awk处理合并两个文件,急...
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了awk处理合并两个文件,急...相关的知识,希望对你有一定的参考价值。
例如这两个文件
文件1
116 t1
117 t2
118 t3
文件2
116 1000
117 1500
118 800
我想要的结果是
文件2中的第一个字段即(116,117,118)和文件1中的第一个字段即(116,117,118)每行进行对比如果相同的话 替换成下面这样的
t1 1000
t2 1500
t3 118
t3 118 写错了 不是118 应该是800
如果要是让1个文件的每行的第二个字段、第三个字段和另外一个文件的第二个字段、第三个字段相减呢
file1 :
a 2 3
b 4 5
file2:
a 5 6
b 8 9
想要的结果是
a 3 3
b 4 4
假设现有下面4个文件:
file1: file2: file3: file4:
116 t1 116 1000 100 t1 115 600
117 t2 117 1500 105 t2 100 700
118 t3 118 800 110 t3 110 800
115 t4 105 900
200 300
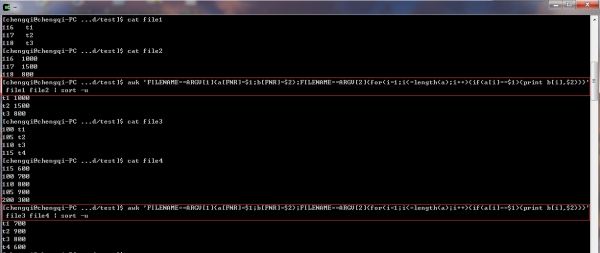
1. 比较file1和file2: (下面是一行命令,非两行)
awk 'FILENAME==ARGV[1]a[FNR]=$1;b[FNR]=$2;FILENAME==ARGV[2]for(i=1;i<=length(a);i++)if(a[i]==$1)print b[i],$2' file1 file2 | sort -u
结果:
t1 1000
t2 1500
t3 800
2. 比较file3和file4: (下面是一行命令, 非两行)
awk 'FILENAME==ARGV[1]a[FNR]=$1;b[FNR]=$2;FILENAME==ARGV[2]for(i=1;i<=length(a);i++)if(a[i]==$1)print b[i],$2' file3 file4 | sort -u
