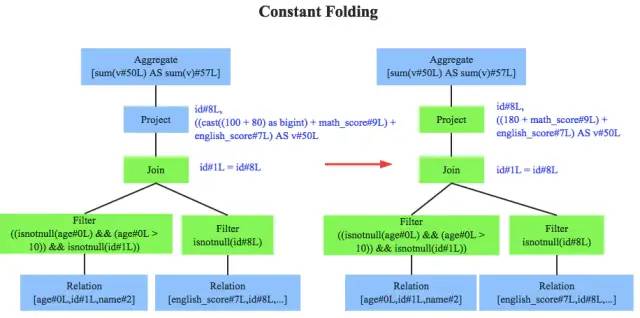
从`100+80`优化为`180`,避免每一条record都需要执行一次`100+80`的操作
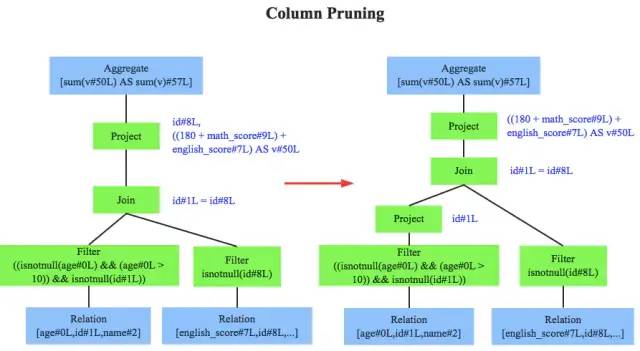
剪裁不需要的字段,特别是嵌套里面的不需要字段。如只需people.age,不需要people.address,那么可以将address字段丢弃
//@see http://blog.csdn.net/oopsoom/article/details/38121259
//org.apache.spark.sql.catalyst.optimizer.Optimizer.scala
def batches: Seq[Batch] = {
// Technically some of the rules in Finish Analysis are not optimizer rules and belong more
// in the analyzer, because they are needed for correctness (e.g. ComputeCurrentTime).
// However, because we also use the analyzer to canonicalized queries (for view definition),
// we do not eliminate subqueries or compute current time in the analyzer.
Batch("Finish Analysis", Once,
EliminateSubqueryAliases,
ReplaceExpressions,
ComputeCurrentTime,
GetCurrentDatabase(sessionCatalog),
RewriteDistinctAggregates) ::
//////////////////////////////////////////////////////////////////////////////////////////
// Optimizer rules start here
//////////////////////////////////////////////////////////////////////////////////////////
// - Do the first call of CombineUnions before starting the major Optimizer rules,
// since it can reduce the number of iteration and the other rules could add/move
// extra operators between two adjacent Union operators.
// - Call CombineUnions again in Batch("Operator Optimizations"),
// since the other rules might make two separate Unions operators adjacent.
