最近学shell,在awk里,在语句的啥位置用正则表达式?例如 awk 'BEGIN FS=";" $4~/root/' testfile
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最近学shell,在awk里,在语句的啥位置用正则表达式?例如 awk 'BEGIN FS=";" $4~/root/' testfile相关的知识,希望对你有一定的参考价值。
在上面的例子里,我是知道的,我刚开始学,感觉应该大部分不是这样用的,请有经验的同学给讲解下,最好能有例子,谢谢。
awk中使用正则大致就下面三种形式。
形式一(跟你给出的类似):
awk '/正则/主体处理' file默认匹配$0,相当于 $0~/正则/
正则匹配后默认会打印匹配到的内容,所以若主体语句仅仅是print,可直接省略。
形式二:
awk 'if($4~/root/) print' file在主体语句的if判断里使用正则。
形式三:
awk '内置字符串处理函数' file在awk内置的字符串处理函数中使用正则,如sub, gsub, gensub, match等。
echo "ABC^H^H^H^HDEF" | awk 'gsub(/\\^H/,"");print $0'将所有^H替换为空,输出替换后的字符串。
这里gsub中省略了第三个参数“源字符串”,默认使用$0来匹配。
-------------------------------------------------------
大部分情况下,正则都是跟主体语句相关的,所以这里抛开awk的BEGIN和END语句块不看。
BEGIN语句块属于预处理,尚未读入要处理的数据,用不上正则;
END语句块属于后处理,可以用正则但少见,因为复杂的逻辑判断尽量都放在主体中完成。
追问先拜谢了
有几个小问题啊
形式一的格式就不需要BEGIN是吗? 这是一种特例的格式?话说“主体处理”能不能给个小例子。。
形式二 print 和printf 啥关系啥区别啊?
形式三 ^H前的\是转义字符吧?需要加“”吗?貌似我这儿用转义字符就必须加“”。
你的问题只是关于正则的位置啊,其他都是awk基础知识,可以不要糅杂堆砌在一起。
BEGIN和END都可以有,根据需要,只是我这里为了简化,抛开awk的BEGIN和END语句块不看。
echo "hello_kitty99" | awk 'BEGINFS="_";a=""$2~/[0-9]+/a=$2ENDprint a'
print 和printf ,学过C语言的都应该清楚。printf是格式化打印,print就是简单的直接打印。
自己试试:
echo | awk 'printf("%05d\\n", 22)'控制打印宽度为5个字符,不足的前面补0。
/\\^H/ 由于^在正则中有特殊含义,用于匹配字符串或行的开始位置,所以若要去除其特殊含义而表达^字符本身,需要转义。
参考技术A 假如你的例子 $4~/root/ (代表 第4列匹配 root)你就可以加入正则表达式了。。/ xxx / 在匹配内容中用正则表达式代表匹配的内容
shell脚本——正则表达式Sed与Awk文本处理工具详解
shell脚本——正则表达式、Sed与Awk详解
一、正则表达式概述
1、正则表达式的概念
通常用于判断语句中,用来检查某一字符串是否满足某一格式
- 正则表达式分为基础正则表达式与扩展正则表达式
- 它不是一个工具程序,而是一个字符串处理的标准依据
- 使用单个字符串搜索、匹配一系列符合某个语法规则的字符串
- 它是由普通字符(a~z),以及特殊字符(又叫“元字符”)组成
- 普通字符包括大小写字母、数字、标点符号及一些其他符号
- 元字符是指再正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
2、正则表达式支持的Linux文本处理工具
| 文本处理工具 | 基础正则表达式 | 扩展正则表达式 |
|---|---|---|
| vi编辑器 | 支持 | |
| grep | 支持 | |
| egrep | 支持 | 支持 |
| sed | 支持 | |
| awk | 支持 | 支持 |
#grep和awk应用于扩展正则表达式
grep -E
awk -r
3、基础正则表达式常见的字符
支持的工具:grep、egrep、sed、awk
| 字符 | 含义 |
|---|---|
| \\ | 转义字符,用于取消特殊符号的含义,例:!、\\n、$等 |
| ^ | 匹配字符串开始的位置,例:^a 、^the、 ^#、 ^$等 |
| $ | 匹配字符串结束的位置,例:world$匹配以world结尾的行 |
| . | 匹配除\\n(换行)以外的任意一个字符 |
| * | 匹配前面的子表达式0次或多次 |
| ? | 匹配前面的子表达式0次或1次,有或无 |
| [list] | 匹配list列表中的一个字符,如:[0-9]匹配任一位数字 |
| [^list] | 匹配不在list列表中的一个字符,如:[^0-9]匹配任意一位非数字字符 |
| {n} | 匹配前面的子表达式n次,如:[0-9]\\{2\\}匹配两位数字 |
| {n,} | 匹配前面的子表达式不少于n次,如:[0-9]\\{2,\\}表示两位及两位以上的数字 |
| {n,m} | 匹配前面的子表达式n到m次,如:[a-z]\\{2,3]匹配两到三位的小写字母 |
注:egrep、awk使用{n}、{n,}、{n,m}匹配时"{}“前不用加”",(m>=n)
4、扩展正则表达式元字符
| 元字符 | 作用 |
|---|---|
| + | 匹配前面的子表达式1次以上,如:go+d,将匹配至少一个o |
| ? | 匹配前面的子表达式0次或1次,如:go?d,将匹配gd或god |
| () | 将()号的字符串作为一个整体,如:(xyz)+,将匹配xyz整体1次以上 |
| l | 以或的方式匹配字符串,将匹配good或者great |
5、正则表达式匹配E-mail地址
用户名@
^([a-zA-Z0-9_\\-\\.\\+]+)@
子域名
([a-zA-Z0-9_\\-\\.]+)
.顶级域名
\\.([a-zA-Z]{2,5})$
二、正则表达式应用实例
1、筛选南京本地号码
要求
#025开头,号码为8位数,号码一般都是以5或者8开头
#中间可以没有空格,区号和号码之间可以有空格,-,区号可以用()括起来
02588888888
0255555555555
025-12345678
(025) 88551234
025 54321678
025ABC88888
01012345678
0125 12345678
025-85321678
算法思路
区号:(025)、025
^(\\(?025\\)?) #筛选以025或(025)开头的字符串
区号与号码之间
[ -]? #筛选区号与号码之间空格、-、或没有字符的字符串
号码
[58][0-9]{7}$ #筛选以5或8开头的,后接7位数结尾的字符串
egrep "^(\\(?025\\)?)[ -]?[58][0-9]{7}$" testhaoma