结果:
t1 700
t2 900
t3 800
t4 600
执行情况见下面截图:
__________________________________________________________________________
补充:
“我想要的结果是
文件2中的第一个字段即(116,117,118)和文件1中的第一个字段即(116,117,118)每行进行对比如果相同的话 替换成下面这样的
t1 1000
t2 1500
t3 118 “
——————————————————————————————————————————
如果不同的话需不需要展示出来?
上面的命令是只展示匹配到的
如果想把 不匹配的也展示出来, 用下面的命令:
awk 'FILENAME==ARGV[1]a[FNR]=$1;b[FNR]=$2;FILENAME==ARGV[2]for(i=1;i<=length(a);i++)if(a[i]==$1)$1=b[i];print $1,$2' file3 file4 | sort -u
结果
200 300
t1 700
t2 900
t3 800
t4 600
如果要是让1个文件的每行的第二个字段、第三个字段和另外一个文件的第二个字段、第三个字段相减呢
file1 :
a 2 3
b 4 5
file2:
a 5 6
b 8 9
想要的结果是
a 3 3
b 4 4
下面这个命令展示的相应字段相减的绝对值
awk 'NR==FNRa[FNR]=$2;b[FNR]=$3NR!=FNRc[FNR]=($2-a[FNR]<0?a[FNR]-$2:$2-a[FNR]);d[FNR]=(b[FNR]-$3<0?$3-b[FNR]:b[FNR]-$3);print $1,c[FNR],d[FNR]' file1 file2
如果第一字段需要比对,
像前面一样在外围加上条件.
多谢了~ 这次遇着高手了 再麻烦问下哈 要是四个文件
file1 :
a 2
b 4
file2:
a 5
b 8
file3 :
a 2
b 4
file4:
a 5
b 8