Batch("Union", Once,
CombineUnions) ::
Batch("Subquery", Once,
OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,
ReplaceIntersectWithSemiJoin,
ReplaceExceptWithAntiJoin,
ReplaceDistinctWithAggregate) ::
Batch("Aggregate", fixedPoint,
RemoveLiteralFromGroupExpressions,
RemoveRepetitionFromGroupExpressions) ::
Batch("Operator Optimizations", fixedPoint,
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
PushPredicateThroughJoin, //谓词下推之一
PushDownPredicate, //谓词下推之一
LimitPushDown,
ColumnPruning, //列值剪裁,常用于聚合操作,join左右孩子操作,合并相邻project列
InferFiltersFromConstraints,
// Operator combine
CollapseRepartition,
CollapseProject,
CollapseWindow,
CombineFilters, //谓词下推之一,合并两个相邻的Filter。合并2个节点,就可以减少树的深度从而减少重复执行过滤的代价
CombineLimits, //合并Limits
CombineUnions,
// Constant folding and strength reduction
NullPropagation,
FoldablePropagation,
OptimizeIn(conf),
ConstantFolding, //常量累加之一
ReorderAssociativeOperator,
LikeSimplification,
BooleanSimplification, //常量累加之一,布尔表达式的提前短路
SimplifyConditionals,
RemoveDispensableExpressions,
SimplifyBinaryComparison,
PruneFilters,
EliminateSorts,
SimplifyCasts,
SimplifyCaseConversionExpressions,
RewriteCorrelatedScalarSubquery,
EliminateSerialization,
RemoveRedundantAliases,
