CSS 之渲染原理及优化策略
Posted 架构师日刊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSS 之渲染原理及优化策略相关的知识,希望对你有一定的参考价值。

大家好,我是你们的导师,我每天都会在这里给大家分享一些干货内容(当然了,周末也要允许老师休息一下哈)。上次老师跟大家分享了Vue 之Flask实现全栈单页面应用的知识,今天跟大家分享下CSS 之渲染原理及优化策略的知识。
提起 CSS 很多童鞋都很不屑,尤其是看到 RedMonk 2019 Programming Language Rankings 的时候,CSS 竟然排到了第七位。
我们先来看看这张排行榜:
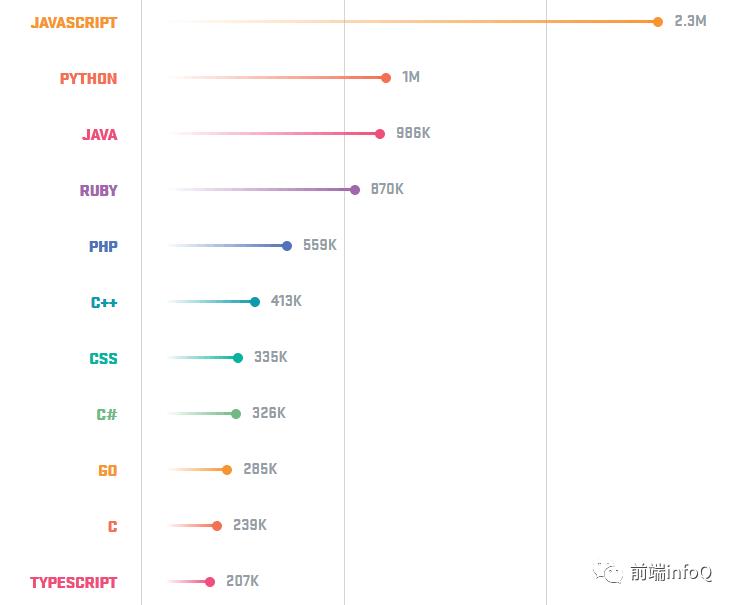
既然 CSS 这么重要,那么我们花点时间来研究相关原理也就物有所值了。
本节我们就来说说 CSS 渲染以及优化相关的内容,主要围绕以下几点,由浅入深,了解来龙去脉:
-
浏览器构成 -
渲染引擎 -
CSS 特性 -
CSS 语法解析过程 -
CSS 选择器执行顺序 -
高效的 ComputedStyle -
CSS 书写顺序对性能有影响吗 -
优化策略
浏览器构成
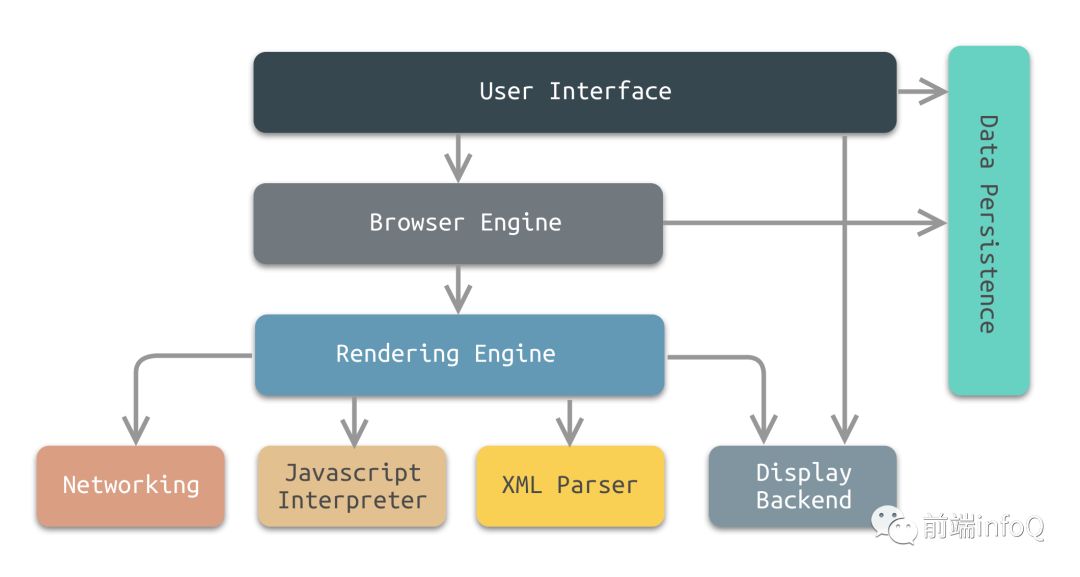
-
User Interface:
-
Browser engine:
浏览器引擎,可以在用户界面和渲染引擎之间传送指令或在客户端本地缓存中读写数据,是浏览器各个部分之间相互通信的核心。
-
Rendering engine:
渲染引擎,解析 DOM 文档和 CSS 规则并将内容排版到浏览器中显示有样式的界面,也就是排版引擎,我们常说的浏览器内核主要指的就是渲染引擎。
-
Networking:
网络功能模块,是浏览器开启网络线程发送请求以及下载资源的模块。
-
JavaScript Interpreter:
JS 引擎,解释和执行 JS 脚本部分,例如 V8 引擎。
-
UI Backend:
UI 后端则是用于绘制基本的浏览器窗口内控件,比如组合选择框、按钮、输入框等。