文件1和文件2相减是
a 3
b 4
文件3和文件4相减是
a 3
b 4
想让两个文件合并咋弄呀 就是这样的结果
a 3 3
b 4 4
写成一条命令太长了,分成3条命令就行了
awk 'NR==FNRa[FNR]=$2NR!=FNRb[FNR]=($2-a[FNR] tmp1
awk 'NR==FNRa[FNR]=$2NR!=FNRb[FNR]=($2-a[FNR] tmp2
awk 'NR==FNRa[FNR]=$1;b[FNR]=$2NR!=FNRfor(i=1;i<=length(a);i++)if(a[i]==$1)print a[i],b[i],$2' tmp1 tmp2
第一个文件大第二个文件小的时候 相减应该是负数 但是显示的还是正数
追答如果想要负数, 去掉判断部分,改成下面这样
awk 'NR==FNRa[FNR]=$2NR!=FNRb[FNR]=$2-a[FNR];print $1,b[FNR]' file1 file2 > tmp1
awk 'NR==FNRa[FNR]=$2NR!=FNRb[FNR]=$2-a[FNR];print $1,b[FNR]' file3 file4 > tmp2
awk 'NR==FNRa[FNR]=$1;b[FNR]=$2NR!=FNRfor(i=1;i<=length(a);i++)if(a[i]==$1)print a[i],b[i],$2' tmp1 tmp2
awk 'NR==FNRa[$1]=$2NR!=FNRprint a[$1]" "$2' file1 file2

讲清楚,说明白!Linux从业人员必备工具--AWK文本处理利器实战
目录:(九)两个文件合并
(十)关于NFS权限的设置
(十一)求交集
(十二)统计字符出现的次数
(十三)求和
(十四)案例实战
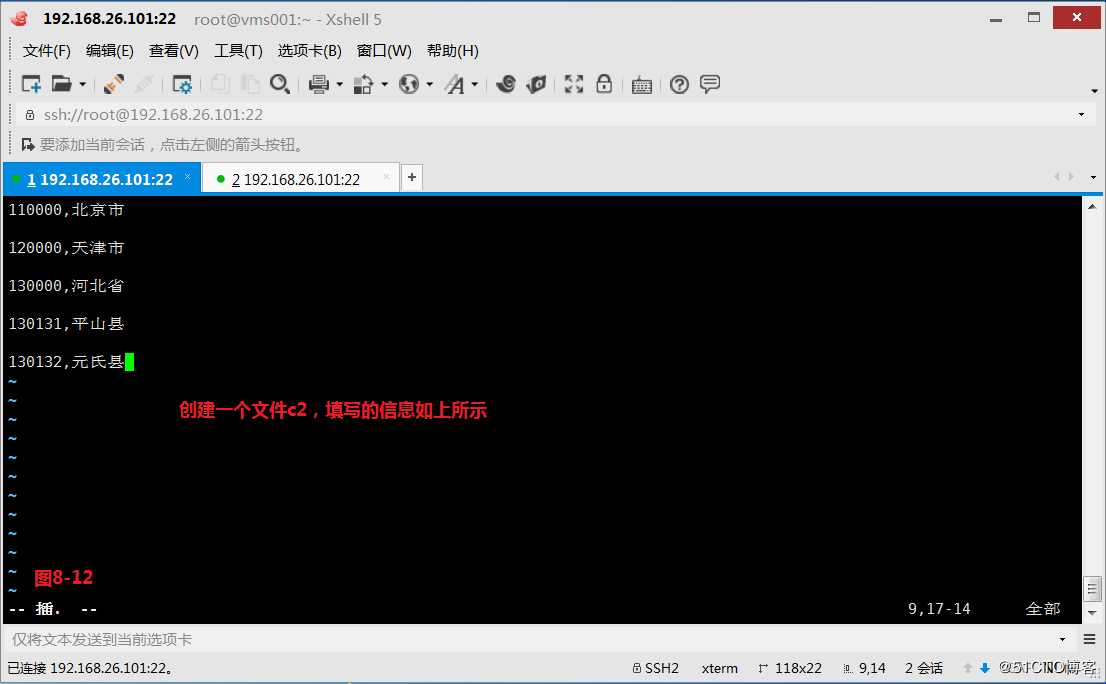
(九)两个文件合并
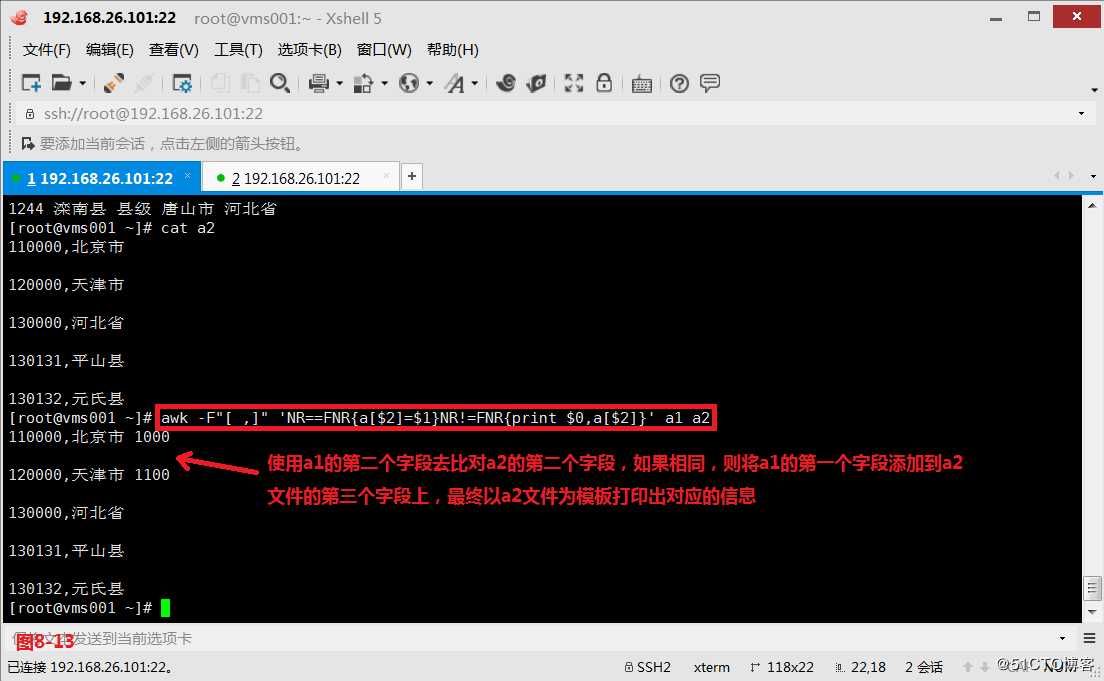
(9.1)首先我们在系统中定义两个文件a1和a2,现在我们的需求是使用a1的第二个字段去比对a2的第二个字段,如果相同,则将a1的第一个字段添加到a2文件的第三个字段上,最终以a2文件为模板打印出对应的信息,如果多个文件进行合并可以考虑使用数组
