数据埋点技巧
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据埋点技巧相关的知识,希望对你有一定的参考价值。
参考技术A 移动互联网时代,无论是android、ios还是小程序,都有很多成熟的解决方案,无需花费很多的时间去处理埋点的事情,而且基于第三方提供的SDK进行埋点,在数据处理和分析上也有很大的优势。但是在之前的PC互联网时代,除了网页端有百度统计、谷歌分析等,客户端的埋点似乎没有一套能拿出来可供大家讨论的解决方案,我就基于我的工作经验和理解,给大家分享一下PC客户端的埋点。
PC客户端的埋点
首先,在PC上,我们得知道我们需要统计些什么内容。
一个PC客户端,无论是工具类的还是内容类的,我们都希望知道我们提供的服务的效果。那么,我们从一个客户端安装、运行到最终被卸载来看看。
就拿产品使用较多的工具“Axure RP”来举例吧。如果“Axure RP”是我们自己的软件,首先我们需要知道被安装了,之后,我们关注激活情况,也就是使用,到最后,被卸载了,这一整个环节,构成了一个生命周期。 重点来了,对于这个生命周期,所有你想知道的关于“Axure RP”的情况你都可以统计到。
1.软件的安装
在PC客户端安装的过程中,流程一般是这样的:①运行安装包②弹出安装界面提供给用户操作③执行安装过程-写注册表、启动项、计划任务等④执行安装过程-创建安装的文件夹(③和④可以交换)。
在这个环节,我们一般需要知道:
安装包被运行了
在安装界面用户做了哪些操作
我们的安装过程是否正常执行
我们最终是否安装成功
在PC上,只要我们的安装包运行起来了,无论是弹出安装界面、写注册表还是创建文件,这些都是安装包可以控制的,所以我们能通过安装包进程,将整个安装环节的所有数据记录下来发送到我们的后台并记录下来 (这里要重点记住,由于安装是一次性的动作,所以统计一定要发实时的) 。
2.软件的使用
软件的使用,包括启动软件、使用功能和退出软件。
在PC上,软件的启动有很多种方式,例如开机自启动、计划任务、手动点击快捷方式,我们继续以“Axure RP”举例,当我们装上了“Axure RP”后,会在桌面、开始菜单中,创建快捷方式(有些程序会在任务栏上也创建),同时,会将后缀名为“rp”的文件默认打开方式调整为“Axure RP”。
对于启动, 我们就有了三种方式:桌面快捷方式、开始菜单快捷方式和默认软件打开,所以我们需要统计软件是否被启动了,是如何启动的。
对于使用功能, 当软件运行起来后,其进程就会启动,这个时候就跟移动端的应用类似,我们需要统计一系列事件,每个功能的使用情况、功能状态、付费、登录等一系列信息(区别于移动端的是,在PC上一般这些统计都是做单点统计,例如统计弹窗的弹出、功能的点击、某个状态,对于相互关联的一组事件统计是比较复杂的,需要定义结构体,在一条统计中包含很多组字段信息,因为没有成熟的SDK集成,所以基本都要自己定义埋点,复用性较差)。
这部分统计分为公共统计和专用统计。公共统计就是基本信息,常用的是用户标识、用户基本信息、计算机硬件信息和其他的可复用的;专用统计就是针对你的功能,你想了解哪些情况,针对性进行埋点统计。
对于软件退出, 这就比较简单了,是正常退出还是异常退出?软件使用了多久退出?