-
Data Persistence:
数据持久化存储,涉及 Cookie、LocalStorage 等一些客户端存储技术,可以通过浏览器引擎提供的 API 进行调用。
渲染引擎
渲染引擎,解析 DOM 文档和 CSS 规则并将内容排版到浏览器中显示有样式的界面,也就是排版引擎,我们常说的浏览器内核主要指的就是渲染引擎。
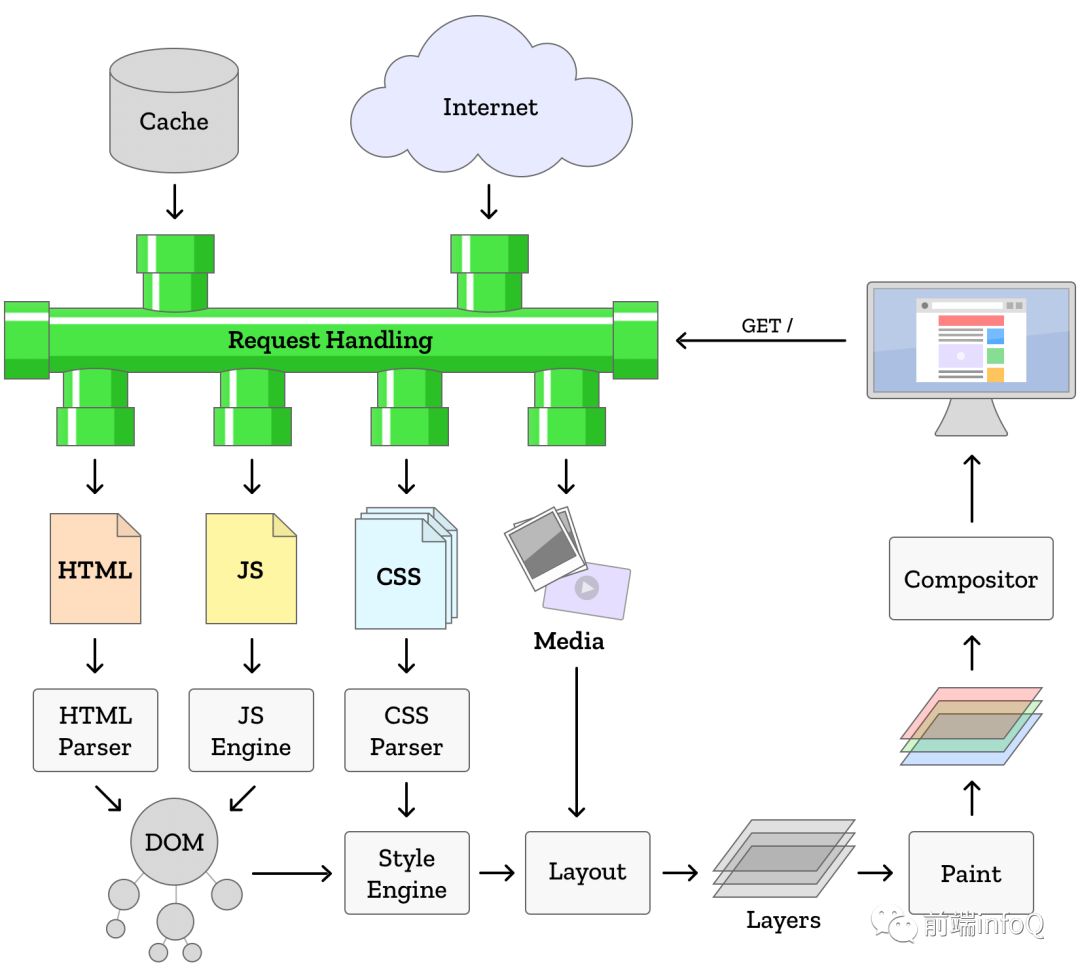
上图中,我们需要关注两条主线:
其一,html Parser 生成的 DOM 树;
其二,CSS Parser 生成的 Style Rules(CSSOM 树);
在这之后,DOM 树与 Style Rules 会生成一个新的对象,也就是我们常说的 Render Tree渲染树,结合 Layout 绘制在屏幕上,从而展现出来。
CSS 特性
1.优先级

| 选择器 | 权重 |
|---|---|
| !important | 1/0(无穷大) |
| 内联样式 | 1000 |
| ID | 100 |
| 类/伪类/属性 | 10 |
| 元素/伪元素 | 1 |
| 通配符/子选择器/相邻选择器 | 0 |
!important > 行内样式(权重1000) > ID 选择器(权重 100) > 类选择器(权重 10) > 标签(权重1) > 通配符 > 继承 > 浏览器默认属性示例代码一:
<div ><p id="box" class="text">Jartto's blog</p></div><style>#box{color: red;}.text{color: yellow;}</style>
猜一猜,文本会显示什么颜色?当你知道 「ID 选择器 > 类选择器 」的时候,答案不言自明。
升级一下:
<div id="box"><p class="text">Jartto's blog</p></div><style>#box{color: red;}.text{color: blue;}</style>
这里就考查到了规则「类选择器 > 继承」,ID 对文本来说是继承过来的属性,所以优先级不如直接作用在元素上面的类选择器。