# awk -F"[ ,]" ‘NR==FNR{a[$2]=$1}NR!=FNR{print $0,a[$2]}‘ a1 a2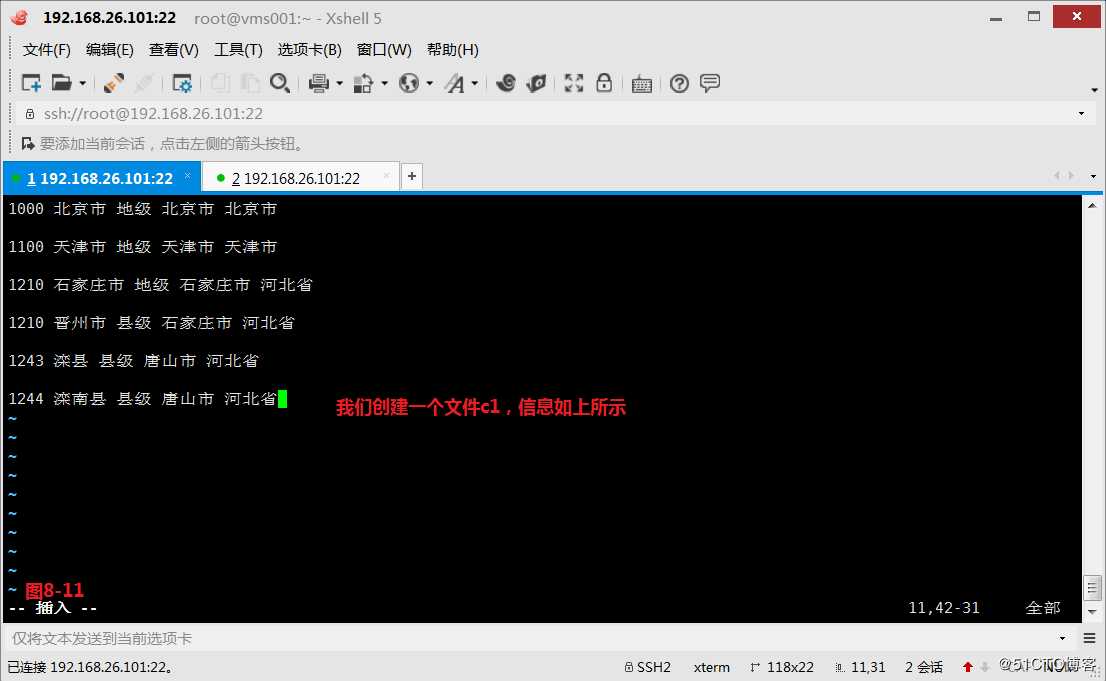
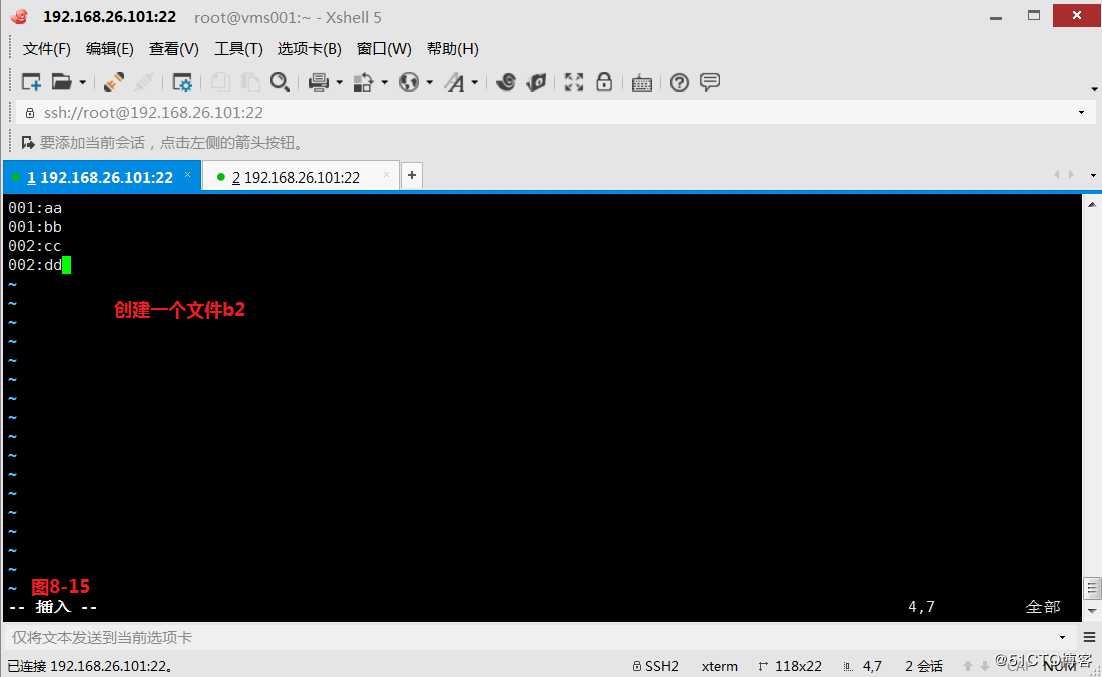
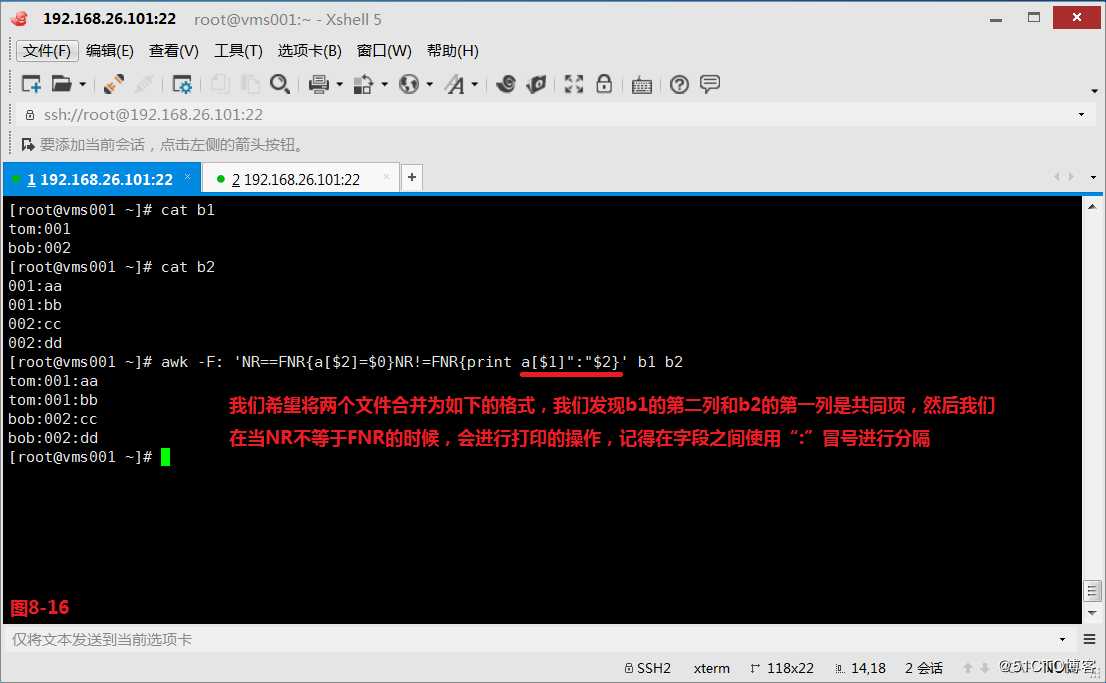
(9.2)我们创建两个文件b1和b2,现在我们希望将两个文件合并为如下的格式,我们发现b1的第二列和b2的第一列是共同项,然后我们在当NR不等于FNR的时候,会进行打印的操作,记得在字段之间使用“:”冒号进行分隔。
我们希望打印的结果如下:
tom:001:aa
tom:001:bb
bob:002:cc
bob:002:dd
# awk -F: ‘NR==FNR{a[$2]=$0}NR!=FNR{print a[$1]":"$2}‘ b1 b2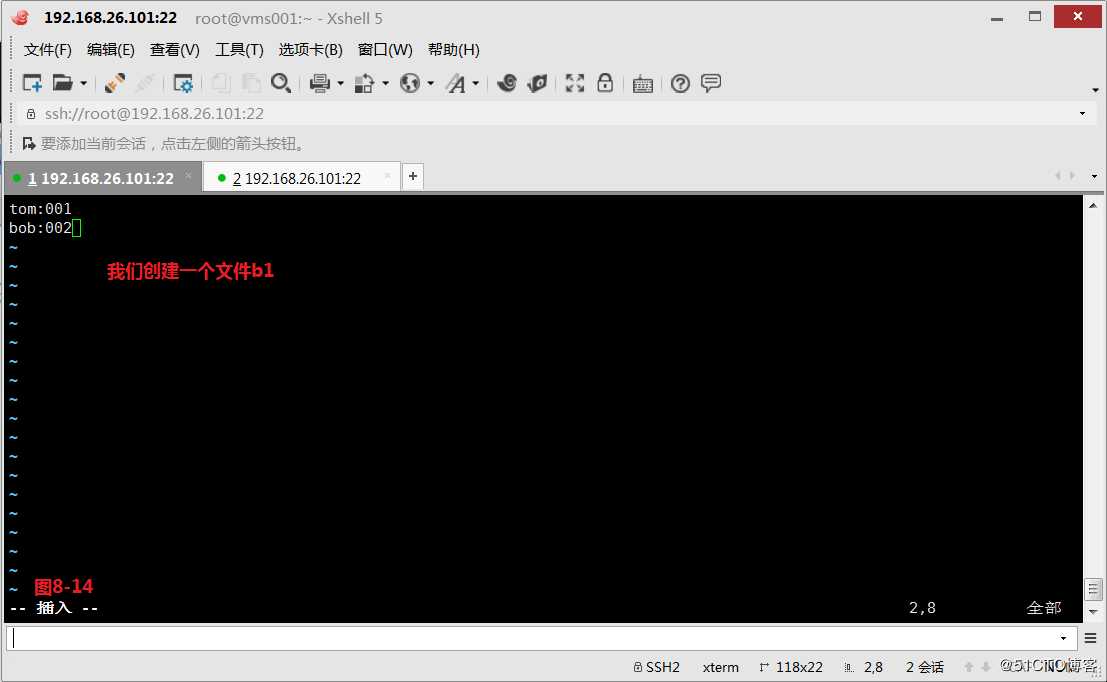
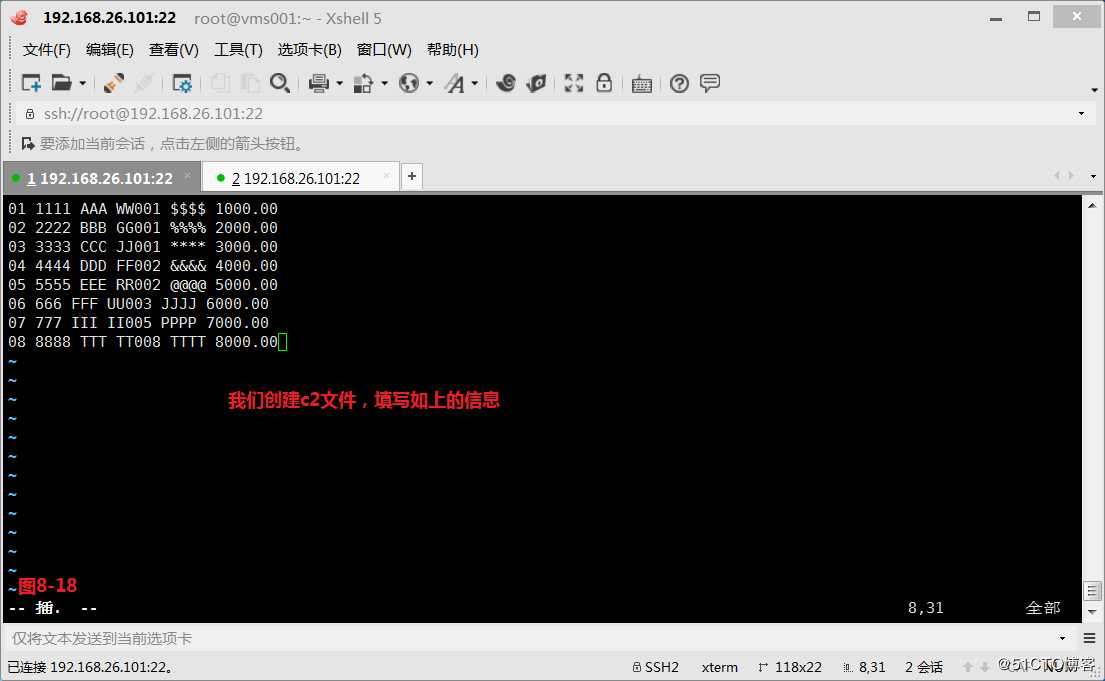
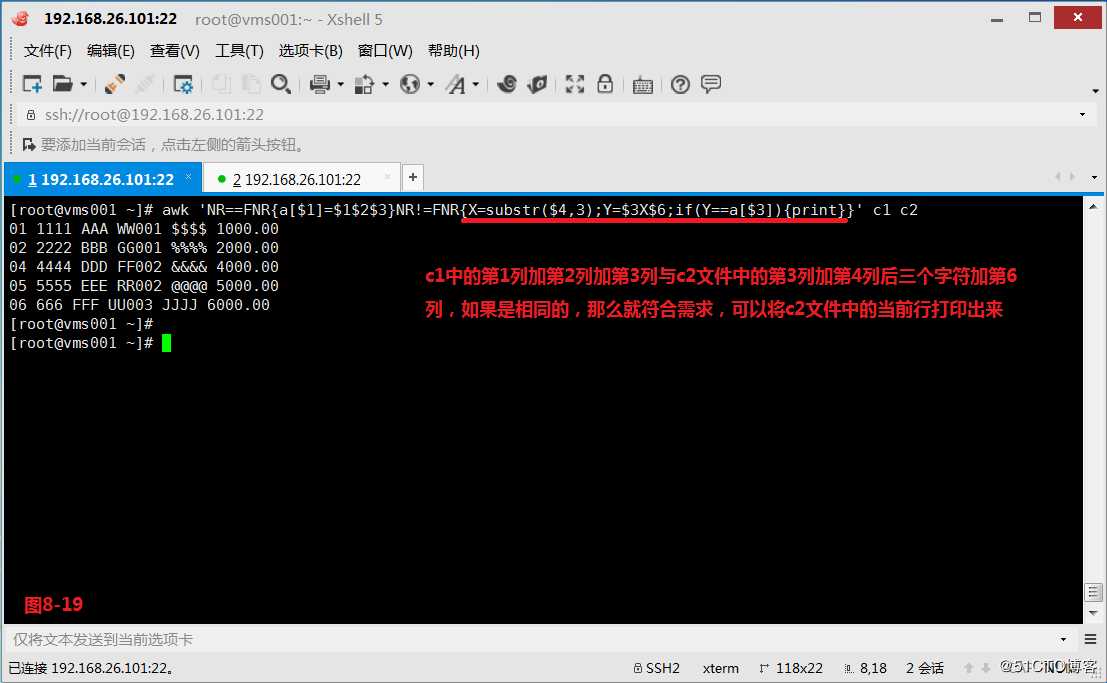
(9.3)我们创建一个c1和c2文件,如果c1的$1和c2的$3相同,c1的$2和c2的$4的后三个字符相同,c1的$3和c2的$6相同,那么打印c2中符合条件的行,如果需求是筛选多个共同列,我们只要把这多个共同列进行合并比较即可。我们发现c1中的第1列加第2列加第3列与c2文件中的第3列加第4列后三个字符加第6列,如果是相同的,那么就符合需求,可以将c2文件中的当前行打印出来。
# awk ‘NR==FNR{a[$1]=$1$2$3}NR!=FNR{X=substr($4,3);Y=$3X$6;if(Y==a[$3]){print}}‘ c1 c2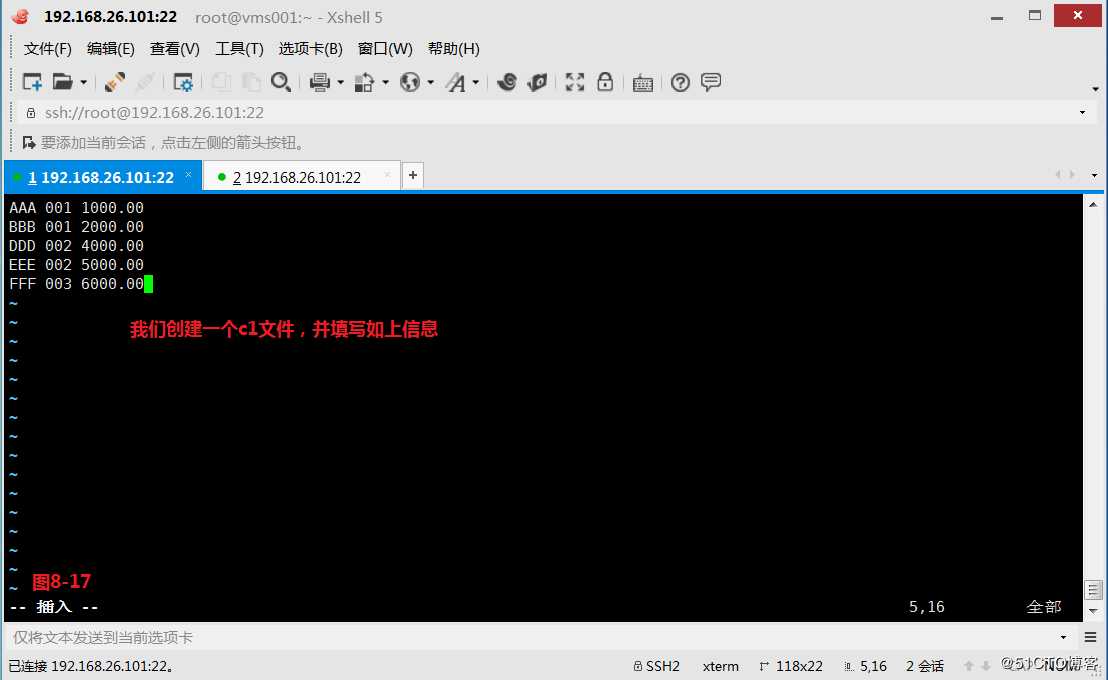
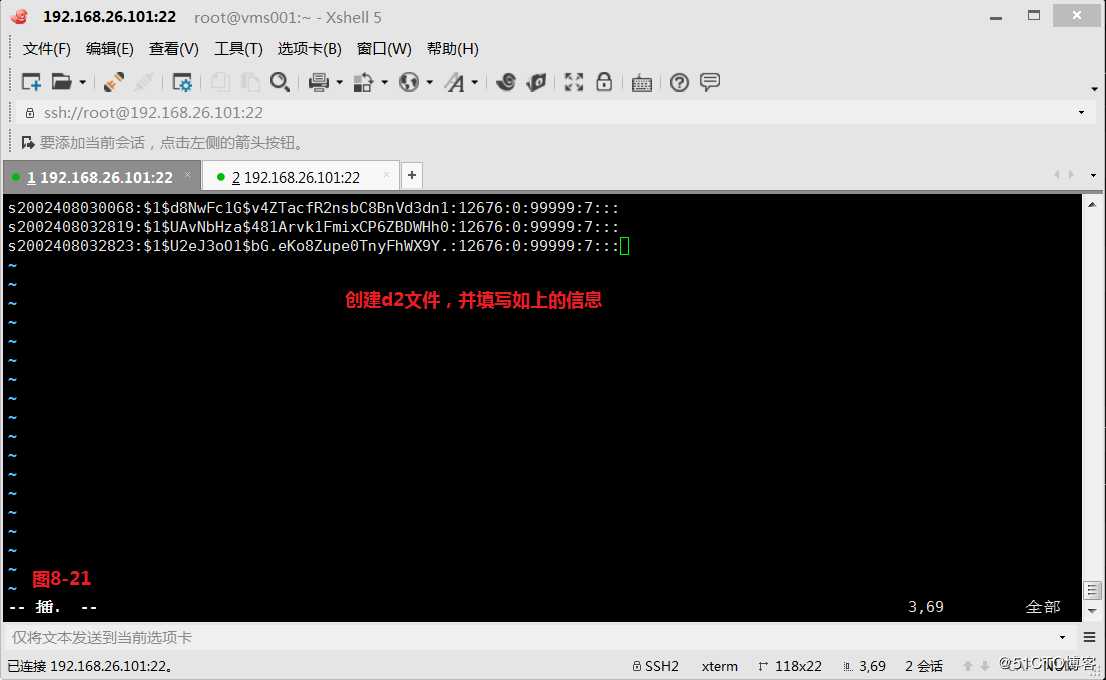
