深层神经网络的超参数调试、正则化及优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深层神经网络的超参数调试、正则化及优化相关的知识,希望对你有一定的参考价值。
参考技术A 训练集 ( Training set )作用是用来拟合模型,通过设置分类器的参数,训练分类模型。后续结合验证集作用时,会选出同一参数的不同取值,拟合出多个分类器。
验证集 ( Dev set )
作用是当通过训练集训练出多个模型后,为了能找出效果最佳的模型,使用各个模型对验证集数据进行预测,并记录模型准确率。选出效果最佳的模型所对应的参数,即用来调整模型参数。如svm中的参数c和核函数等。
测试集 ( Test set )
通过训练集和验证集得出最优模型后,使用测试集进行模型预测。用来衡量该最优模型的性能和分类能力。即可以把测试集当做从来不存在的数据集,当已经确定模型参数后,使用测试集进行模型性能评价。
一个有助于理解的形象比喻:
训练集 —— 课本,学生根据课本里的内容来掌握知识。
验证集 —— 作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集 —— 考试,考的题是平常都没有见过,考察学生举一反三的能力。
训练集 直接参与了模型调参的过程,显然不能用来反映模型真实的能力(防止课本死记硬背的学生拥有最好的成绩,即防止 过拟合 ) 。
验证集 参与了人工调参(超参数)的过程,也不能用来最终评判一个模型(刷题库的学生不代表其学习能力强)。
所以要通过最终的考试 (测试集) 来考察一个学生(模型)真正的能力。
如何将只有一个包含m个样例的数据集D,产生出训练集S和测试集T(验证集可以省略)?主要有以下三种方法:
自助法 ( bootstrapping )
给定m个样本的数据集D,我们对它进行采样产生数据集D',每次随机从D中挑选一个样本,将其拷贝入D',然后再将样本放回原始数据集D。显然,该样本在下次采样时任然有可能被采到。这个过程重复m次后,我们就得到了含有m个样本的数据集D',这就是自助采样的结果。 样本有重复采样,也有一次也没有被采到的。从未采到的结果是 ,取极限得到
因此,使用自助法约有1/3的数据集没有被选中过,它们用于测试,这种方式叫“外包估计”。
自助法在数据集小,难以划分训练集、测试集的时候有很大的效果,如果数据集足够大的时候,留出法和交叉验证是更好的选择。
留出法 ( hold-out )
将整个数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T。即,D=S∪T,S∩T=∅。在S上训练出模型,T作为测试集,来评估模型效果。
当样本数据量较小(10000条左右及以下)时,通常取其中70%作为训练集,30%作为测试集;或60%作为训练集,验证集和测试集各20%。