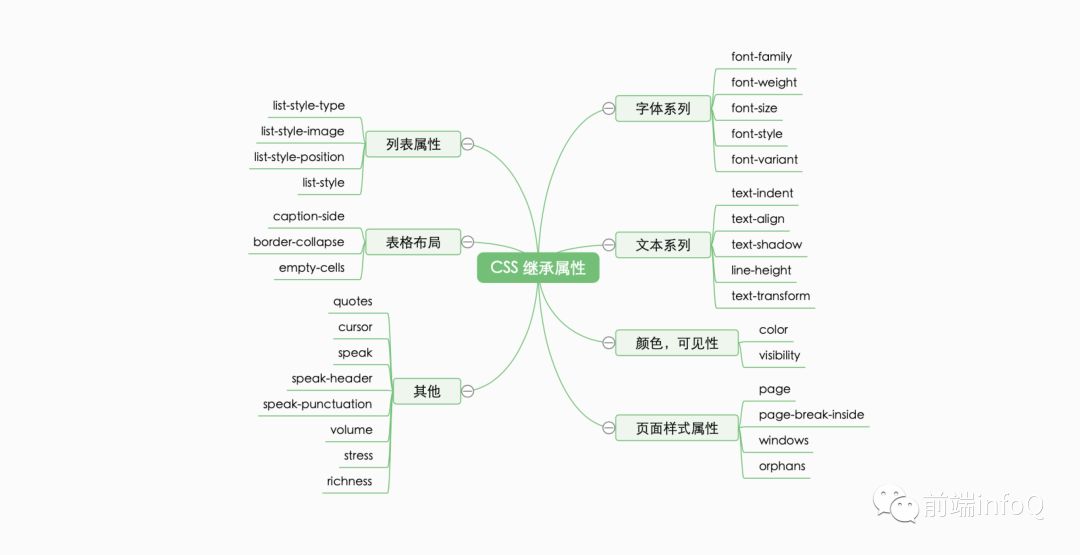
2.继承性
-
继承得到的样式的优先级是最低的,在任何时候,只要元素本身有同属性的样式定义,就可以覆盖掉继承值。
-
在存在多个继承样式时,层级关系距离当前元素最近的父级元素的继承样式,具有相对最高的优先级。
有哪些属性是可以继承的呢,我们简单分一下类:
-
font-family、font-size、font-weight 等 f 开头的 CSS 样式。 -
text-align、text-indent 等 t 开头的样式。 -
color。
详细的规则,请看下图:
示例代码二:
<div><ol><li> Jartto's blog </li></ol></div><style>div { color : red; }ol { color : green; }</style>
增加了 !important,猜一猜,文本显示什么颜色?
3.层叠性
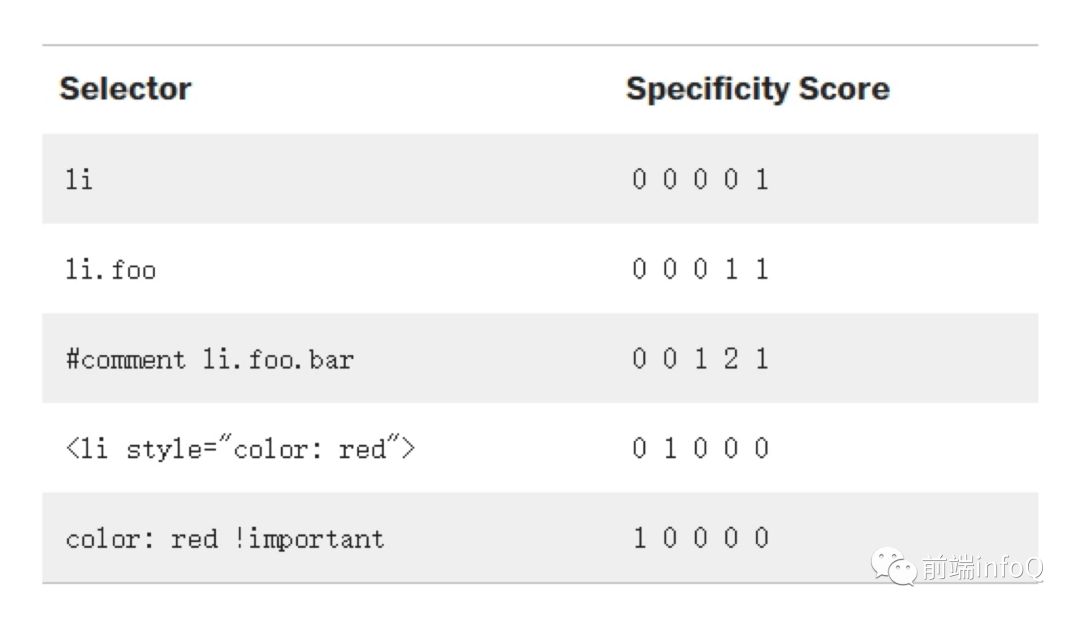
层叠就是浏览器对多个样式来源进行叠加,最终确定结果的过程。
CSS 之所以有「层叠」的概念,是因为有多个样式来源。
CSS 层叠性是指 CSS 样式在针对同一元素配置同一属性时,依据层叠规则(权重)来处理冲突,选择应用权重高的 CSS 选择器所指定的属性,一般也被描述为权重高的覆盖权重低的,因此也称作层叠。
示例代码三:
<div ><p class="two one">Jartto's blog</p></div><style>.one{color: red;}.two{color: blue;}<style>
如果两个类选择器同时作用呢,究竟以谁为准?这里我们要考虑样式表中两个类选择器的先后顺序,后面的会覆盖前面的,所以文本当然显示蓝色了。
升级代码:
<div><div><div>Jartto's blog</div></div></div><style>div div div { color: green; }div div { color: red; }div { color: yellow; }<style>