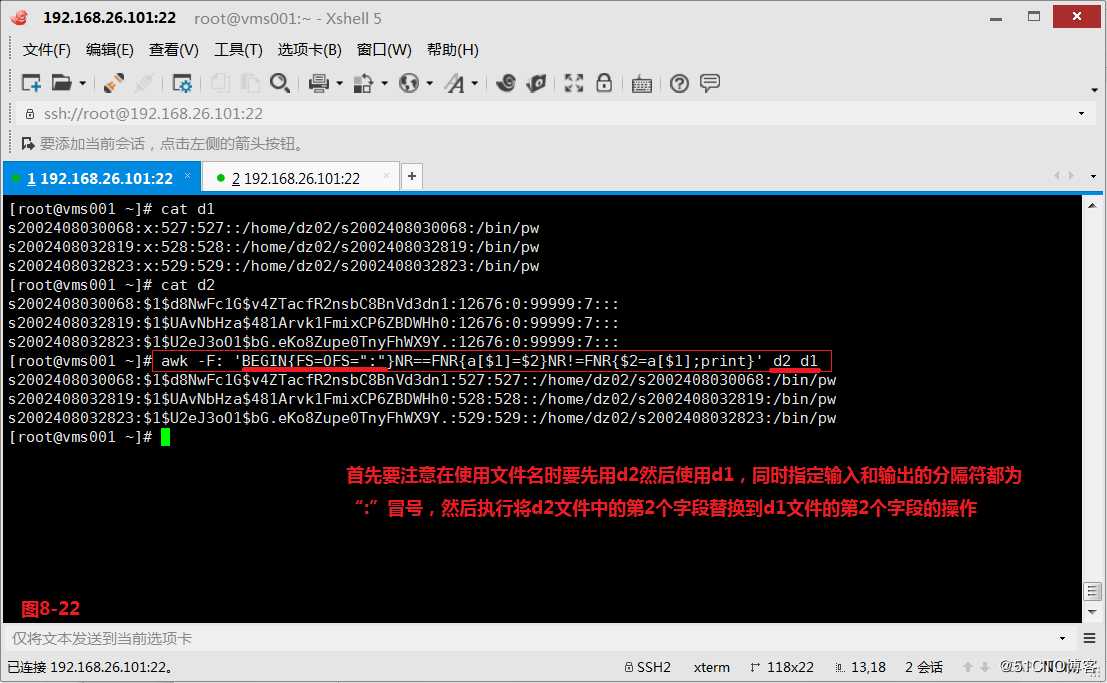
(9.4)我们创建一个文件d1和d2,此时我们希望将d2文件中的第2个字段替换到d1文件的第2个字段,首先要注意在使用文件名时要先用d2然后使用d1,同时指定输入和输出的分隔符都为“:”冒号,然后执行将d2文件中的第2个字段替换到d1文件的第2个字段的操作。
# awk -F: ‘BEGIN{FS=OFS=":"}NR==FNR{a[$1]=$2}NR!=FNR{$2=a[$1];print}‘ d2 d1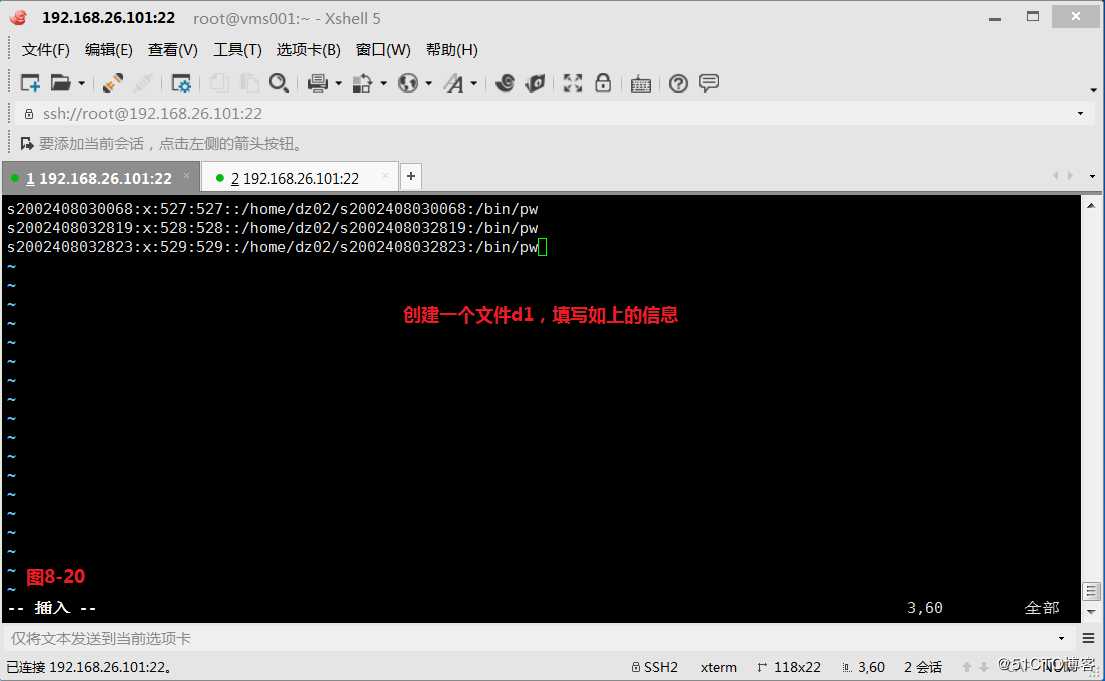
(十)相同行合并为一行
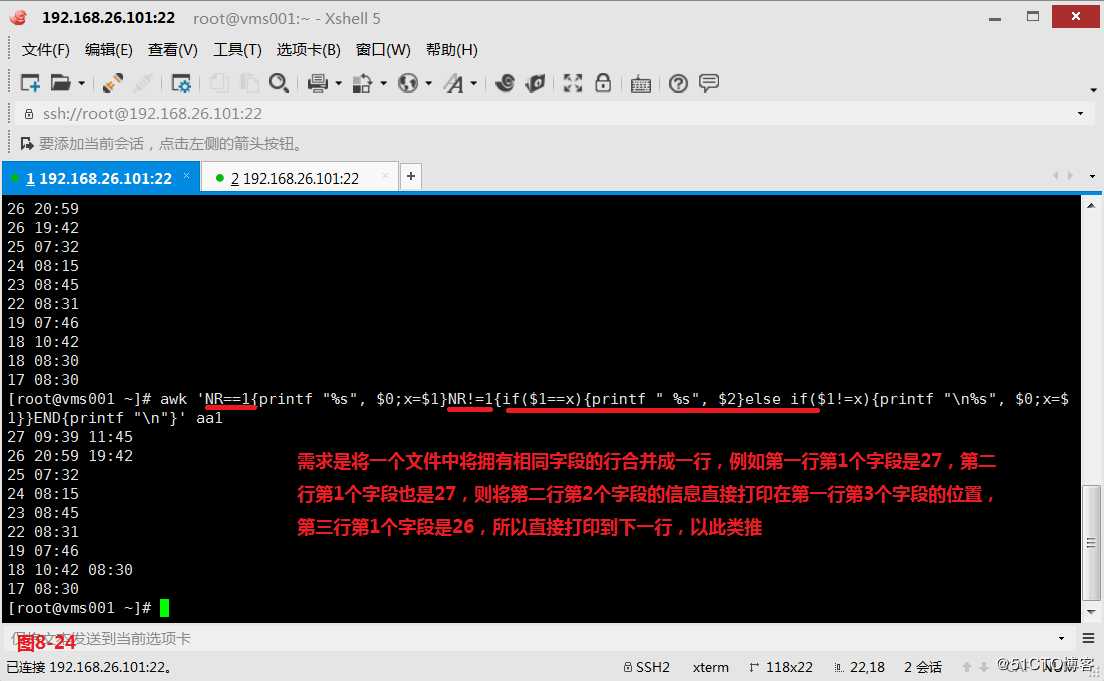
(10.1)我们创建一个文本文件aa1,现在我们的需求是将一个文件中将拥有相同字段的行合并成一行,例如第一行第1个字段是27,第二行第1个字段也是27,则将第二行第2个字段的信息直接打印在第一行第3个字段的位置,第三行第1个字段是26,所以直接打印到下一行,以此类推。首先使用NR是否等于1来进行判断,如果NR为1则打印当前行并将第一行第1个字段赋值给变量x,接着是第二行,发现NR不等于1了,但是第二行第1个字段等于变量x的值,所以此时用printf打印此" %s"格式,然后处理第三行,我们发现符合“else if($1!=x)”这个条件,所以此时我们会先打印一个换行符“
”然后再打印这一整行的内容,并将当前行的第1个字段赋值给变量x,这样我们就基本可以实现我们所需求的格式了。
# awk ‘NR==1{printf "%s", $0;x=$1}NR!=1{if($1==x){printf " %s", $2}else if($1!=x){printf "
%s", $0;x=$1}}END{printf "
"}‘ aa1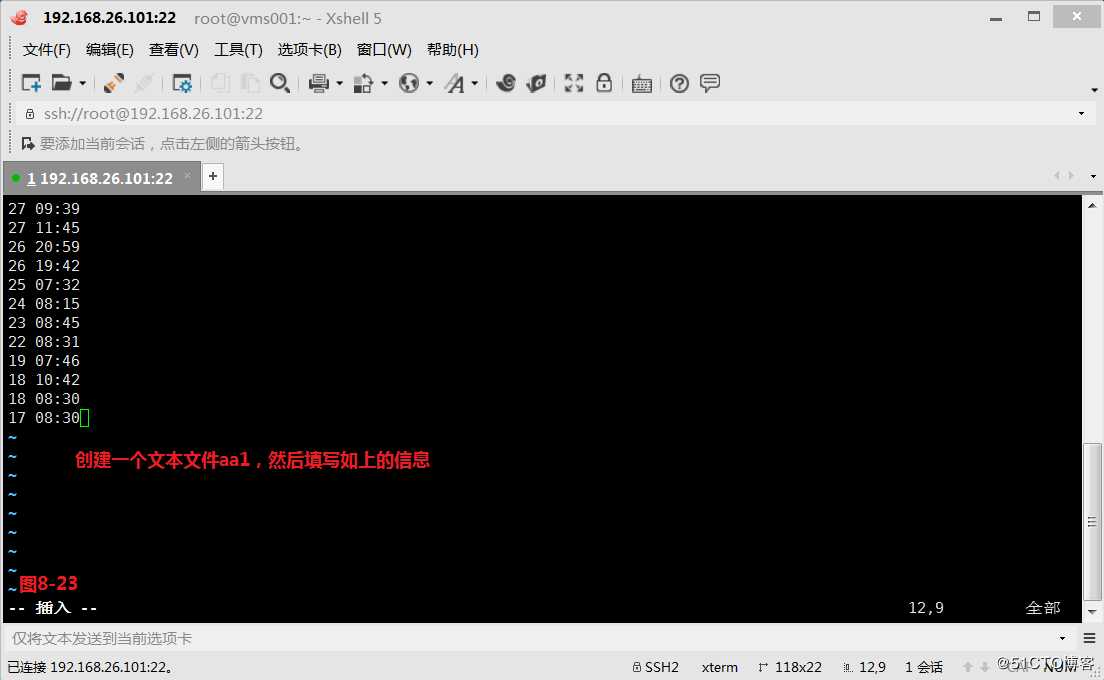
(十一)求交集
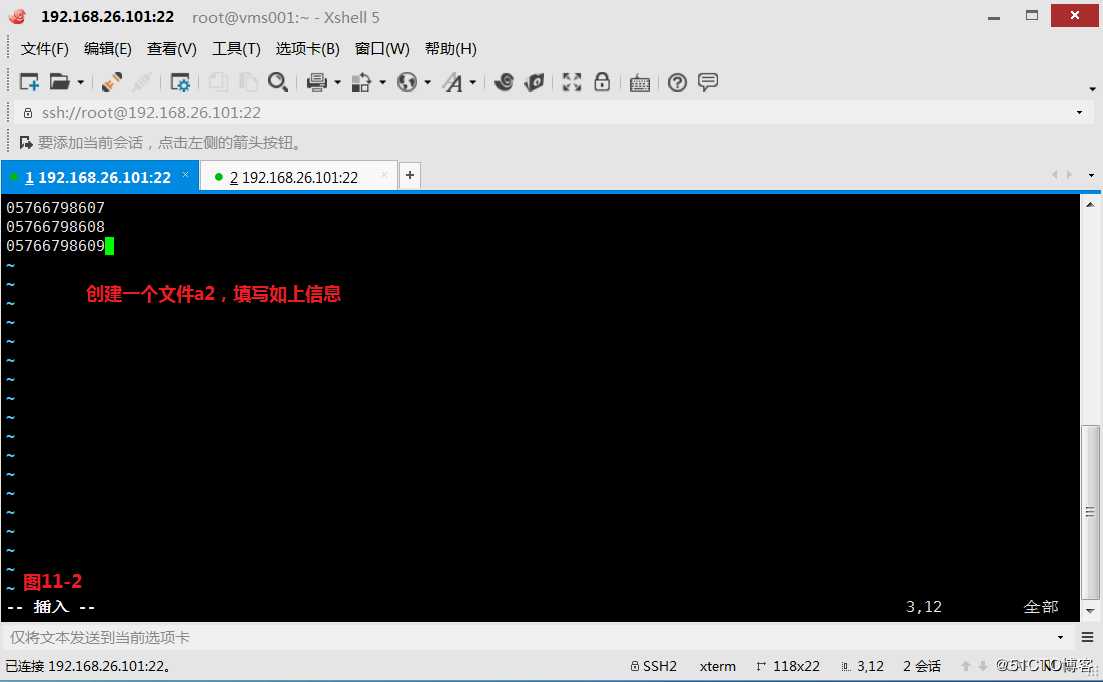