3.软件的卸载
软件卸载的流程包括启动卸载程序、用户操作、删除注册表及文件等操作、完成卸载。
在这个过程中,我们主要关注两方面的信息,一方面是用户怎么卸载的?是主动使用卸载程序,还是通过一些管理软件进行卸载;另一方面是用户为什么要卸载,这个时候我们可以在卸载的界面中给用户提供选择,以获取用户的反馈。
该怎么埋点
1.埋点的分类
(1)时效性
PC客户端一般情况下都比较复杂,子功能很多,可统计的内容很多,为了节省带宽,我们不可能每次都实时将数据传输回来,而且很多时效性不是很强的功能没有必要实时上报。
实时统计
当功能触发时或达到一定条件,立即将统计回传,一般情况下用于时效性比较强的功能,例如活跃统计、营收类统计,我们需要实时分析并调整策略。
延时统计
统计不立即回传,将统计积累,达到一定的条件或者一定的时间,统一将这部分统计回传,一般情况用于时效性不强的功能,例如采集设备信息、获取某些功能的状态、常规功能的统计,这部分统计使用范围比较广,一般都是隔日发送,有一天的延迟,统计的信息晚一天不会对分析产生较大的影响。
(2)埋点的作用
常规的基础统计
每次统计都需要发送,可以理解为公用统计,这部分统计是将几乎所有的统计都需要的部分包括进来,封装成一个统一的部分,每次发送统计都会带上这些内容,方便管理,节省后续埋点时间。
功能统计
针对特定功能,当功能被使用或者生效的时候,我们需要统计效果或者状态,可以理解为专用统计,不同于移动端,PC一般没有第三方提供的SDK,需要每个专用统计自己埋点,维护大量的统计内容,不过在一个公司内部,可以统一设计规范,方便维护。
(3)数据类型
结构体
统计连贯的事件,各项信息之间的关联很重要。
计数
统计某个行为发生的次数。
字符串
统计内容。
整形
统计数值,也可用来统计状态。
布尔型
统计需要判断的类型,一般使用场景较少,为了方便计算,大部分被整形和字符串替代。
2.数据埋点实例
(1)软件安装
场景:统计安装过程中的信息
(2)软件的使用
场景:软件启动后,用户使用了分享功能,将自己做的原型分享到了云端,最后用户关闭了软件。
要注意的是,软件启动和关闭,看需要是可以调整的,如果你只是想知道是不是启动了,来判断活跃,那么仅仅需要启动的时候发送个整型的值标识即可;如果想知道更详细的信息,比如启动方式、启动时间等等,可以定义结构体,将这一刻更多的信息发送回来,可灵活定义。
(3)软件卸载