这个比较直接,算一下权重,谁大听谁的。
继续升级:
<div id="box1" class="one"><div id="box2" class="two"><div id="box3" class="three"> Jartto's blog </div></div></div><style>.one .two div { color : red; }div #box3 { color : yellow; }#box1 div { color : blue; }</style>
权重:
0 0 2 10 1 0 10 1 0 1
验证一下:
<div id="box1" class="one"><div id="box2" class="two"><div id="box3" class="three"> Jartto's blog </div></div></div><style>.one .two div { color : red; }#box1 div { color : blue; }div .three { color : green; }</style>
权重:
0 0 2 10 1 0 10 0 1 1
如果你对上面这些问题都了如指掌,那么恭喜你,基础部分顺利过关,可以继续升级了!
CSS 语法解析过程
1.我们来把 CSS 拎出来看一下,HTML Parser 会生成 DOM 树,而 CSS Parser 会将解析结果附加到 DOM 树上,如下图:
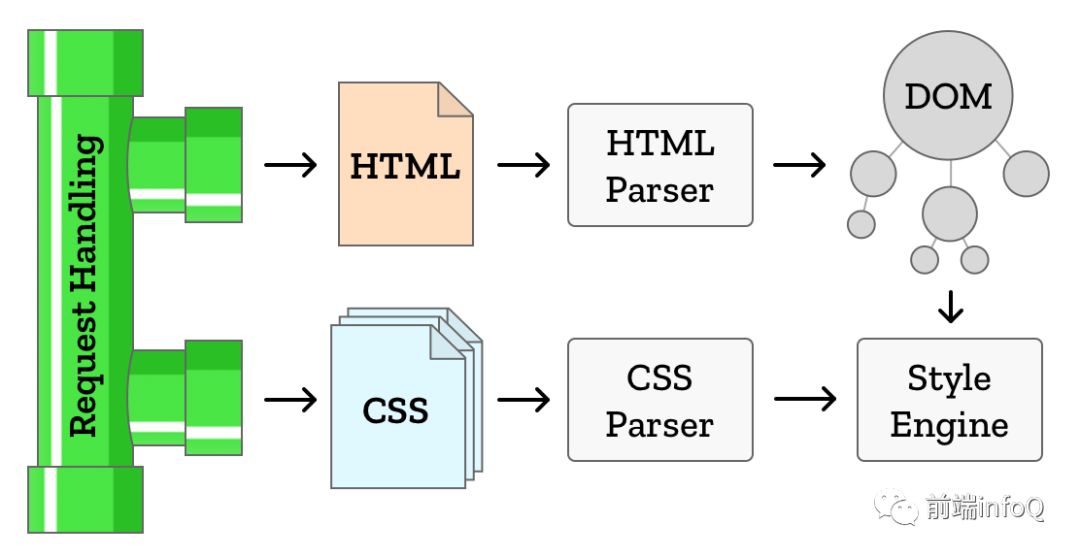
2.CSS 有自己的规则,一般如下:WebKit 使用 Flex 和 Bison 解析器生成器,通过 CSS语法文件自动创建解析器。Bison 会创建自下而上的移位归约解析器。Firefox 使用的是人工编写的自上而下的解析器。
这两种解析器都会将 CSS 文件解析成 StyleSheet 对象,且每个对象都包含 CSS 规则。CSS 规则对象则包含选择器和声明对象,以及其他与 CSS 语法对应的对象。