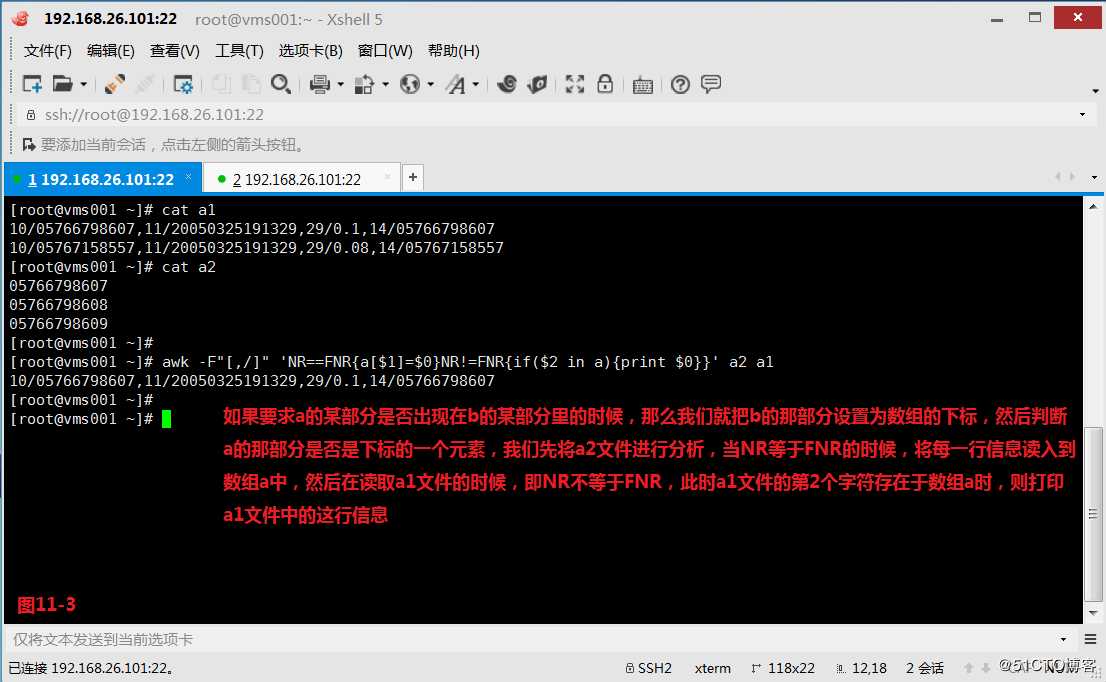
(11.1)现在我们创建了两个文件a1和a2,现在要求打印a1文件中的一些行,a1的第2字段出现在a2的第1个字段中,现在如果要求a的某部分是否出现在b的某部分里的时候,那么我们就把b的那部分设置为数组的下标,然后判断a的那部分是否是下标的一个元素。此时则应该为“awk -F”[,/]” ‘’ a2 a1”
# awk -F"[,/]" ‘NR==FNR{a[$1]=$0}NR!=FNR{if($2 in a){print $0}}‘ a2 a1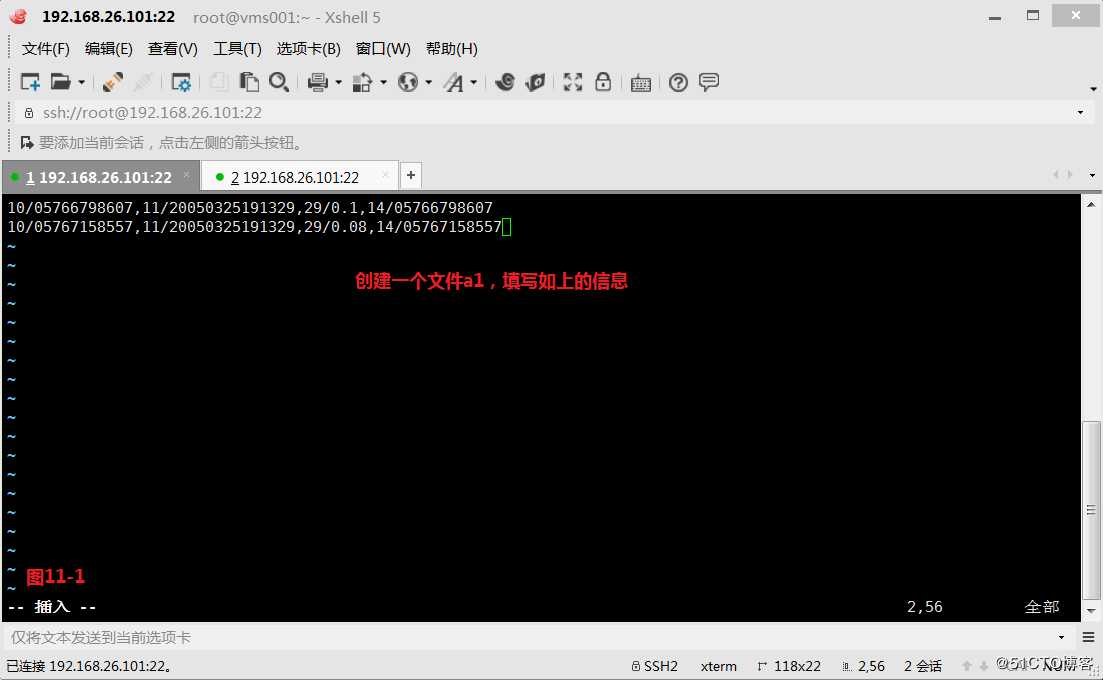
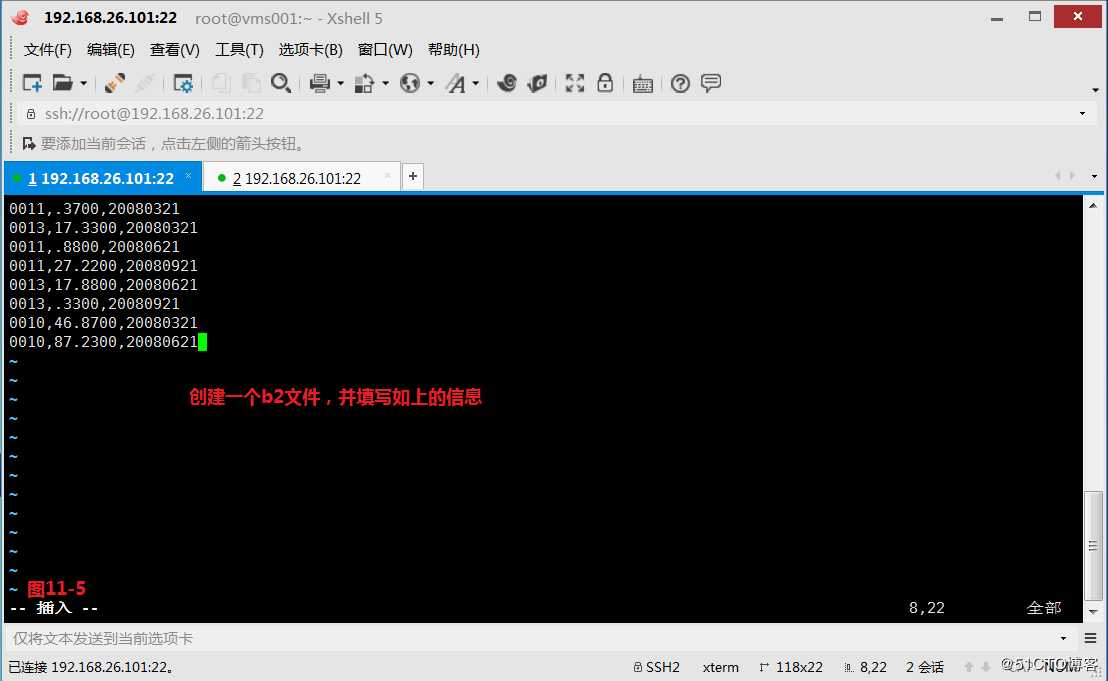
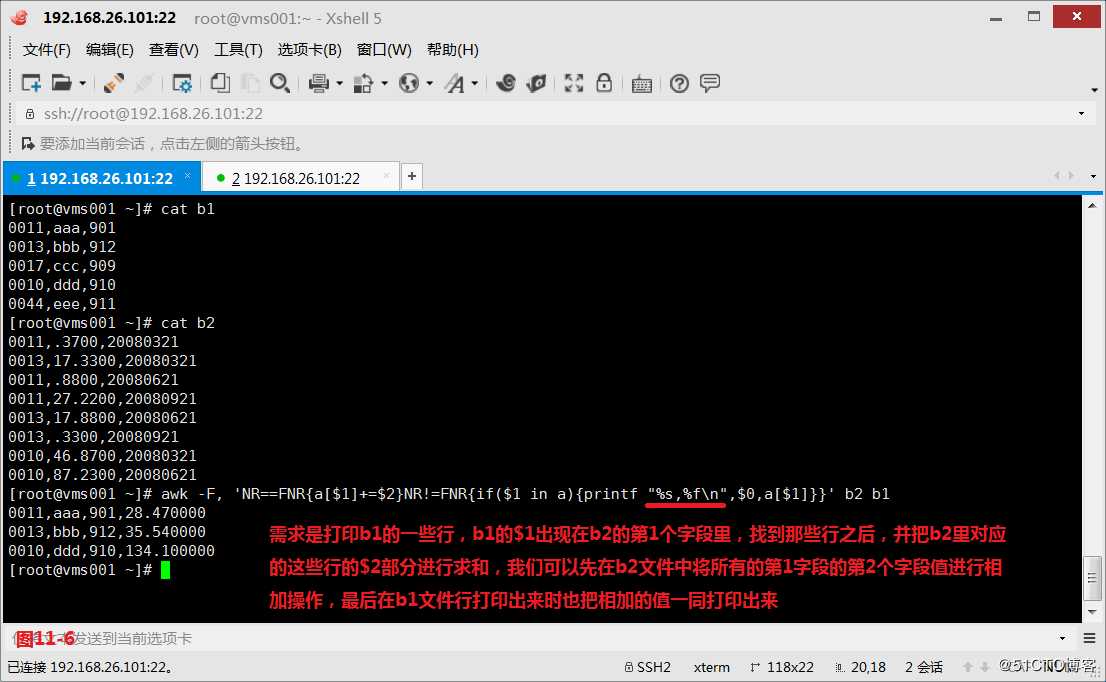
(11.2)现在我们创建两个文件b1和b2,现在我们的需求是打印b1的一些行,b1的$1出现在b2的第1个字段里,找到那些行之后,并把b2里对应的这些行的$2部分进行求和,我们可以先在b2文件中将所有的第1字段的第2个字段值进行相加操作,最后在b1文件行打印出来时也把相加的值一同打印出来。
# awk -F, ‘NR==FNR{a[$1]+=$2}NR!=FNR{if($1 in a){printf "%s,%f
",$0,a[$1]}}‘ b2 b1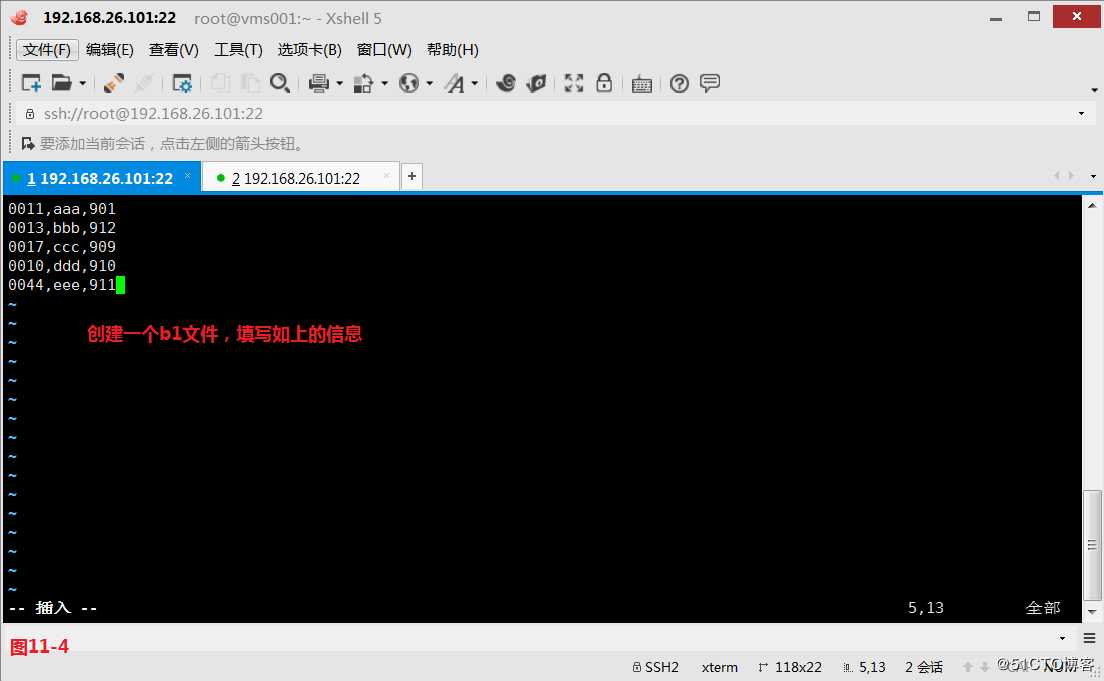
(十二)统计字符出现的次数
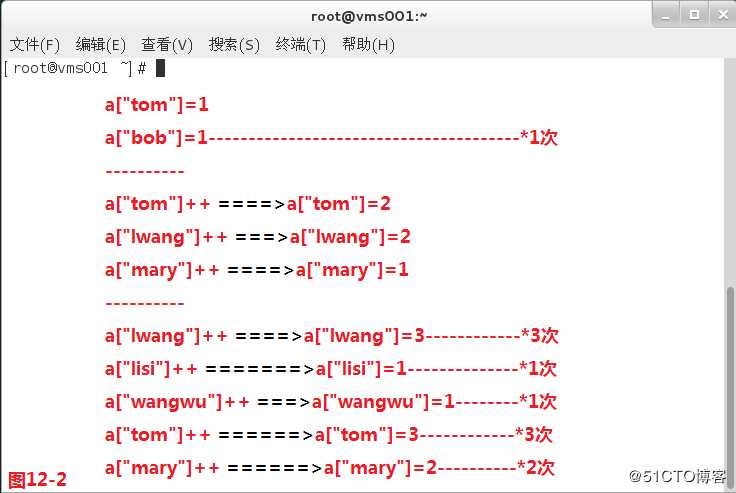
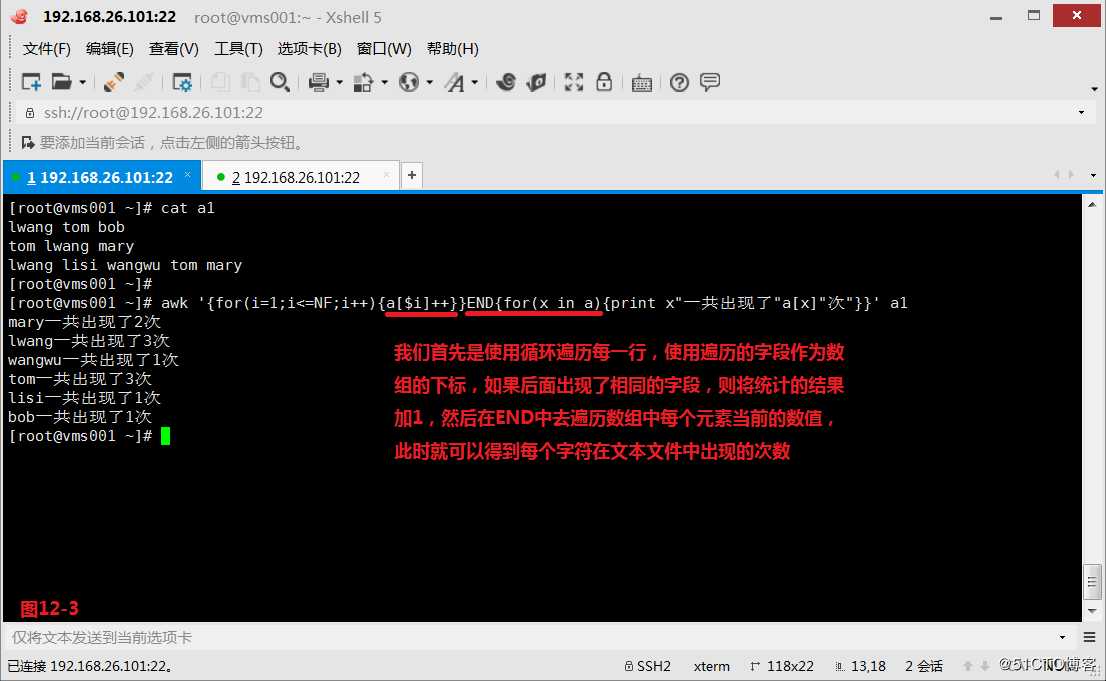
(12.1)我们有一个文件a1,现在我们需要统计每个字符在文本文件中出现的次数,此时我们的思路是遇到一个字段就将其设置为一个元素的下标,当我们已经定义了一个元素时,如果下次再遇到这个下标的元素的时候,则加上1次。我们首先是使用循环遍历每一行,使用遍历的字段作为数组的下标,如果后面出现了相同的字段,则将统计的结果加1,然后在END中去遍历数组中每个元素当前的数值,此时就可以得到每个字符在文本文件中出现的次数。