卸载跟软件安装类似,这里就不赘述了。
在这里,如果希望收集用户的卸载原因,可以定义一个字符串,将用户填写的内容上报,这种形式的数据如果太多,不太利于分析,所以看产品情况可灵活设置。
搞懂数据埋点与数据同步
(1)到底什么是埋点
埋点的概念:
埋点是数据采集中的一个统称,通常也叫做事件追踪(Event Tracking),它主要针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。埋点是为了满足快捷、高效、丰富的数据应用而做的用户行为过程及结果记录。数据埋点是一种常用的数据采集的方法。埋点是数据的来源,采集的数据可以分析网站/APP的使用情况,用户行为习惯等,是建立用户画像、用户行为路径等数据产品的基础。
埋点的作用:
- 精准运营
- 用户画像
- 数据分析与挖掘
埋点的分类:
1、客户端埋点:需要接入客户端的埋点SDK, 将实际的埋点代码嵌入到用户实际访问的页面中,一般用于采集用户的行为流等等,比如点击按钮,访问页面等等。
2、服务端埋点:服务端埋点的原理和客户端埋点大体类似,只不过将埋点的主体放到了服务端,通过接入服务端的SDK后,在服务端代码中调用埋点API进行相关的埋点。两种分类各有各的好处和缺点,可以结合实际的需求来选择哪一种方式埋点。