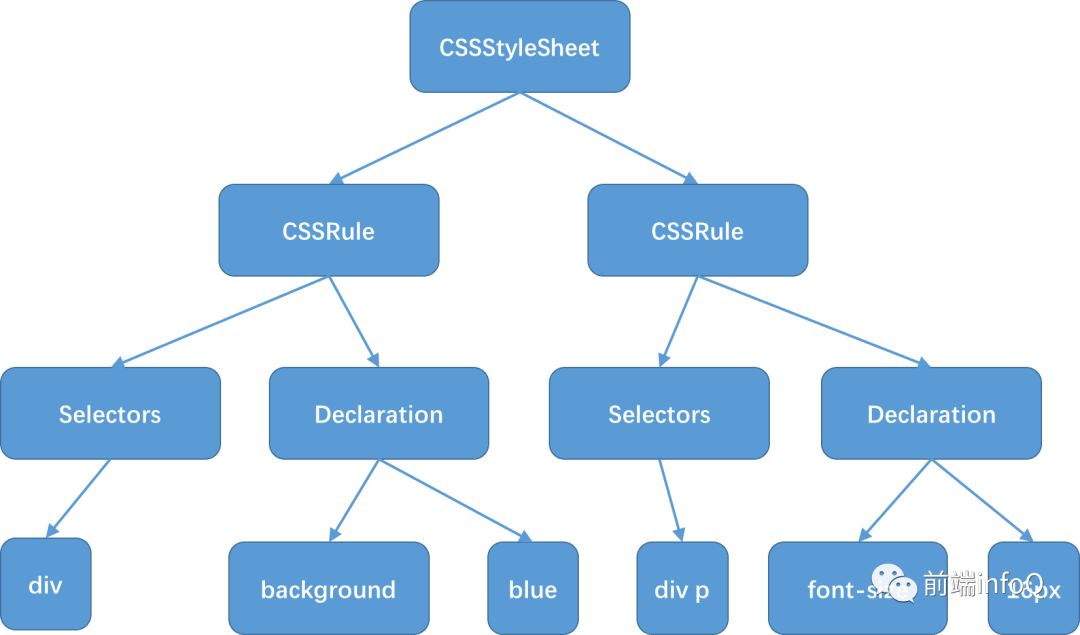
3.CSS 解析过程会按照 Rule,Declaration 来操作:
4.那么他是如何解析的呢,我们不妨打印一下 CSS Rules:
控制台输入:
document.styleSheets[0].cssRules打印出来的结果大致分为几类:
-
cssText:存储当前节点规则字符串 -
parentRule:父节点的规则 -
parentStyleSheet:包含 cssRules,ownerNode,rules 规则 -
…
规则貌似有点看不懂,不用着急,我们接着往下看。
5.CSS 解析和 Webkit 有什么关系?
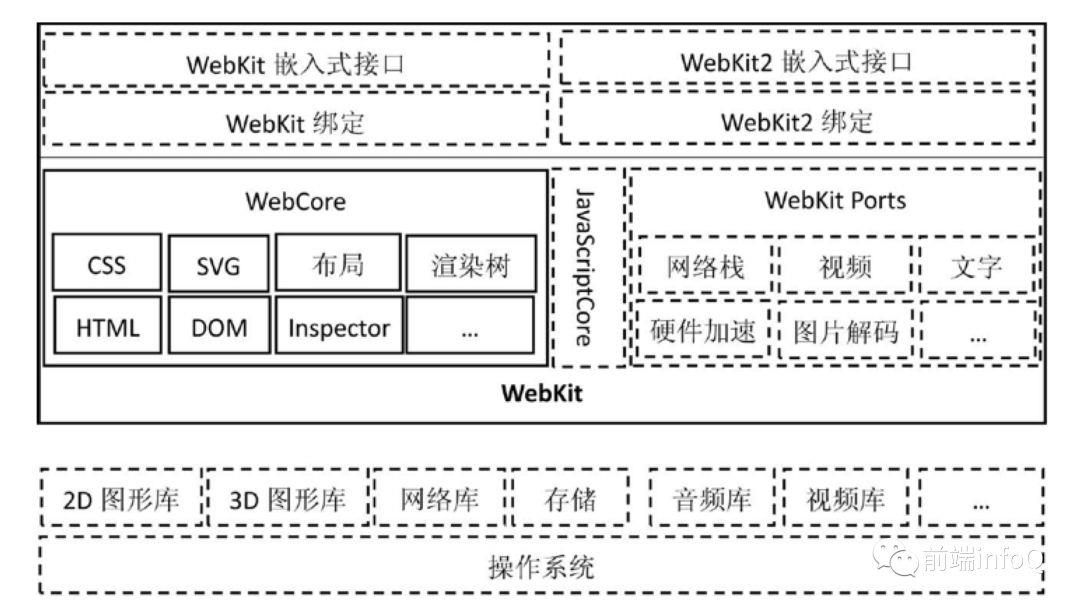
CSS 依赖 WebCore 来解析,而 WebCore 又是 Webkit 非常重要的一个模块。
要了解 WebCore 是如何解析的,我们需要查看相关源码:
CSSRule* CSSParser::createStyleRule(CSSSelector* selector){CSSStyleRule* rule = 0;if (selector) {rule = new CSSStyleRule(styleElement);m_parsedStyleObjects.append(rule);rule->setSelector(sinkFloatingSelector(selector));rule->setDeclaration(new CSSMutableStyleDeclaration(rule, parsedProperties, numParsedProperties));}clearProperties();return rule;}
从该函数的实现可以很清楚的看到,解析器达到某条件需要创建一个 CSSStyleRule 的时候将调用该函数,该函数的功能是创建一个 CSSStyleRule,并将其添加已解析的样式对象列表m_parsedStyleObjects 中去,这里的对象就是指的 Rule。
注意:源码是为了参考理解,不需要逐行阅读!
