机器学习算法之 k-means 聚类算法
Posted 数学与人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法之 k-means 聚类算法相关的知识,希望对你有一定的参考价值。
机器学习基本概念
什么是机器学习
机器学习(Machine Learning)是一种基本数据的学习,是人工智能(AI, artificial intelligence) 领域中与算法相关的一个子领域,它允许计算不断地根据一定的模型进行学习。通常来说, 这相当于将一组数据(通常说样本)传递给算法,并由算法推断出与这些数据属性相关的一 些信息—借助这些信息,算法就能够预测出未来可能会出现的其他数据。这种预测是完全有可能的,因为几乎所有的随机数当中,都包含一些这样或那样的模式(规律),这些模式的 存在使机器能够据此进行归纳。为了实现归纳,机器会利用它所认定的出现于数据中的重要特征对数据进行“训练”,并借此得到一个模型。这个过程就叫机器学习的过程,机器学习的一般流程如下图1所示。
图1. 机器学习流程图
目前,机器学习已经渗入到多个领域,包括用户分类、网页聚类分类、广告点击率预测、精 准营销等。其中,精准营销是目前使用较广泛的领域,它能够帮助商家较准确地推断出用户 需求及喜好,及时作出精准的推销方案。在精准营销模型中,通常使用聚类算法将用户进行分类,k-means 是较常用的分类算法。
本篇我们首先给大家介绍下机器学习的基础知识,然后给大家介绍下用 spark ML(spark 做 机器学习模型)的相关知识,最后分享一个比较常用的非监督学习算法—k-means 聚类算法。
机器学习算法分类
一般来说,从机器学习输入样本的类型以及要求训练的结果来看,机器学习分为非监督学习、 监督学习、半监督学习和强化学习。其中非监督学习和监督学习使用的场景较多,而半监督学习由于对要求的样本特征比较严格,所以使用较少,强化学习则是主要用在机器人控制领域。因此,下面我们主要来介绍下非监督学习和监督学习。机器学习算法的分类如下图2所示。
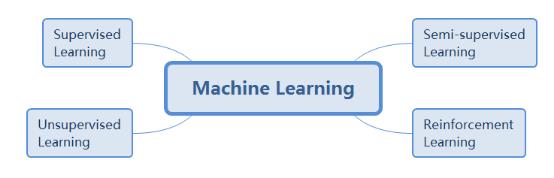
图2. 机器学习算法分类
1 非监督学习
非监督学习是没有明确的目标训练结果。它是通过对一些无标注的样本集,通过某一种训练模型找出这些样本集之间的内在联系的一种学习模式。 常见的应用场景包括关联规则的学习以及聚类。这类算法并没法制定训练结果模型是神马样子的,而是找到训练数据相互的近似关系。非监督学习包括聚类分析,非负矩阵因式分解和自组织映射等。非监督学习的常见组成类别如下图3所示。
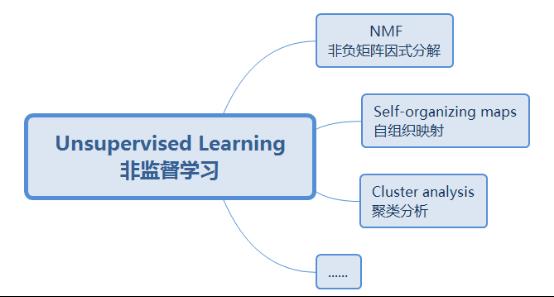
图3. 非监督学习分类
聚类是非监督学习的一个最常见的例子,聚类算法往往是对当前训练数据集中的数据点进行相似度计算,将相似的数据点聚在一起。聚类算法模型如下图 4 所示。图中,根据一定的相似度算法,将各个输入的离散样本点聚集成三个簇,每个簇内各个点的相似度较高。
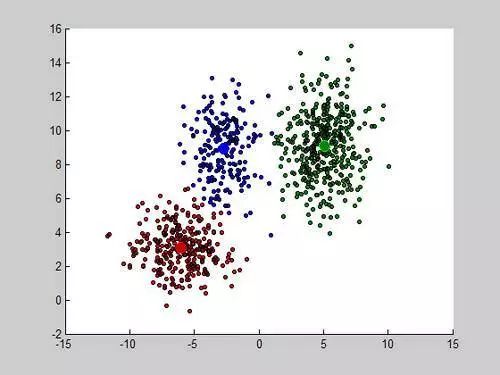
图4. 聚类算法模型
因为非监督学习使用的是事先没有分类的样本,这样可能出现更加好的分类,因为有时候我们自己拟定的分类也不一定是最佳的,因此非监督学习模型存在一定灵活性。它可以为我们提供更好的、更多样的分类策略。
2 监督学习