埋点方式:

(2)企业数据埋点方案
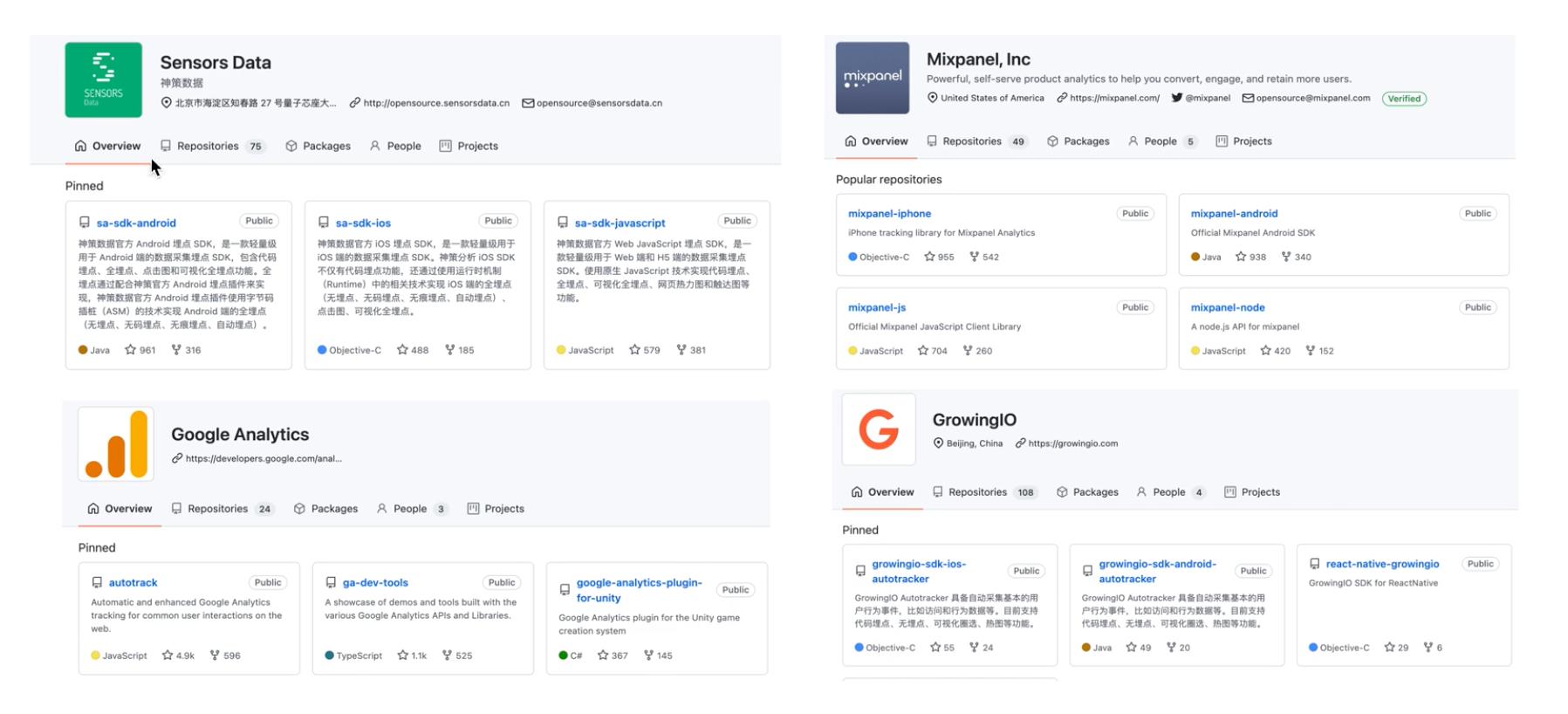
企业方案:
- 代码埋点,企业自研埋点流程。
- 使用第三方工具,如GA、MP、GIO、SD。
埋点分类:

客户端浏览器数据埋点流程:

App端的数据埋点流程:
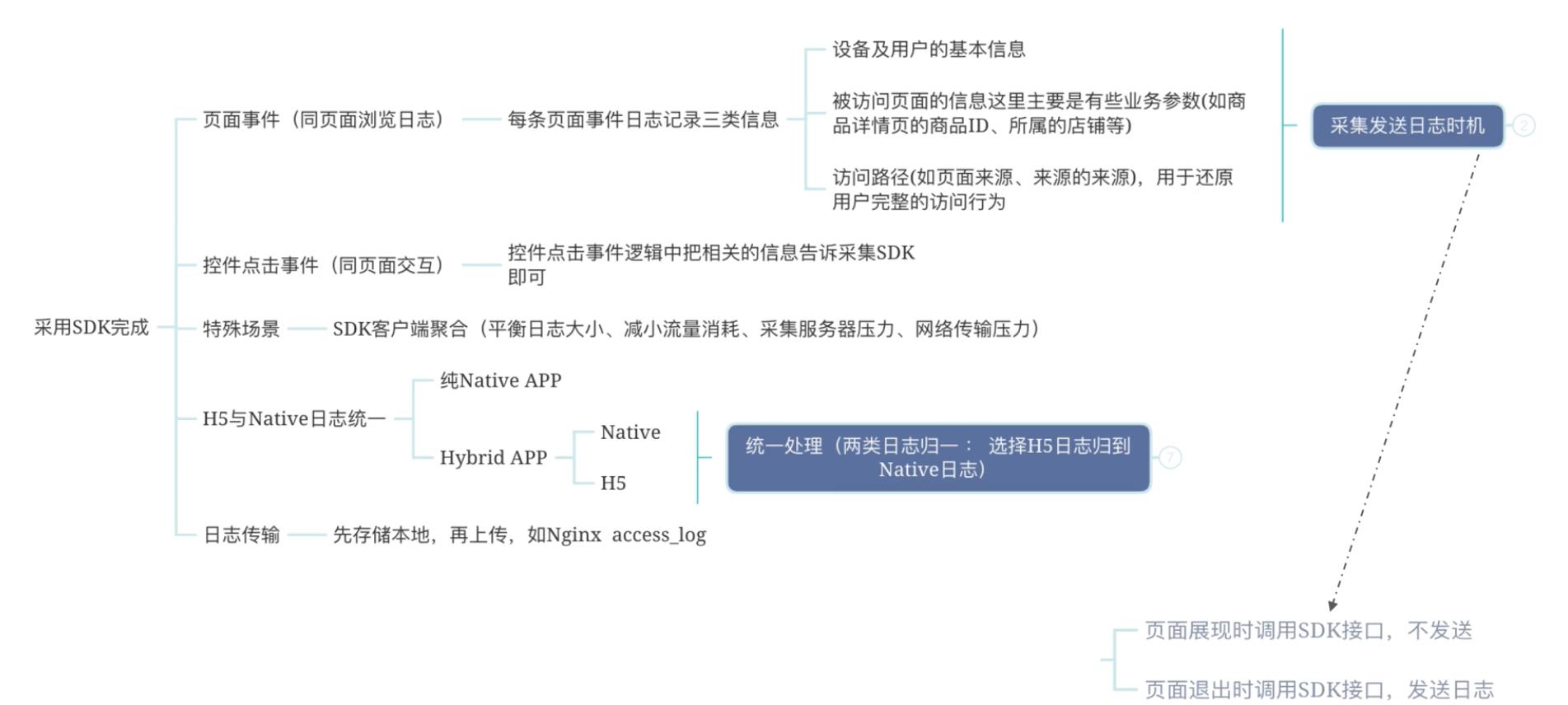
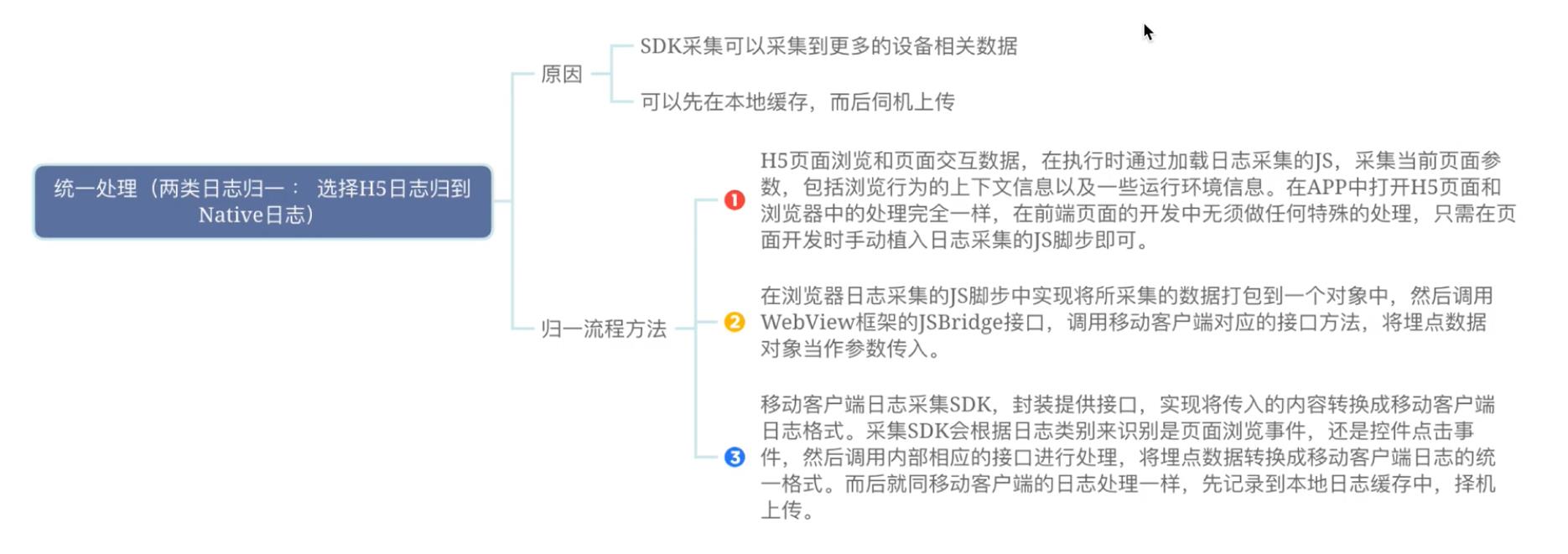
H5日志与Native日志归一方式:
第三方工具埋点方案:
埋点注意事项:
- 埋点方案提前设计,与开发同步
- 做好测试,避免白埋
- 确定埋点标识唯一性,避免数据重复
(3)企业数据同步方案
数据同步方式
- 直连同步
- 数据文件同步
- 数据文件解析
直连同步:
规定统一规范的标准接口,不同数据库基于这套标准接口提供规范的驱动,支持完全相同的函数调用和SQL实现。

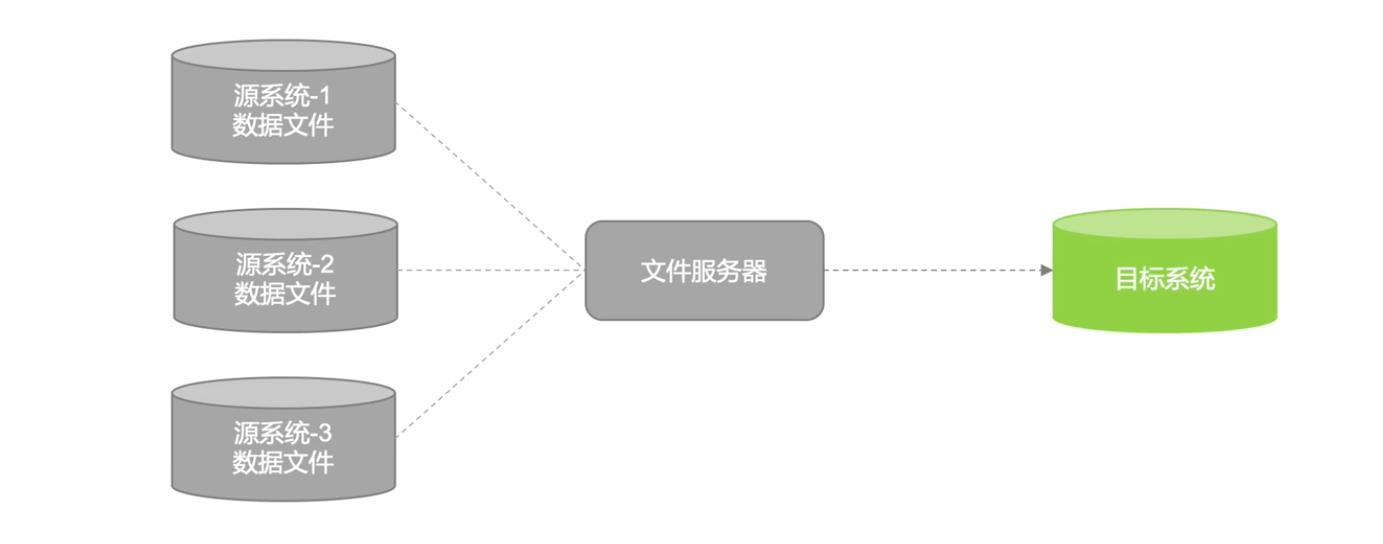
数据文件同步:
数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如FTP服务器传输到目标系统后,加载到目标数据库系统中。
数据库日志解析同步:
解析数据库日志文件获取发生变更的数据,从而满足增量数据同步的需求。
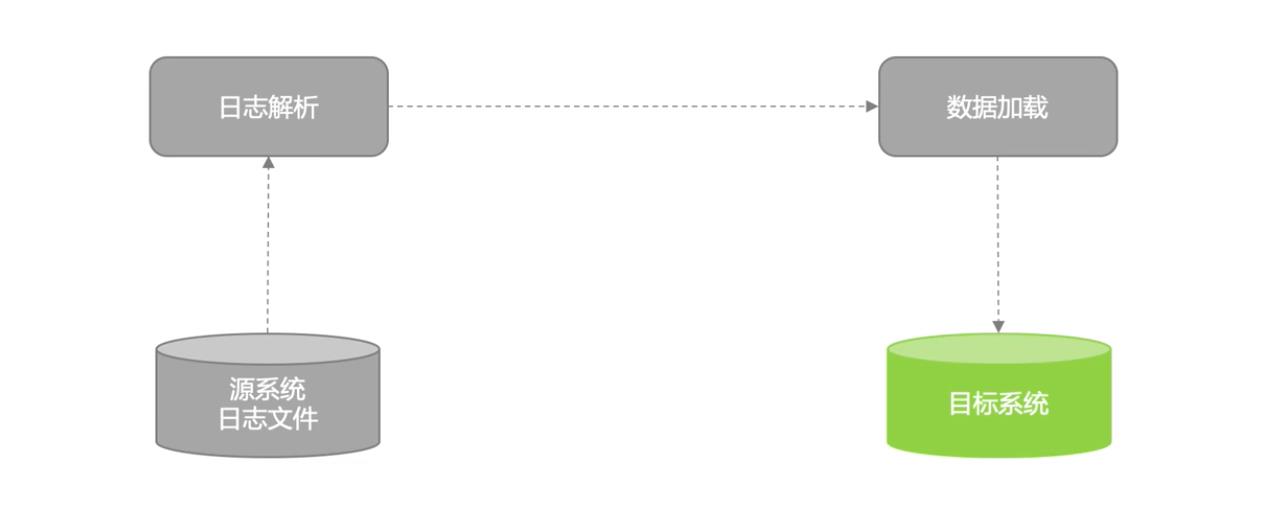
数据库日志解析同步:
数据库日志抽取一般是获取所有的数据记录的变更(增、删、该),落地到目标表时我们需要根据主键去重按照日志时间倒排序获取最后状态的变化情况。

针对删除数据这种变更,主要有三种方式
- 第一种方式:不过滤删除流水。不管是否是删除操作,都获取同一主键最后变更的那条流水

- 第二种方式:过滤最后一条删除流水。如果同一主键变更的那条流水是删除操作,就获取倒数第二条流水。
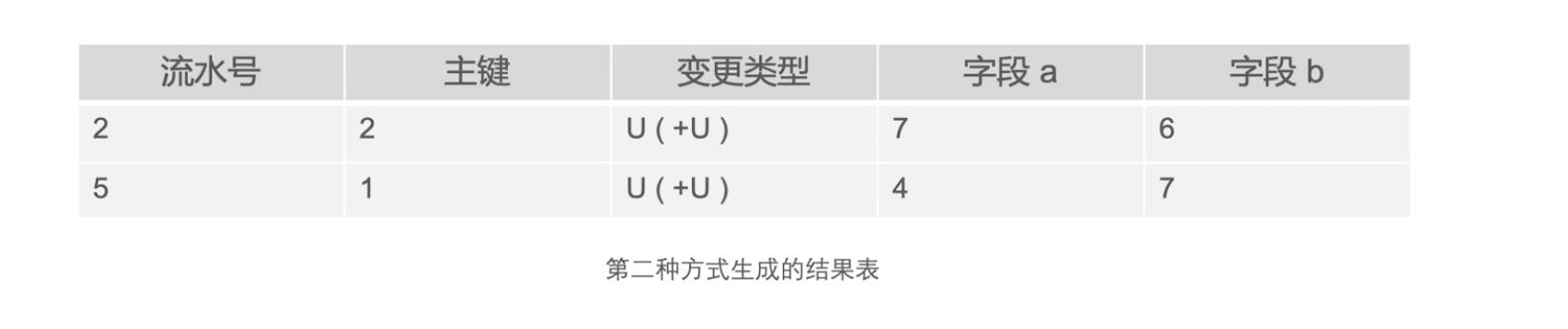
- 第三种方式:过滤删除流水和之前的流水。

实时数据基于增量同步的时候,一般情况下,可以采用不过滤的方式来处理。如: flink-connector-kafka中的upsert。
日志解析同步方式的一些缺陷:
- 投入较大