# awk ‘{for(i=1;i<=NF;i++){a[$i]++}}END{for(x in a){print x"一共出现了"a[x]"次"}}‘ a1
(十三)求和
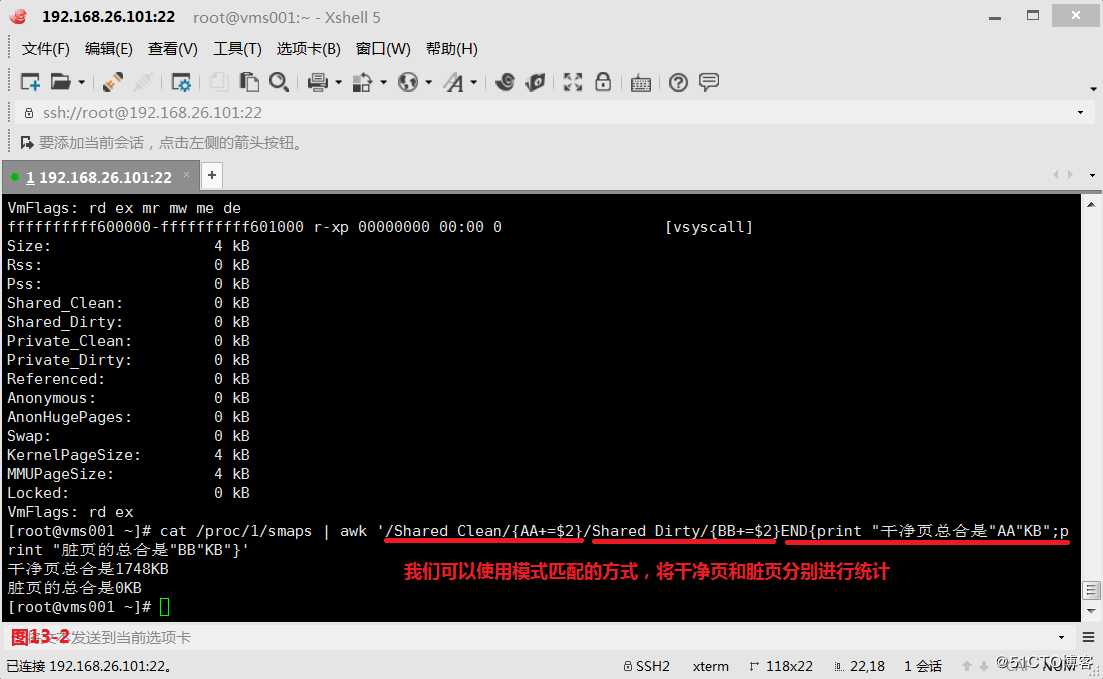
(13.1)在我们的内存中正常是会将内存的数据写入到硬盘中的,因此内存的数据和硬盘的数据是同步的,我们称之为干净数据,但是有时候在我们的内存中有些数据修改完后并没有写入到硬盘中去,内存中的数据和硬盘数据并不同步,此时这类数据我们称之为脏数据,如果脏数据没有及时写入到硬盘,那么当计算机重启之后没有写入到硬盘的数据就会丢失了。现在我们的需求是计算出某个进程一共有多少个干净页,有多少个脏页,我们是可以从/proc/1/smaps的系统映射文件中查看到我们所需的内存相关信息的,我们可以使用模式匹配的方式,将干净页和脏页分别进行统计,在之前的基础上进行连加操作。
# cat /proc/1/smaps
# cat /proc/1/smaps | awk ‘/Shared_Clean/{AA+=$2}/Shared_Dirty/{BB+=$2}END{print "干净页总合是"AA"KB";print "脏页的总合是"BB"KB"}‘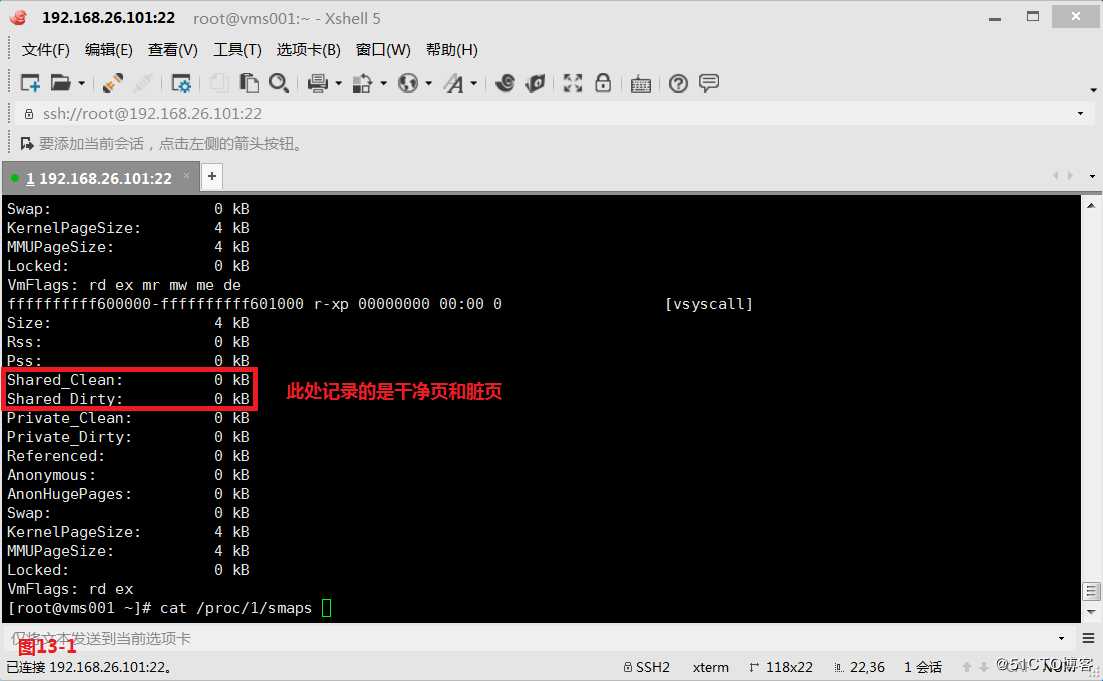
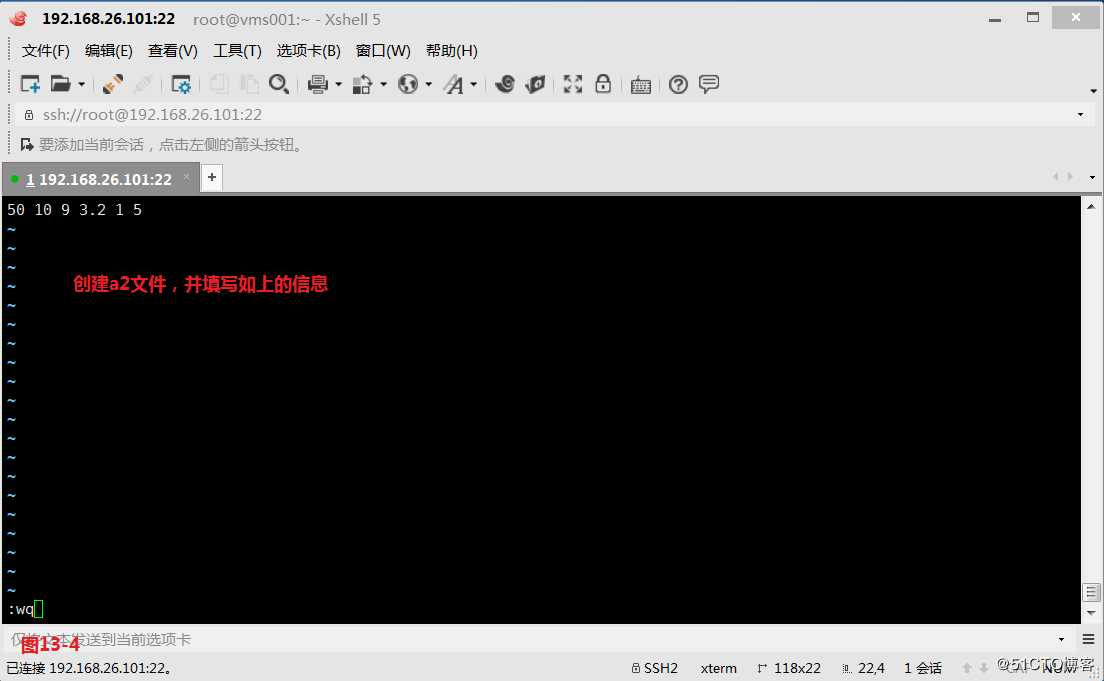
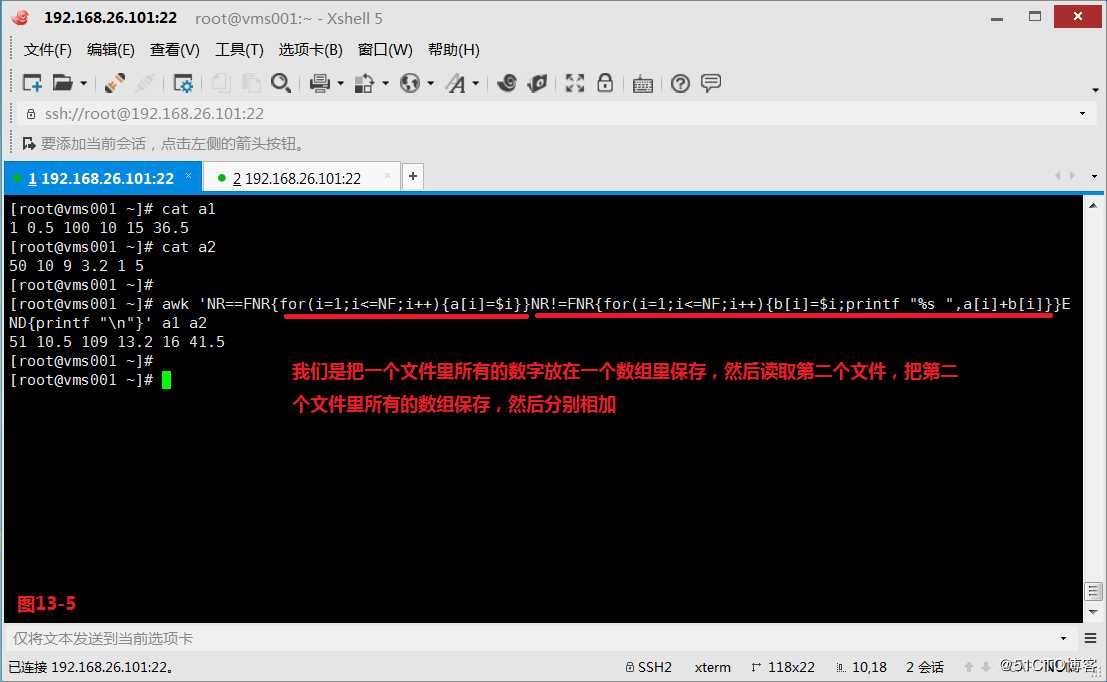
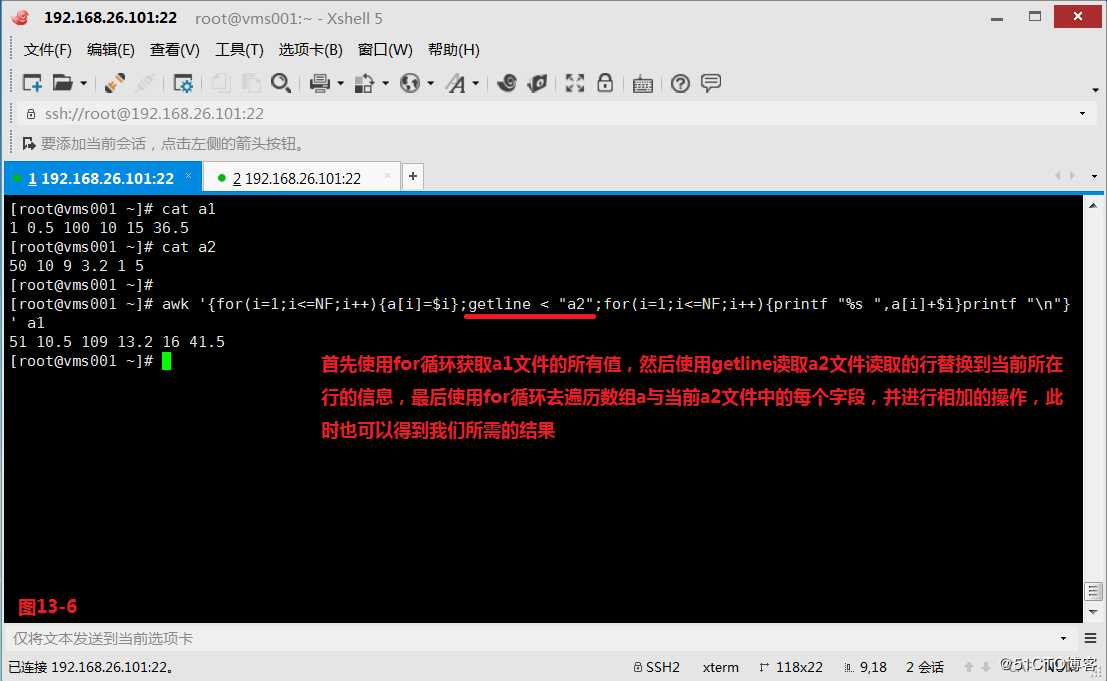
(13.2)现在我们有两个文件a1和a2,因为我们发现a1文件和a2文件的列数是一样的,所以现在我们的需求是希望将a1文件和a2文件中对应的列数进行相加得到一个相加后的一行数组。解决这个问题的思路我们是把一个文件里所有的数字放在一个数组里保存,然后读取第二个文件,把第二个文件里所有的数组保存,然后分别相加(图13-5)。当然我们也可以使用getline函数解决问题,首先使用for循环获取a1文件的所有值,然后使用getline读取a2文件读取的行替换到当前所在行的信息,最后使用for循环去遍历数组a与当前a2文件中的每个字段,并进行相加的操作,此时也可以得到我们所需的结果(图)。