Webkit 使用了自动代码生成工具生成了相应的代码,也就是说词法分析和语法分析这部分代码是自动生成的,而 Webkit 中实现的 CallBack 函数就是在 CSSParser 中。
这时候就不得不提到 AST 了,我们继续剖析。
补充阅读:Webkit 对 CSS 支持
6.关于 AST

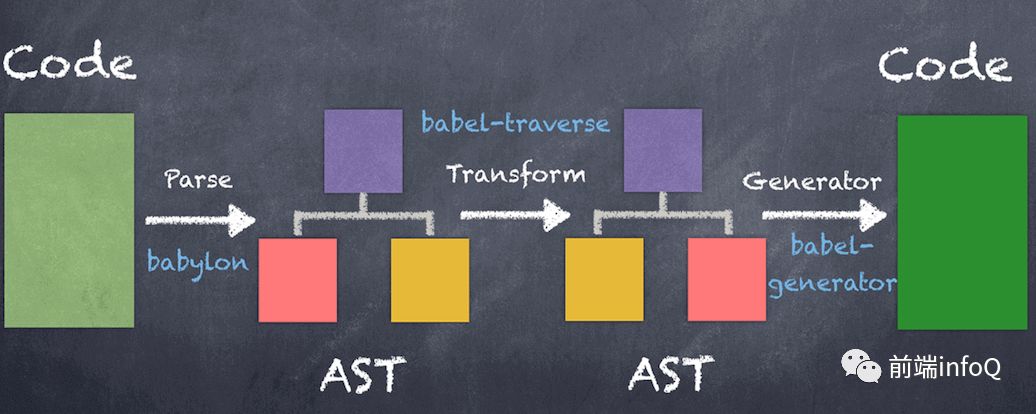
如果对 AST 还不了解,请移步 AST 抽象语法树。这里我们不做过多解释,主要围绕如何解析这一过程展开,先来看一张 Babel 转换过程图:
我们来举一个简单的例子,声明一个箭头函数,如下:
let jarttoTest = () => {// Todo}
通过在线编译,生成如下结果:
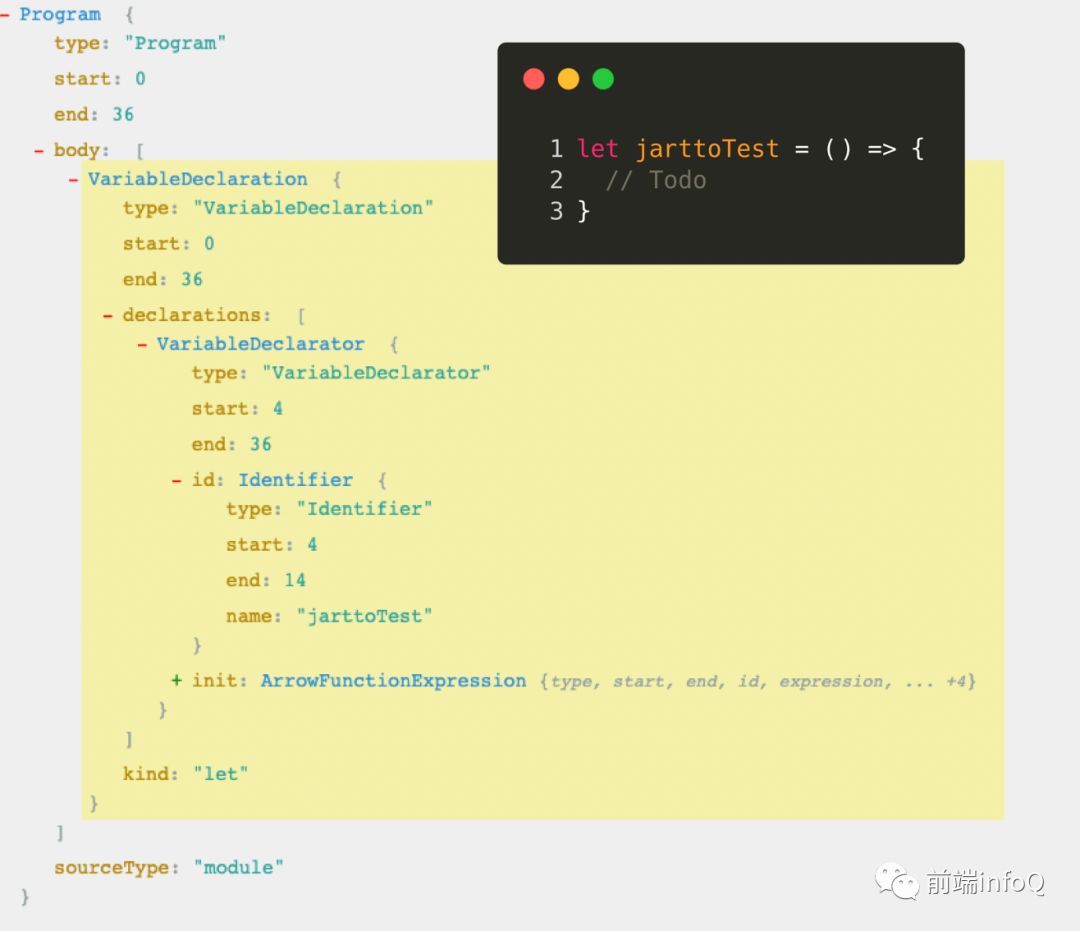
从上图我们可以看出:我们的箭头函数被解析成了一段标准代码,包含了类型,起始位置,结束位置,变量声明的类型,变量名,函数名,箭头函数表达式等等。
标准的解析代码,我们可以对其进行一些加工和处理,之后通过相应 API 输出。
很多场景都会用到这个过程,如:
-
JS 反编译,语法解析。 -
Babel 编译 ES6 语法。 -
代码高亮。 -
关键字匹配。 -
作用域判断。 -
代码压缩。 -
…
场景千千万,但是都离不开一个过程,那就是:
AST 转换过程:解析 - 转换 - 生成
到这里,CSS 如何解析的来龙去脉我们已经非常清楚了,可以回到文章开头的那个流程图了,相信你一定会有另一翻感悟。
CSS 选择器执行顺序
渲染引擎解析 CSS 选择器时是从右往左解析,这是为什么呢?举个例子:
<div><div class="jartto"><p><span> 111 </span></p><p><span> 222 </span></p><p><span> 333 </span></p><p><span class='yellow'> 444 </span></p></div></div><style>div > div.jartto p span.yellow {color: yellow;}</style>
我们按照「从左到右」的方式进行分析:
-
先找到所有 div 节点。 -
在 div 节点内找到所有的子 div,并且是 class = “jartto”。 -
然后再依次匹配 p span.yellow 等情况。 -
遇到不匹配的情况,就必须回溯到一开始搜索的 div 或者 p 节点,然后去搜索下个节点,重复这样的过程。
这样的搜索过程对于一个只是匹配很少节点的选择器来说,效率是极低的,因为我们花费了大量的时间在回溯匹配不符合规则的节点。
我们按照「从右向左」的方式进行分析:
-
首先就查找到 class=“yellow” 的 span 元素。 -
接着检测父节点是否为 p 元素,如果不是则进入同级其他节点的遍历,如果是则继续匹配父节点满足 class=“jartto” 的 div 容器。 -
这样就又减少了集合的元素,只有符合当前的子规则才会匹配再上一条子规则。
综上所述,我们可以得出结论:
浏览器 CSS 匹配核心算法的规则是以从右向左方式匹配节点的。