RemoveRedundantProject) ::
Batch("Check Cartesian Products", Once,
CheckCartesianProducts(conf)) ::
Batch("Decimal Optimizations", fixedPoint,
DecimalAggregates) ::
Batch("Typed Filter Optimization", fixedPoint,
CombineTypedFilters) ::
Batch("LocalRelation", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) ::
Batch("OptimizeCodegen", Once,
OptimizeCodegen(conf)) ::
Batch("RewriteSubquery", Once,
RewritePredicateSubquery,
CollapseProject) :: Nil
}SparkPlanner模块
至此,OLP已经得到了比较完善的优化,然而此时OLP依然没有办法真正执行,它们只是逻辑上可行,实际上spark并不知道如何去执行这个OLP。
比如join只是一个抽象概念,代表两个表根据相同的id进行合并,然而具体怎么实现这个合并,逻辑执行计划并没有说明
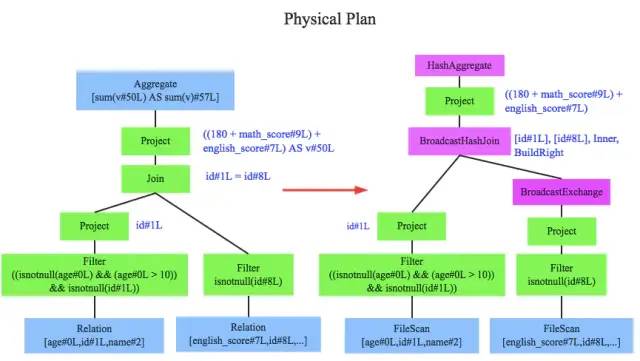
optimized logical plan -> physical plan
此时就需要将左边的OLP转换为physical plan物理执行计划,将逻辑上可行的执行计划变为spark可以真正执行的计划。
比如join算子,spark根据不同场景为该算子制定了不同的算法策略,有broadcastHashJoin、shuffleHashJoin以及sortMergeJoin,物理执行计划实际上就是在这些具体实现中挑选一个耗时最小的算法实现,这个过程涉及到cost model/CBO
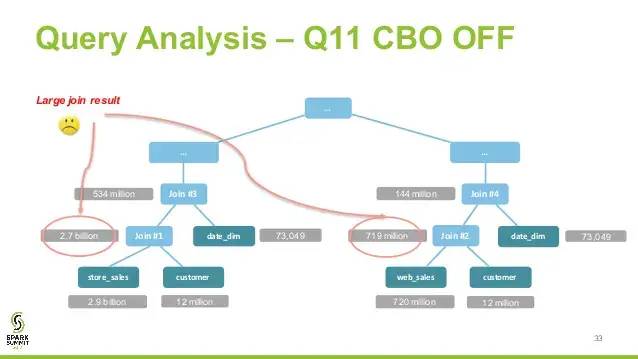
CBO off
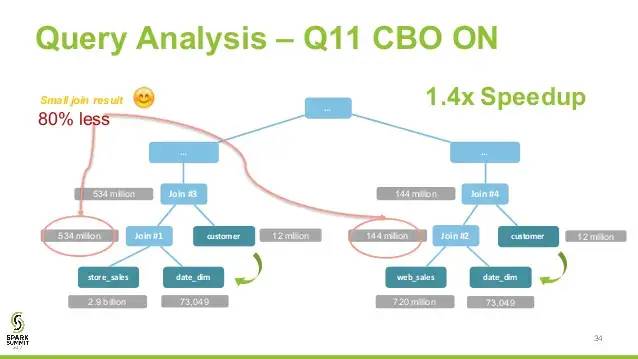
CBO on
CBO中常见的优化是join换位,以便尽量减少中间shuffle数据集大小,达到最优输出。
Job UI
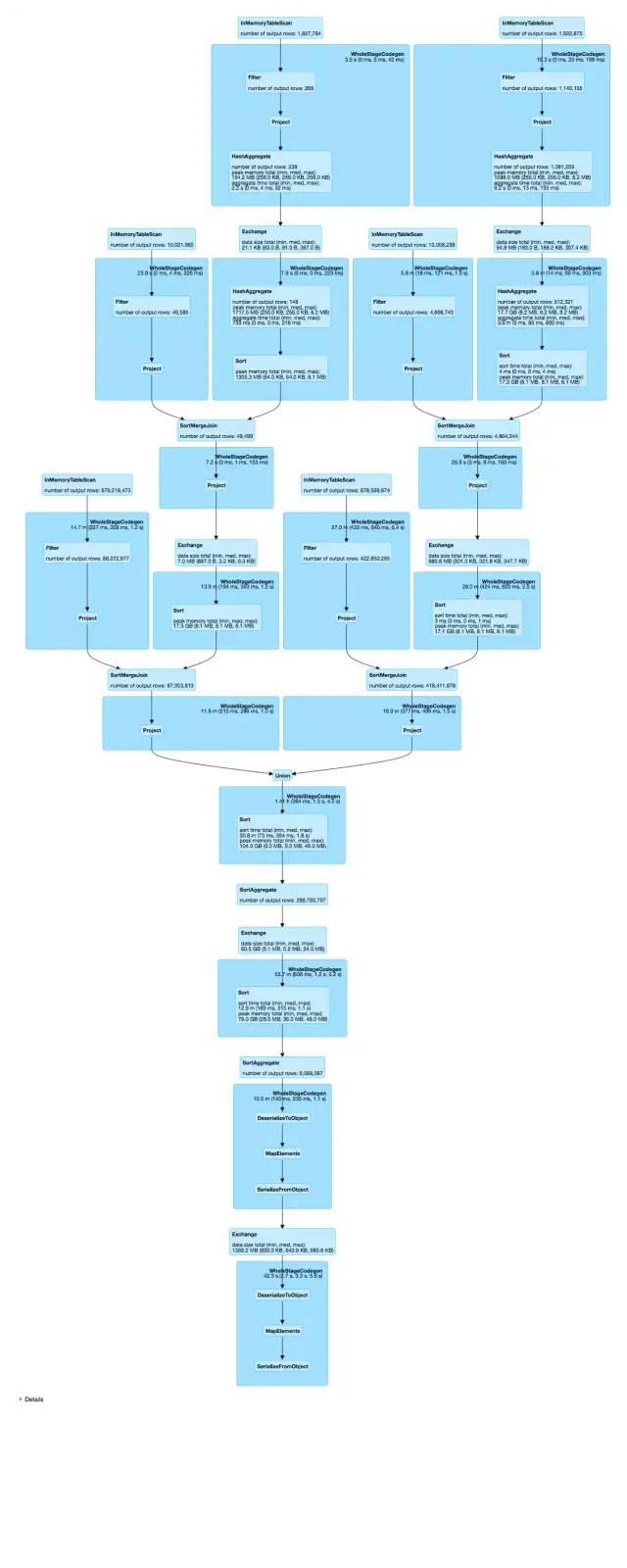
WholeStageCodegen,将多个operators合并成一个java函数,从而提高执行速度
Project,投影/只取所需列
Exchange,stage间隔,产生了shuffle
以上是关于一文了解函数式查询优化器Spark SQL Catalyst的主要内容,如果未能解决你的问题,请参考以下文章