# awk ‘NR==FNR{for(i=1;i<=NF;i++){a[i]=$i}}NR!=FNR{for(i=1;i<=NF;i++){b[i]=$i;printf "%s ",a[i]+b[i]}}END{printf "
"}‘ a1 a2
# awk ‘{for(i=1;i<=NF;i++){a[i]=$i};getline < "a2";for(i=1;i<=NF;i++){printf "%s ",a[i]+$i}printf "
"}‘ a1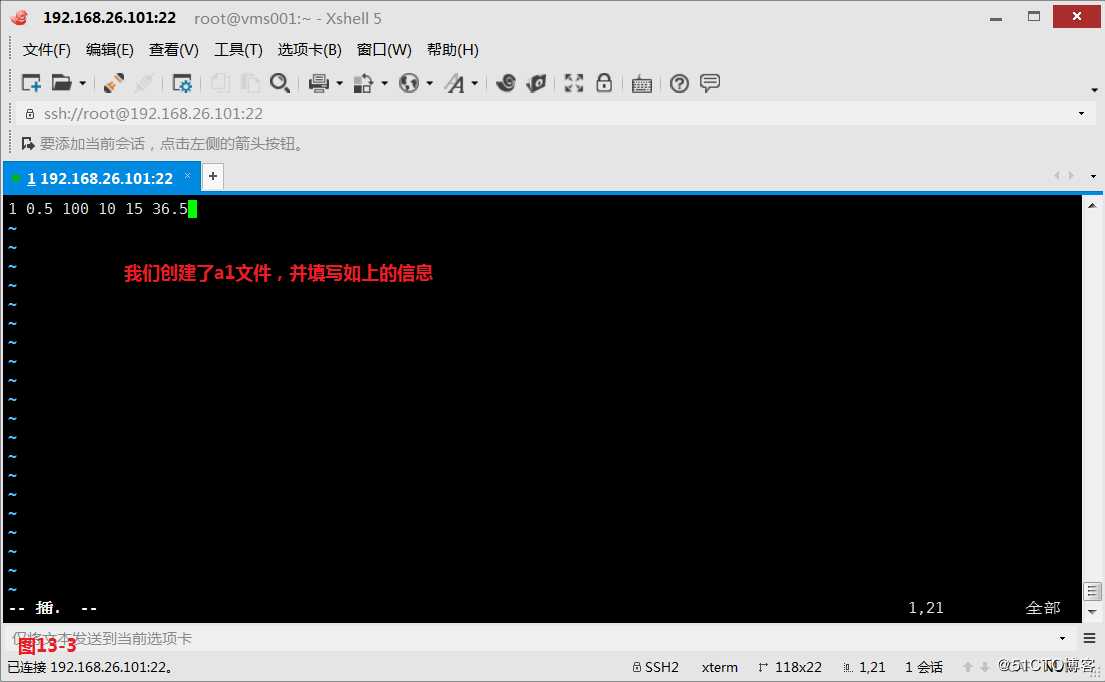
(十四)案例实战
(14.1)取得网卡的IP
# ifconfig | grep ‘inet‘ | grep broadcast | awk ‘{print $2}‘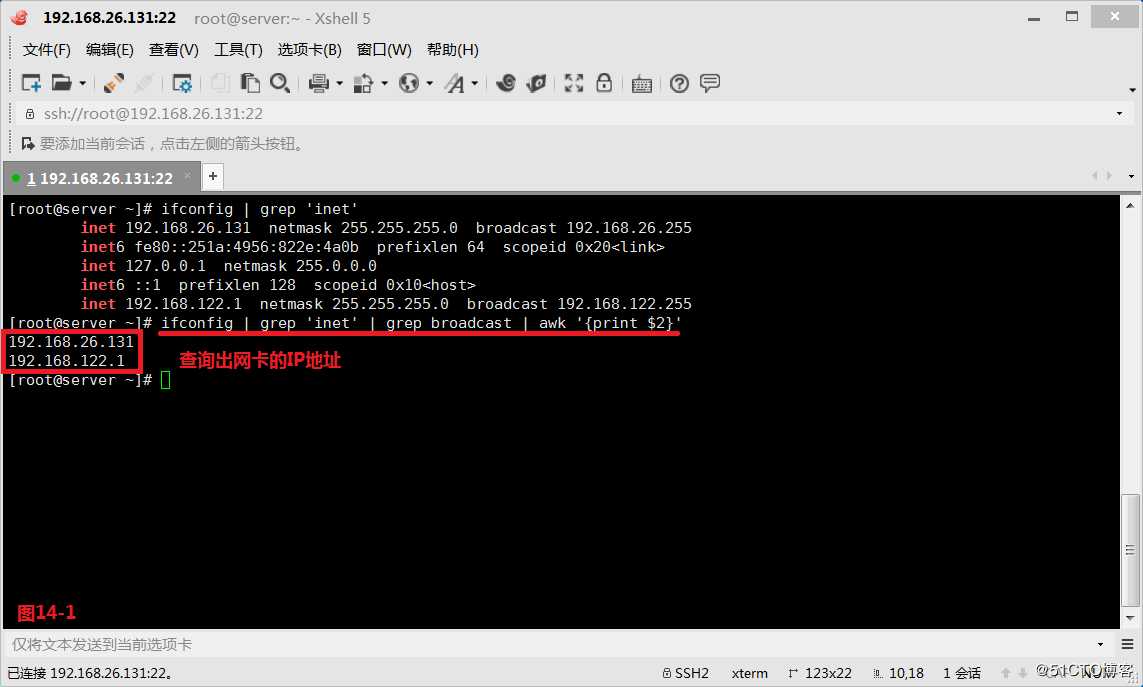
(14.2)取得系统内存大小
# cat /proc/meminfo | awk ‘/MemTotal/{print $2}‘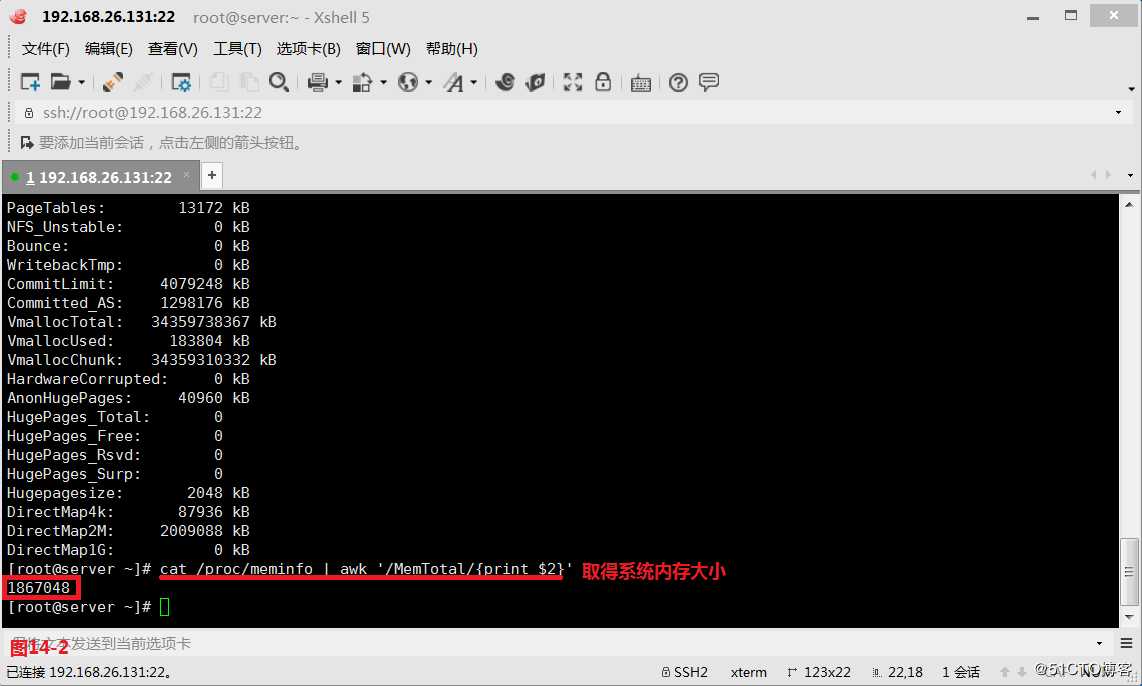
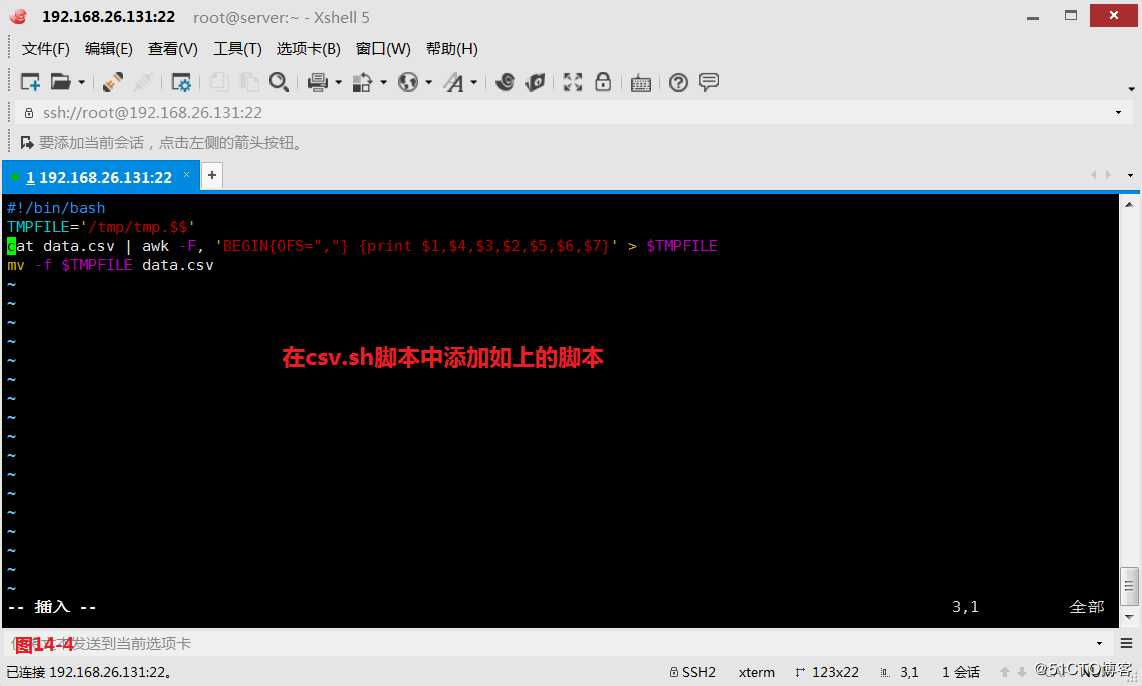
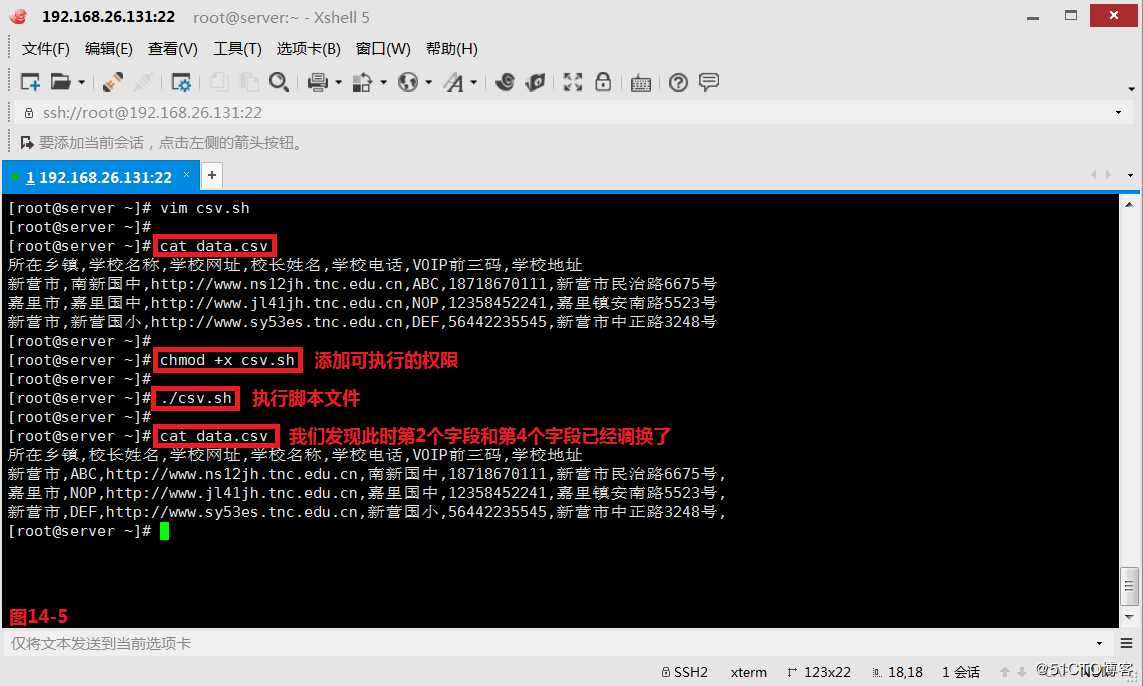
(14.3)修改CSV文件各字段的顺序,我们先在系统中创建一个data.csv的文件,想要把第2个字段和第4个字段进行调换。
# cat data.csv | awk -F, ‘BEGIN{OFS=","} {print $1,$4,$3,$2,$5,$6,$7}‘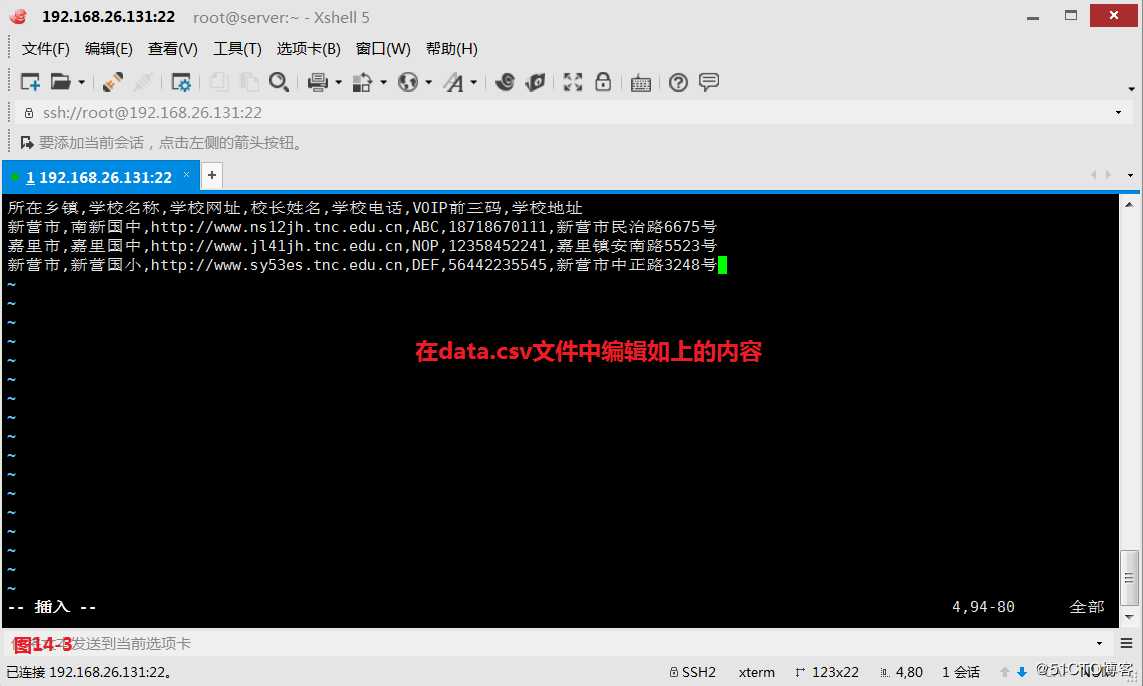
—————— 本文至此结束,感谢阅读 ——————
以上是关于awk处理合并两个文件,急...的主要内容,如果未能解决你的问题,请参考以下文章