这样做是为了减少无效匹配次数,从而匹配快、性能更优。
所以,我们在书写 CSS Selector 时,从右向左的 Selector Term 匹配节点越少越好。
不同 CSS 解析器对 CSS Rules 解析速度差异也很大,感兴趣的童鞋可以看看 CSS 解析引擎,这里不再赘述。
高效的 ComputedStyle
浏览器还有一个非常棒的策略,在特定情况下,浏览器会共享 Computed Style,网页中能共享的标签非常多,所以能极大的提升执行效率!
如果能共享,那就不需要执行匹配算法了,执行效率自然非常高。
如果两个或多个 Element 的 ComputedStyle 不通过计算可以确认他们相等,那么这些 ComputedStyle 相等的 Elements 只会计算一次样式,其余的仅仅共享该 ComputedStyle。
<section class="one"><p class="desc">One</p></section><section class="one"><p class="desc">two</p></section>
如何高效共享 Computed Style ?
-
TagName 和 Class 属性必须一样。 -
不能有 Style 属性。哪怕 Style 属性相等,他们也不共享。 -
3.不能使用 Sibling selector,譬如: first-child、 :last-selector、 + selector。 -
4.mappedAttribute 必须相等。
为了更好的说明,我们再举两个例子:
不能共享,上述规则 2:
<p style="color:red">jartto's</p><p style="color:red">blog</p>
可以共享,上述规则 4:
<p align="middle">jartto's</p><p align="middle">blog</p>
到这里,相信你对 ComputedStyle 有了更多的认识,代码也就更加精炼和高效了。
CSS 书写顺序对性能有影响吗?
需要注意的是:浏览器并不是一获取到 CSS 样式就立马开始解析,而是根据 CSS 样式的书写顺序将之按照 DOM 树的结构分布渲染样式,然后开始遍历每个树结点的 CSS 样式进行解析,此时的 CSS 样式的遍历顺序完全是按照之前的书写顺序。
在解析过程中,一旦浏览器发现某个元素的定位变化影响布局,则需要倒回去重新渲染。
我们来看看下面这个代码片段:
width: 150px;height: 150px;font-size: 24px;position: absolute;
当浏览器解析到 position 的时候突然发现该元素是绝对定位元素需要脱离文档流,而之前却是按照普通元素进行解析的,所以不得不重新渲染。
渲染引擎首先解除该元素在文档中所占位置,这就导致了该元素的占位情况发生了变化,其他元素可能会受到它回流的影响而重新排位。
我们对代码进行调整:
position: absolute;width: 150px;height: 150px;font-size: 24px;
这样就能让渲染引擎更高效的工作,可是问题来了:
在实际开发过程中,我们如何能保证自己的书写顺序是最优呢?