方法二awk

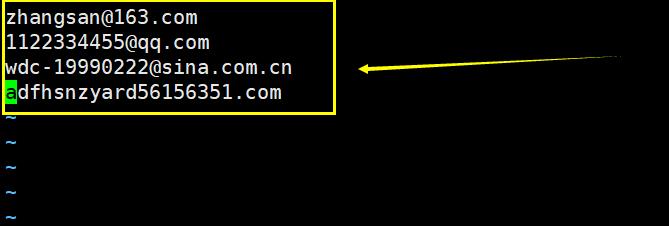
2、邮件
要求
xxxxxx@xxx.com(顶级域)
xxxxxx@xxx.com.cn(二级域.顶级域)
用户名可以是大小写英文字母,数字,中间可携带. - _ # ! 这些符号,写长度不小于6位数
算法思路
用户名@(长度不小于6,可以是大小写字母 数字 - _ . # !)
子域[.二级域]
.顶级域(字符长度一般在2到5)
用户名@
^([A-Za-z0-9\\.\\#\\!\\_\\-]{6,})@
子域[/二级域]
([A-Za-z0-9_\\-\\.]+) #加号代表至少匹配一次,二级域三级域等
顶级域(2-5个字符)
\\.([A-Za-z]{2,5})$
egrep "^([A-Za-z0-9\\.\\#\\!\\_\\-]{6,})@([A-Za-z0-9_\\-\\.]+)\\.([A-Za-z]{2,5})$" 文件名

以上是关于最近学shell,在awk里,在语句的啥位置用正则表达式?例如 awk 'BEGIN FS=";" $4~/root/' testfile的主要内容,如果未能解决你的问题,请参考以下文章