交叉验证法 ( cross validation )
如图所示,交叉验证法的实现流程大致如下:
(1) 将整个数据集分成k个大小相似的子集,即D=D1∪D2∪...∪Dk,Di∩Dj=∅(故又称k折交叉验证法,通常取k=10 )。
(2) 对于每一个模型Mi,算法执行k次,每次选择一个Sj(1≤j≤k)作为测试集,其它作为训练集来训练模型Mi,把训练得到的模型在Sj上进行测试,这样一来,每次都会得到一个误差E,最后对k次得到的误差求平均,就可以得到模型Mi的泛化误差。
(3) 算法选择具有最小泛化误差的模型作为最终模型,并且在整个训练集上再次训练该模型,从而得到最终的模型。
交叉验证的主要的目的是 为了选择不同的模型类型(比如一次线性模型、非线性模型) ,而 不是为了选择具体模型的具体参数 。比如在BP神经网络中,其目的主要为了选择模型的层数、神经元的激活函数、每层模型的神经元个数(即所谓的超参数),每一层网络神经元连接的最终权重是在模型选择(即K折交叉验证)之后,由全部的训练数据重新训练。
假设这就是数据集,显然用简单分类器(如逻辑回归)并不能很好地拟合上述数据。这种情况称为 欠拟合 。
相反地,如果采用一个非常复杂的分类器(如深度神经网络或含有隐藏单元的神经网络),拟合效果会非常好。但与此同时,模型的复杂度也会过高,这种称为 过拟合 。