- 数据漂移和遗漏
(4)数据漂移场景及处理方案
数据漂移是指ODS表的同一个业务日期数据中包含前一天或者后一天凌晨附近的数据或者丢失当天的变更数据。
由于ODS需要承接面向历史的细节数据查询需求,这就要物理落地到数据仓库的ODS表按照时间段来切分进行分区存储,通常的做法是按某些时间字段类切分,而实际上往往由于时间戳字段的准确性问题导致发生数据漂移。
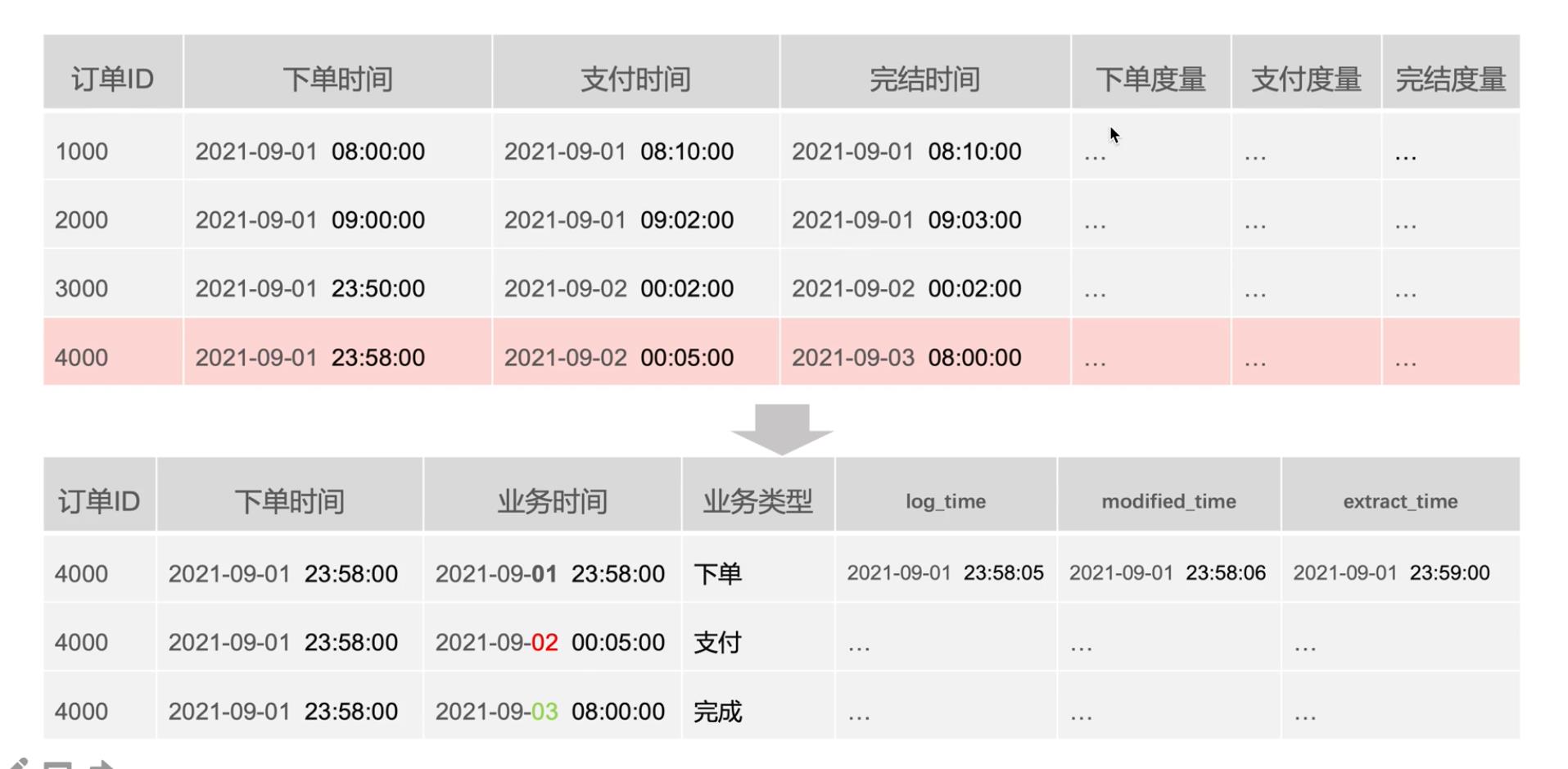
上面的数据是订单的数据,那么下面数据映射过来是要写入ODS表的数据,对于4000订单号,它的下单时间、支付时间、完成时间都是不一样的,如果是按照支付时间分区,那就分成了不同的区。这时候需要按照下单时间进行分区,对于分区要特别注意,对于分区的选择一定要讲同一个订单或者某一个订单放在同一个区。那么对于订单的这个流程为什么要放在同一个分区:一是为了顺序性,下游在处理的时候是可以放在一起的,二是对于下游处理提高性能。

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于数据埋点技巧的主要内容,如果未能解决你的问题,请参考以下文章