这里有一个规范,建议顺序大致如下:
定位属性
position display float left top right bottom overflow clear z-index自身属性
width height padding border margin background文字样式
font-family font-size font-style font-weight font-varient color文本属性
text-align vertical-align text-wrap text-transform text-indent text-decoration letter-spacing word-spacing white-space text-overflowCSS3 中新增属性
content box-shadow border-radius transform当然,我们需要知道这个规则就够了,剩下的可以交给一些插件去做,譬如 CSSLint(能用代码实现的,千万不要去浪费人力)。
优化策略
我们从浏览器构成,聊到了渲染引擎,再到 CSS 的解析原理,最后到执行顺序,做了一系列的探索。期望大家能从 CSS 的渲染原理中了解整个过程,从而写出更高效的代码。
1. 使用 id selector 非常的高效
在使用 id selector 的时候需要注意一点:因为 id 是唯一的,所以不需要既指定 id 又指定 tagName:
/* Bad */p#id1 {color:red;}/* Good */#id1 {color:red;}
2. 避免深层次的 node
譬如:
/* Bad */div > div > div > p {color:red;}/* Good */p-class{color:red;}
3. 不要使用 attribute selector
如:p[att1=”val1”],这样的匹配非常慢。更不要这样写:p[id="id1"],这样将 id selector 退化成 attribute selector。
/* Bad */p[id="jartto"]{color:red;}p[class="blog"]{color:red;}/* Good */#jartto{color:red;}.blog{color:red;}
4. 将浏览器前缀置于前面,将标准样式属性置于最后
类似:
.foo {-moz-border-radius: 5px;border-radius: 5px;}
可以参考这个 Css 规范。
5. 遵守 CSSLint 规则
font-faces 不能使用超过5个web字体import 禁止使用@importregex-selectors 禁止使用属性选择器中的正则表达式选择器universal-selector 禁止使用通用选择器*unqualified-attributes 禁止使用不规范的属性选择器zero-units 0后面不要加单位overqualified-elements 使用相邻选择器时,不要使用不必要的选择器shorthand 简写样式属性duplicate-background-images 相同的url在样式表中不超过一次
6. 减少 CSS 文档体积
-
移除空的 CSS规则(Remove empty rules)。 -
值为 0不需要单位。 -
使用缩写。 -
属性值为浮动小数 0.xx,可以省略小数点之前的0。 -
不给 h1-h6元素定义过多的样式。
7. CSS Will Change
WillChange 属性,允许作者提前告知浏览器的默认样式,使用一个专用的属性来通知浏览器留意接下来的变化,从而优化和分配内存。
8. 不要使用 @import
使用 @import 引入 CSS 会影响浏览器的并行下载。
使用 @import 引用的 CSS 文件只有在引用它的那个 CSS 文件被下载、解析之后,浏览器才会知道还有另外一个 CSS 需要下载,这时才去下载,然后下载后开始解析、构建 Render Tree 等一系列操作。
多个 @import 会导致下载顺序紊乱。在 IE 中,@import 会引发资源文件的下载顺序被打乱,即排列在 @import 后面的 JS 文件先于 @import 下载,并且打乱甚至破坏 @import自身的并行下载。
9. 避免过分回流/重排(Reflow)
浏览器重新计算布局位置与大小。
常见的重排元素:
widthheightpaddingmargindisplayborder-widthbordertoppositionfont-sizefloattext-alignoverflow-yfont-weightoverflowleftfont-familyline-heightvertical-alignrightclearwhite-spacebottommin-height
10. 高效利用 computedStyle
-
公共类。 -
慎用 ChildSelector。 -
尽可能共享。
11. 减少昂贵属性
当页面发生重绘时,它们会降低浏览器的渲染性能。所以在编写 CSS 时,我们应该尽量减少使用昂贵属性,如:
-
box-shadow。 -
border-radius。 -
filter。 -
:nth-child。
12. 依赖继承
如果某些属性可以继承,那么自然没有必要再写一遍。
13. 遵守 CSS 顺序规则
上面就是对本文的一个总结,你了解 CSS 具体的实现原理,晓得规避错误书写方式,知道为什么这么优化,这就够了。
性能优化,进无止境。
参考链接:http://jartto.wang/2019/10/23/css-theory-and-optimization/今天就分享这么多,关于CSS 之渲染原理及优化策略,你学会了多少?欢迎在留言区评论,对于有价值的留言,我们都会一一回复的。如果觉得文章对你有一丢丢帮助,请点右下角【在看】,让更多人看到该文章。
以上是关于CSS 之渲染原理及优化策略的主要内容,如果未能解决你的问题,请参考以下文章