在两者之间,可能会存在一些复杂程度适中、数据拟合适度的分类器,拟合结果较为合理,称为 适度拟合 。
如上图所示,训练集误差和验证集误差均较高时为 高偏差(欠拟合) 情况;训练集误差较高,验证集误差较高低时为 高方差(过拟合) 情况。
(1) 如何减小偏差(防止欠拟合)
① 增大神经网络规模。
(2) 如何减小方差(防止过拟合)
① 增加数据集样本数量;
② 正则化。
参数 是指神经网络中由数据驱动并进行调整的变量,如𝑊和𝑏。
超参数 是指无需数据驱动,而是在训练前或者训练中人为进行调整的变量。例如算法中的learning rate 𝑎(学习率)、iterations(梯度下降法循环的数量)、𝐿(隐藏层数目)、𝑛[𝑙](隐藏层单元数目)、choice of activation function(激活函数的选择)等都需要人为设置,这些数字实际上控制了最后的参数𝑊和𝑏的值,所以它们被称作超参数。
神经网络中的超参数主要分为三类:网络参数、优化参数、正则化参数。
网络参数
可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
优化参数
一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数等。
正则化参数
权重衰减系数,随机失活比率(dropout)等。
正则化有利于减小训练集和验证集准确率的方差,防止过拟合。在无法增加样本数量或增加样本数量的成本过高时,正则化是一种行之有效的方法。
一般将任意 维向量 的 - 范数定义为
根据定义:
当 时, 的 范数为 ,表示向量 中非0元素的个数。
当 时, 的 范数为 ,等于向量 中所有元素的绝对值之和。
当 时, 的 范数为 ,等于向量 中所有元素的平方和开根号。
正则化(Regularization) 的主要目的是控制模型复杂度,减小过拟合。最基本的正则化方法是在原目标(代价)函数 中添加惩罚项,对复杂度高的模型进行“惩罚”。
对于神经网络模型, 正则化即在其代价函数中添加 正则项:
其中, 。之后再求解优化问题 即可。
假设某三层神经网络存在过拟合问题,采用dropout正则化会遍历网络的每一层,并设置消除该层中每一个节点的概率(比如0.5),最后得到一个节点更少、规模更小的网络,然后再用反向传播方法进行训练,就能有效防止过拟合。
最常用的方法是 inverted dropout(反向随机失活) 。对于一个三层神经网络( ),以第三层为例,实施dropout的步骤如下:
① 定义一个三层dropout矩阵d3:
d3=numpy.random.rand(a3.shape[0],a3.shape[1])
其中,a3表示神经网络第三层的激活函数矩阵。
② 设置 ( )的大小。 表示保留某个隐藏单元的概率。将第①步产生的随机矩阵d3的每个元素与 进行比较,小于置1,大于置0,得到新的d3矩阵(1表示保留该节点,0表示删除该节点)。
③ 将a3与新的d3矩阵相乘(矩阵对应元素相乘),得到新的激活函数矩阵:
a3 =np.multiply(a3,d3)
④ 将新的a3矩阵除以keep-prob:
a3 /= keep_prob
目的是保证a3的期望值(均值)不变,从而保证第三层的输出不变。
① 使用dropout可以使得部分节点失活,可以起到简化神经网络结构的作用,从而起到正则化的作用。
② 因为dropout是使得神经网络的节点随机失活,这样会让神经网络在训练的时候不会使得某一个节点权重过大。因为该节点输入的特征可能会被清除,所以神经网络的节点不能依赖任何输入的特征。dropout最终会产生收缩权重的平方范数的效果,来压缩权重,达到类似于 正则化的效果。
① dropout在测试阶段不需要使用,因为如果在测试阶段使用dropout可能会导致预测值产生随机变化(因为dropout使节点随机失活)。而且,在训练阶段已经将权重参数除以keep-prob来保证输出的期望值不变,所以在测试阶段没必要再使用dropout。
② 神经网络的不同层在使用dropout的时候,keep-prob可以不同。因为可能有的层参数比较多,比较复杂,keep-prob可以小一些,而对于结构比较简单的层,keep-prob的值可以大一些甚至为1,keep-prob等于1表示不使用dropout,即该层的所有节点都保留。
加快训练速度。
对于一个神经网络模型,考虑其代价函数:
如果未归一化输入,其代价函数的形状会较为细长狭窄。在这样的代价函数的限制下,为避免陷入局部最优解,梯度下降法的学习率必须设置得非常小。
如果归一化输入,代价函数便呈现球形轮廓。这种情况下,不论从哪个位置开始梯度下降法,都能使用较大的学习率,从而更快速、直接地找到全局最优解。
对于包含n个特征的m个样本的数据集,其输入归一化的过程主要分为两步:
① 零均值化
② 归一化方差
其中, 代表第 个样本的特征矩阵。
训练集、验证集、测试集特征矩阵的平均值 和标准差 要保持一致,确保它们归一化后符合同一分布。
深度学习 吴恩达 Andrew Ng
1.神经网络和深度学习
课程地址:https://mooc.study.163.com/course/2001281002#/info
2.改善深层神经网络:超参数调试、正则化以及优化
3.结构化机器学习项目
4.卷积神经网络
卷积神经网络
- 卷积 以边缘检测为例,说明了不同的滤波器filter可以检测出,不同的形状。
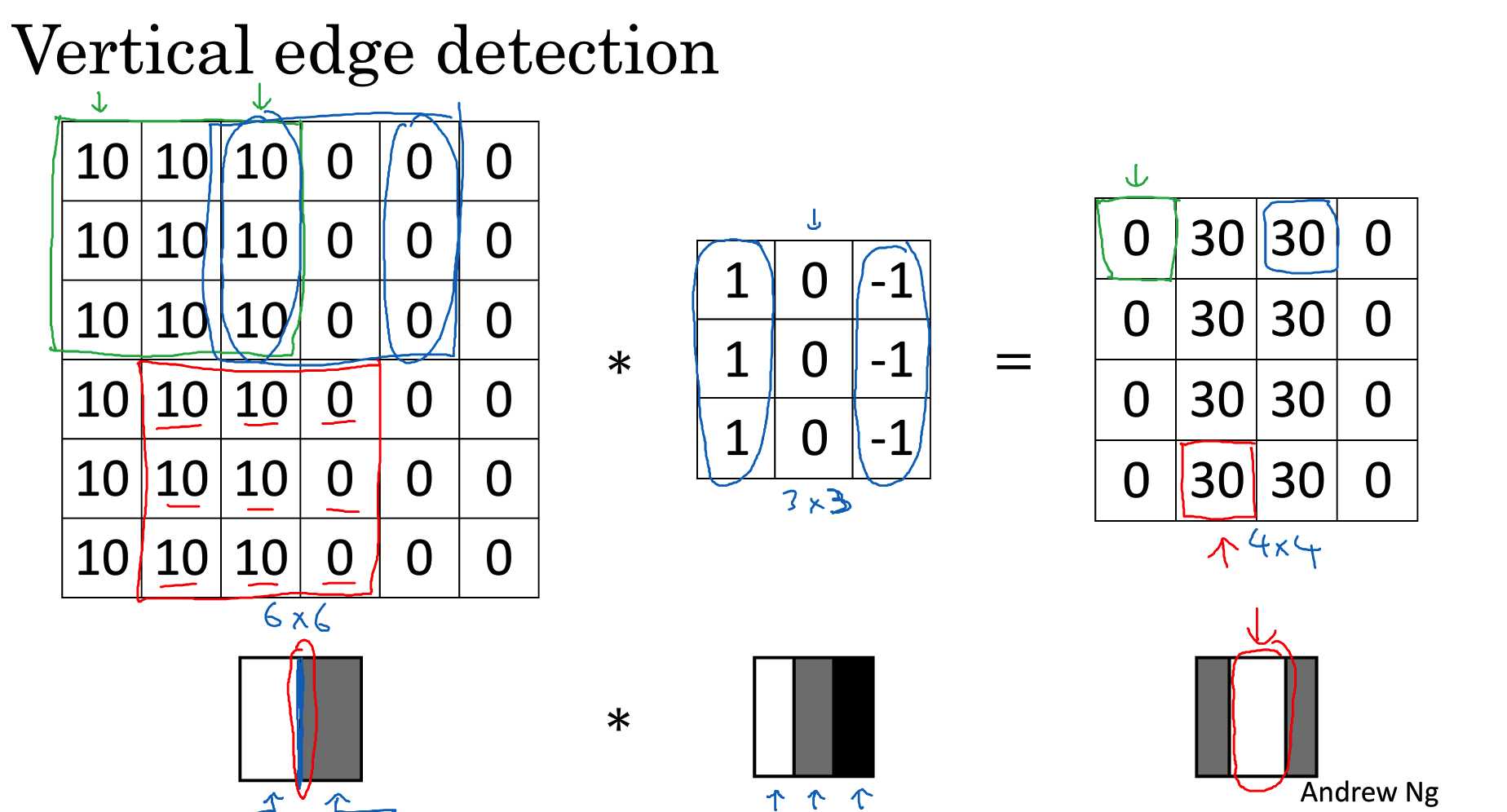
检测出前者的图片中间的垂直结构。
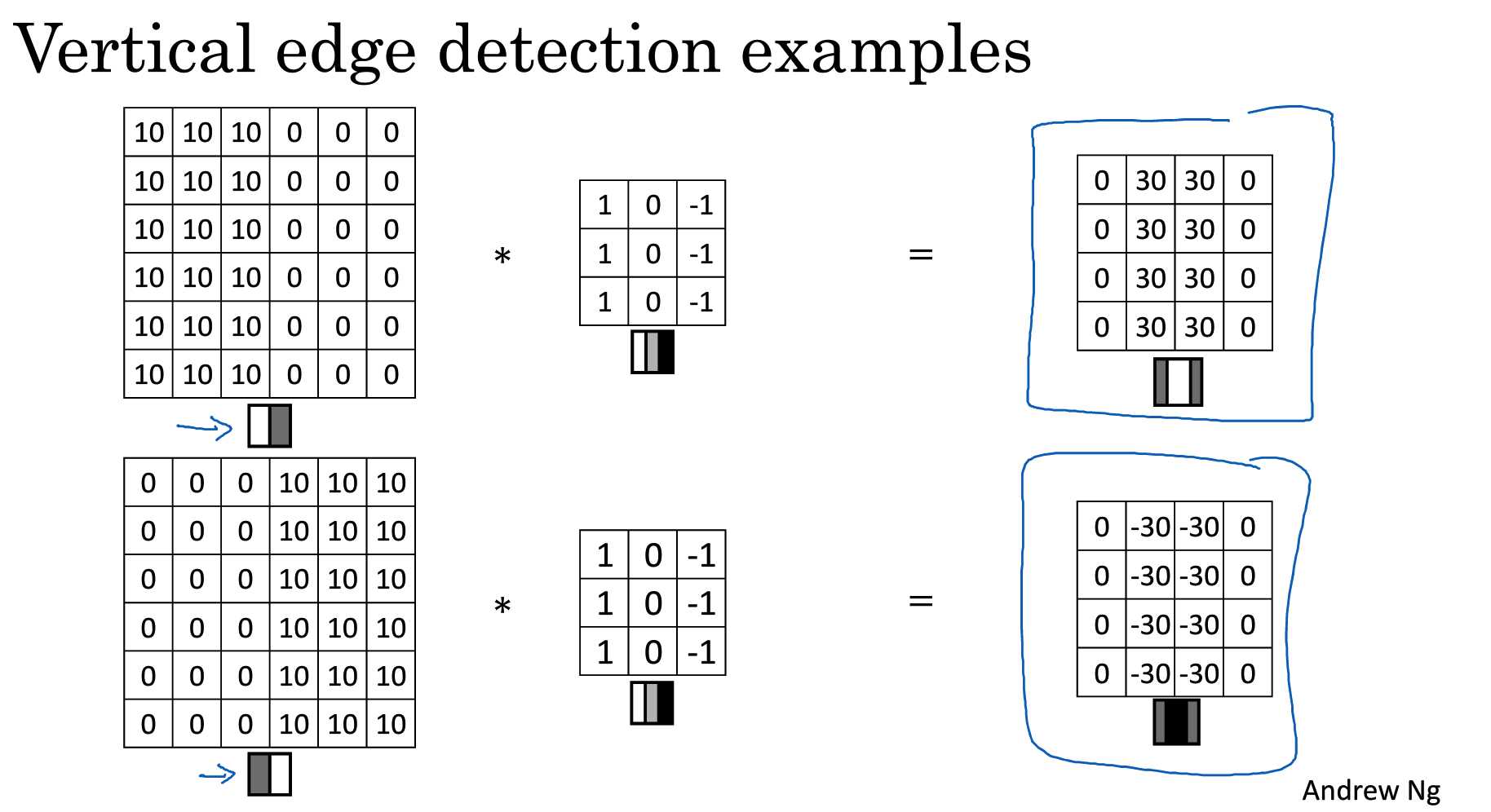
垂直边缘滤波器加测出图片中的垂直结构。
水平边缘加测。
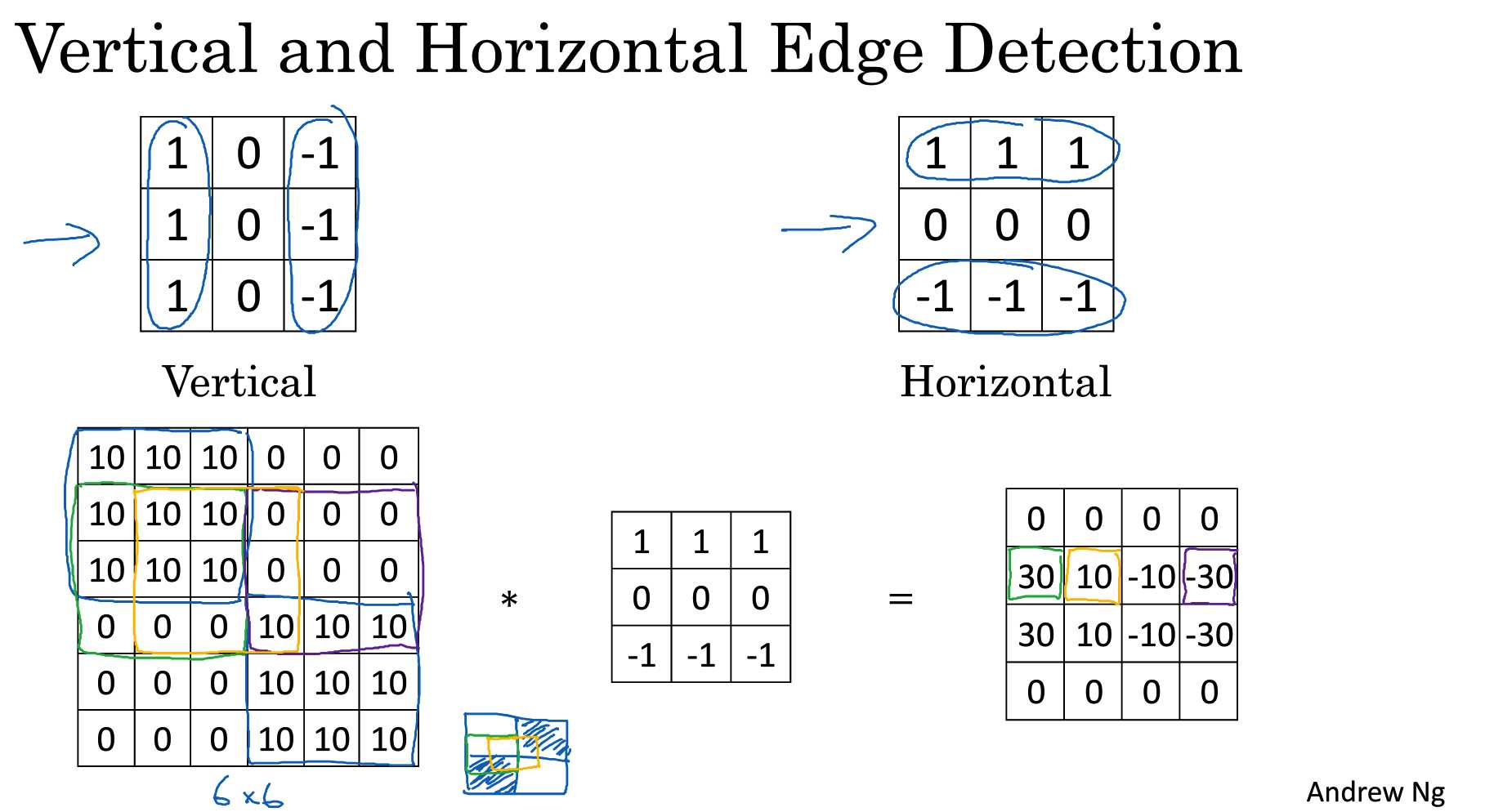
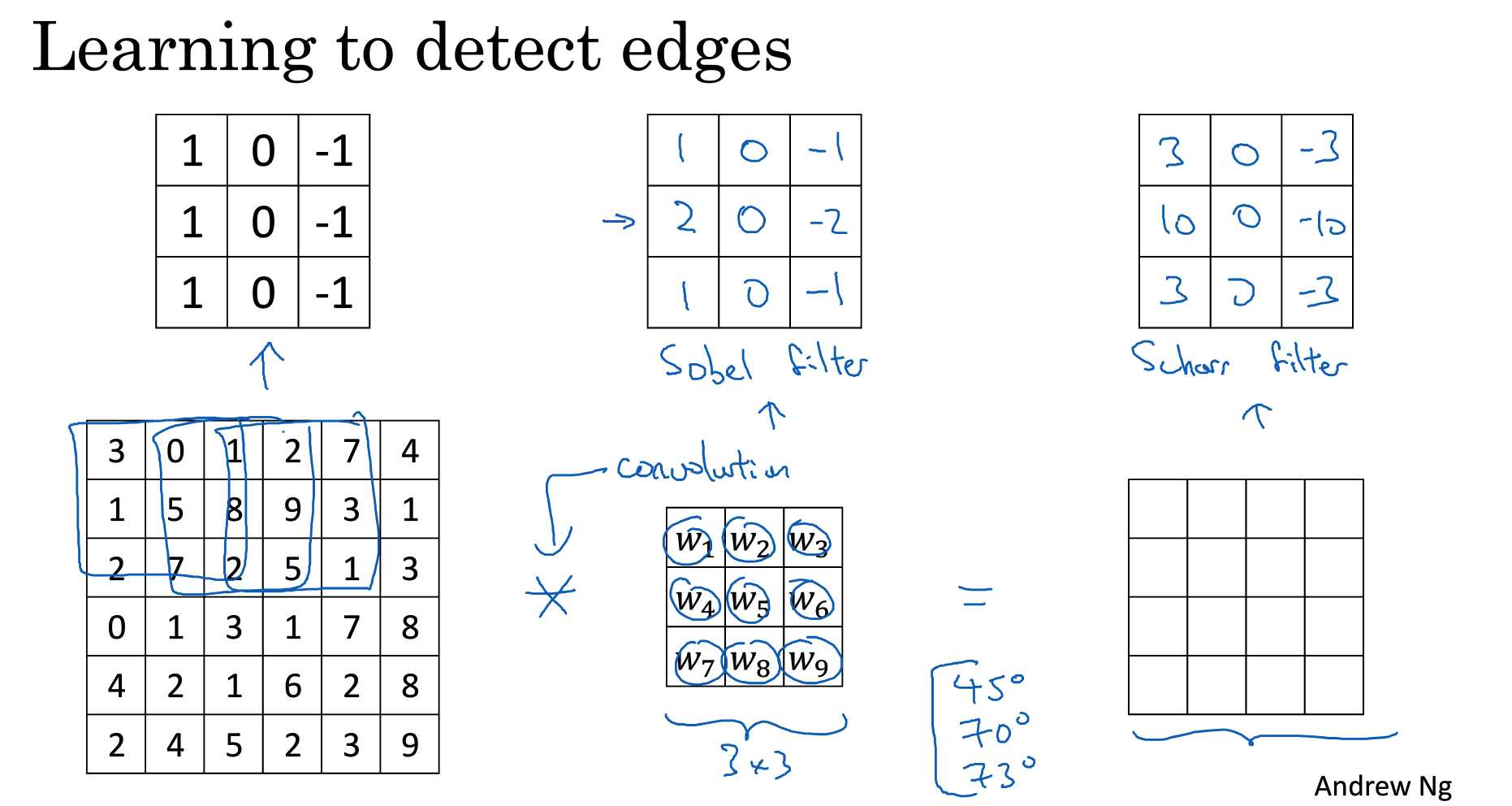
不同的滤波器会学习到不同的检测结构, 反向传播可以学习9个参数,可以检测出更加复杂的结构。
padding:为了卷积到更多的信息,我们会给原来的篇填充一些额外的东西。
1.Valid convolutions : no padding
2.Same convolutions: 卷积前后图片大小不变 padding
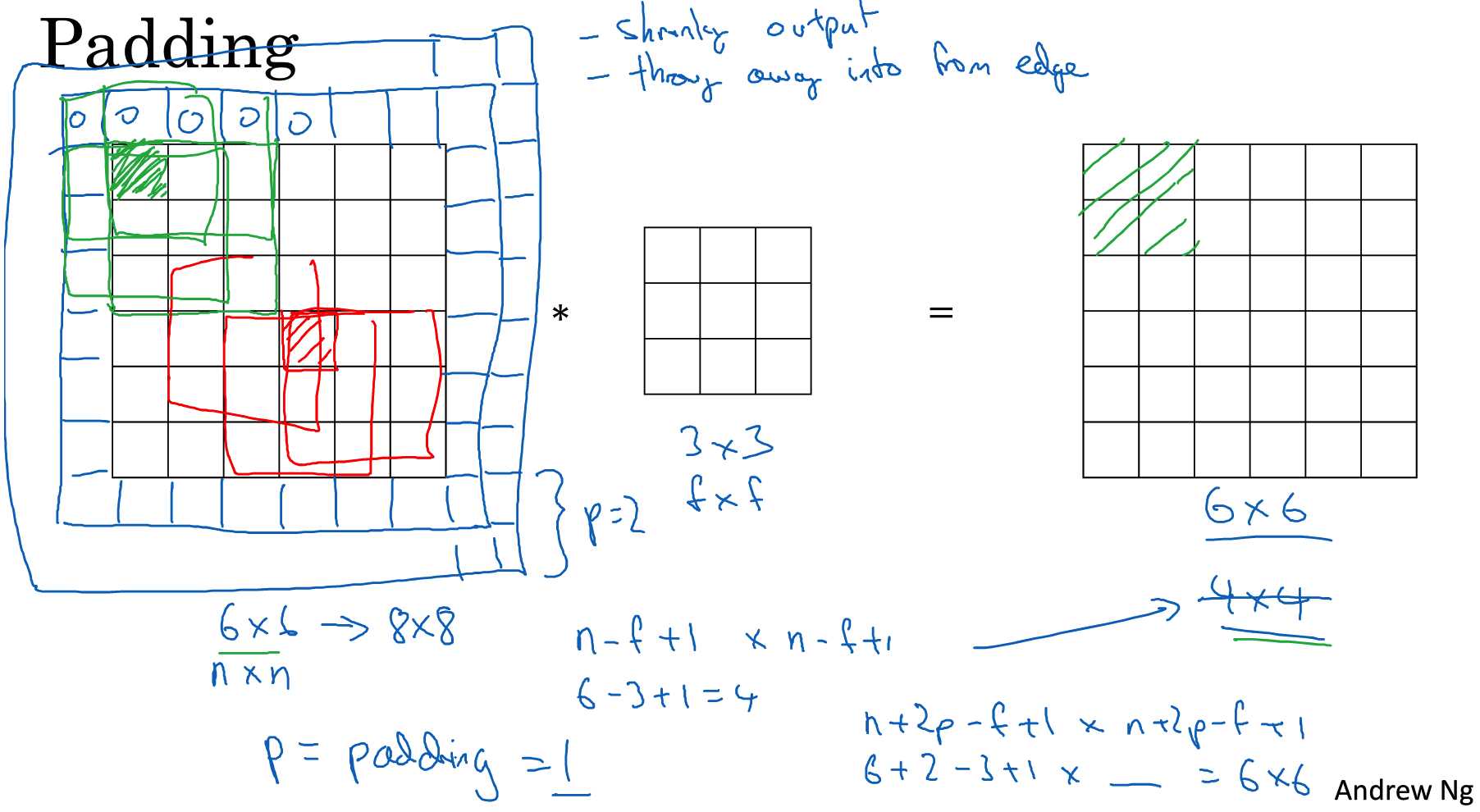
考虑步长 和 padding的 卷积:

立体图形的卷积:
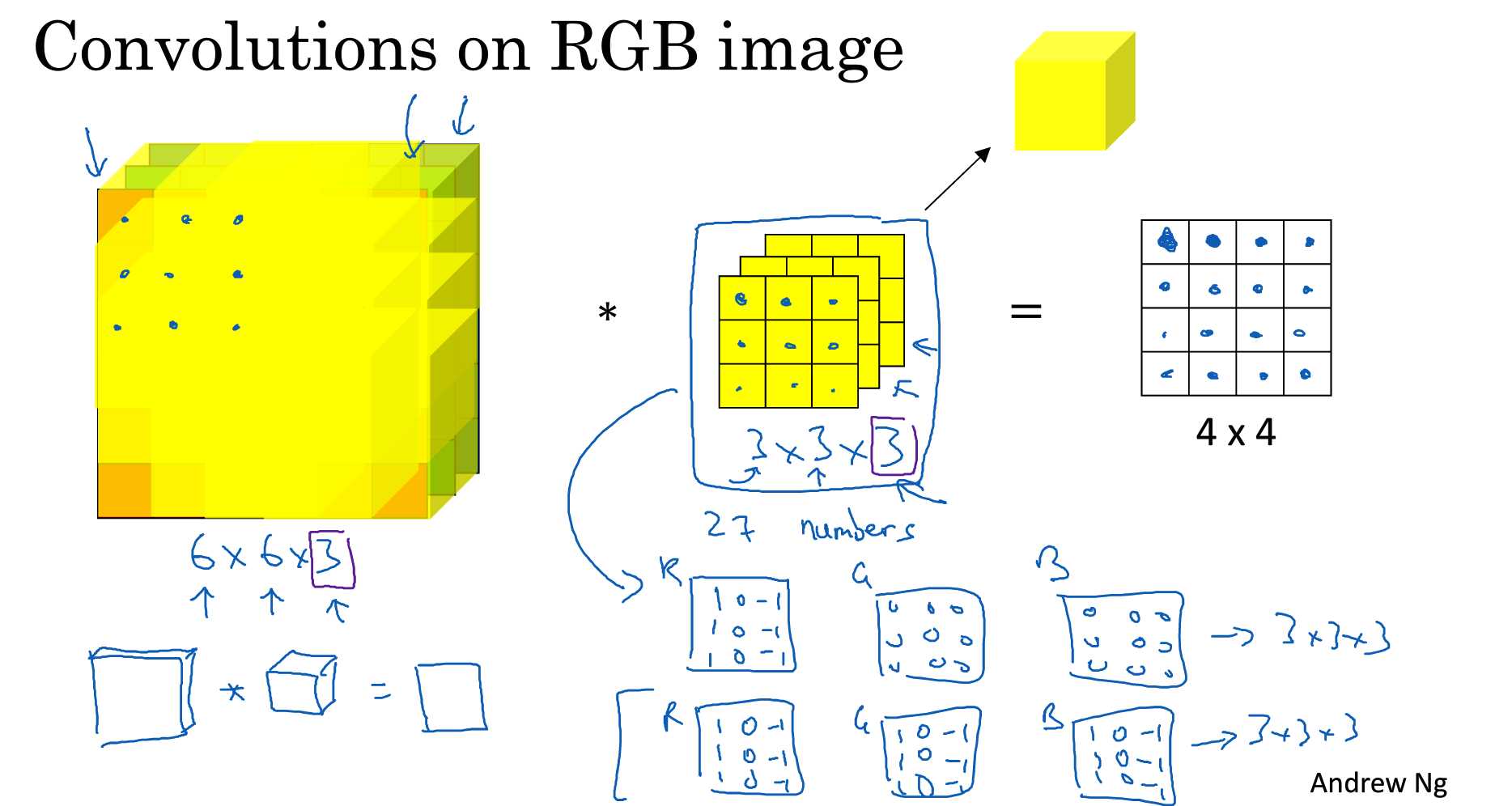
多卷积:
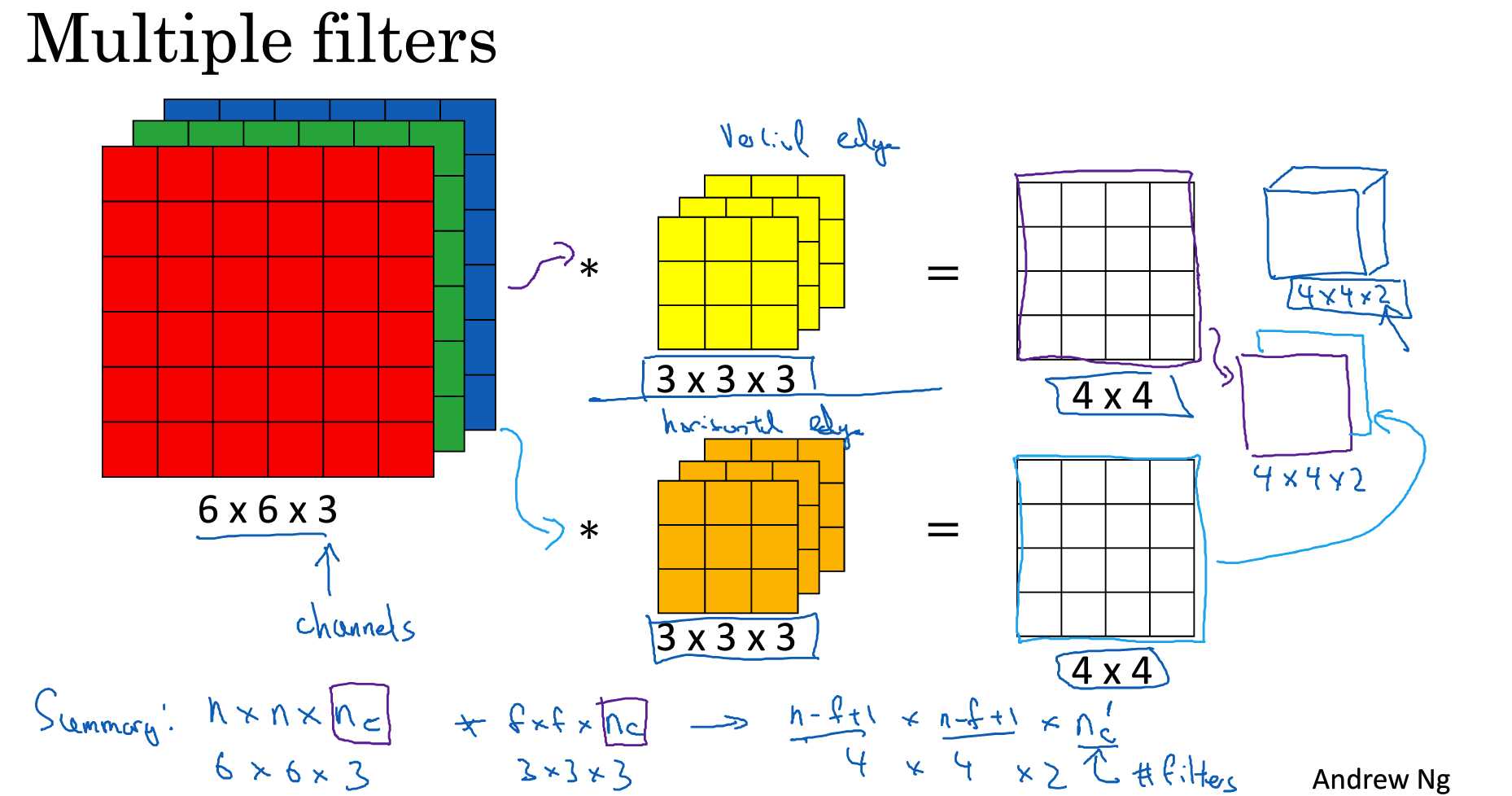
立体卷积 用 多层滤波器 然后将多层的数据加起来。所以导致得到的结构都是1层的数据
一层卷积神经网络的实现:
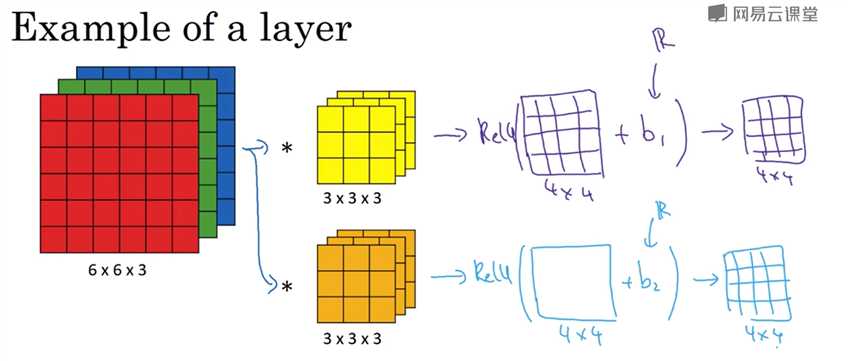
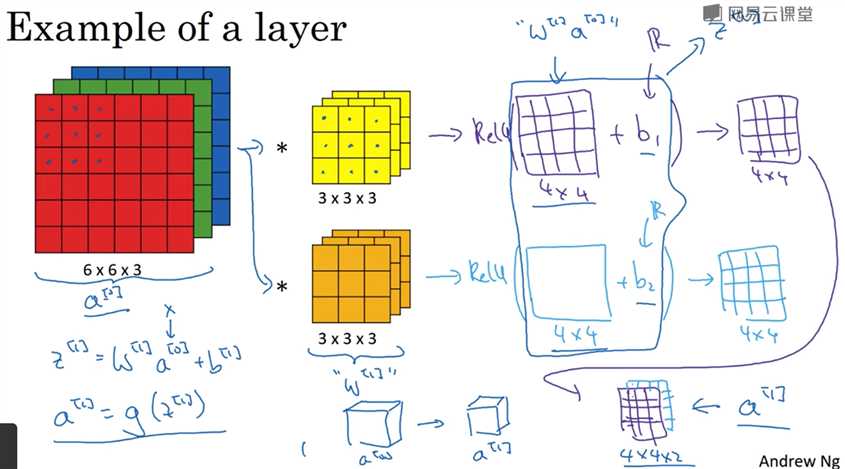
多个filter会防止过拟合

信道不断增加
- 池化:缩小模型的大小、提高计算速度
5.序列模型
以上是关于深层神经网络的超参数调试、正则化及优化的主要内容,如果未能解决你的问题,请参考以下文章