监督学习更多的是用来训练给定的算法模型的。它是需要同时有输入和输出的,输入要求有标记的要本,而输出是根据标记样本和模型推断的结果。它的大致过程就如下图 5:
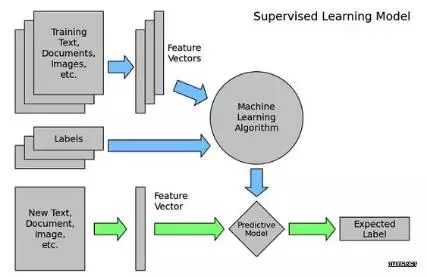
图5. 监督学习流程
图的上部分,蓝色箭头所示流程是离线训练流程,而下面的绿色部分为对训练出的模型预估的流程。详细步骤如下:
(1) 离线训练:首先对数据进行数据筛选和清洗,后进行特征抽取,后根据一定的监督学习算法训练出一个算法模型。
(2) 模型预估:首先对需要预估的数据,进行特征提取后,将其输入到离线训练出的模型中,输出预估的结果。
spark ML 简介
为什么spark适合机器学习
Spark 在机器学习方面之所以有如此大的优势,是因为 spark 有如下特征:
(1) 方便使用,支持多种语言及算法库。支持的语言主要由 scala、java、python 和 R,同时 支持多个算法库,即 SparkR 等,还能与多种数据源进行交互,即 hdfs、hbase、cassandra
等等。
(2) Spark 采用基于内存的计算,计算速度大大高于 hadoop,而机器学习的模型一般需要重复多次计算,而且模型训练需要较大的样本集,因此针对大数据的快速计算的 spark 相 对于 hadoop 当然就更适合机器学习,如下图 6 所示,对于相同的数据集,spark 要比 hadoop 的执行速度快上 100 倍。
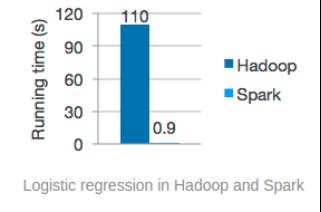
图6. spark与Hadoop执行速度对比
(3) 易于部署,可运行在多种分布式集群上,主要的部署模式有 standalone、hadoop yarn 和 mesos 等。三种主要的部署模式以及区别将在后续的文章《spark集群部署》中讲解。
由于 spark 有上述诸多优势,因此现在被广泛地用于机器学习中。spark框架中也单独提供了对机器学习的支持库spark MLib。spark的体系结构如下图7所示。
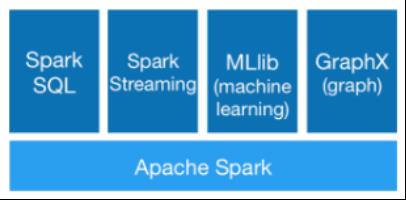
图7. spark体系结构图
spark MLib支持的算法库
spark Mlib 库目前支持 4 种常见的机器学习问题,包括分类、回归、聚类和协同过滤。Spark MLib 库目前支持的机器学习算法如图 8所示:
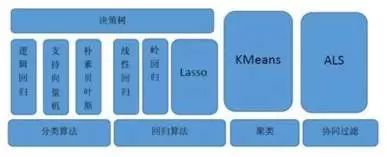
图8. MLib 库目前支持的机器学习算法
k-means 聚类算法
所谓聚类,顾名思义就是将给定的样本根据各个 样本点之间的相似度分成多个群组。k-means 算法属于非监督学习中的一种聚类算法,也是较常用的一种聚类算法,因 此,这里我们介绍下 k-means 算法的实现。
k-means 算法介绍
1 k-means算法原理
k-means算法原理用下图 9 表示:
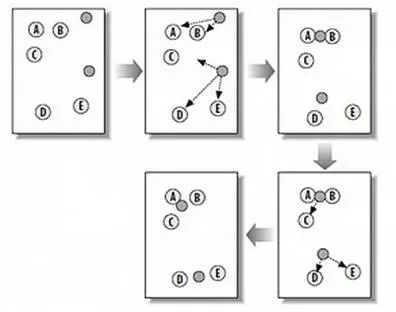
图9. k-means 算法示意图
从上图中,我们可以看到,A,B,C,D,E 是五个在图中点。而灰色的点是我们的种子点, 也就是我们用来找点群的点。有两个种子点,所以 K=2。然后,K-Means 的算法如下:
(1) 随机在图中取 K(这里 K=2)个种子点。
(2) 然后对图中的所有点求到这 K 个种子点的距离,假如点 A 离种子点 K1 最近,那么 A 属于 K1 点群。(上图中,我们可以看到 A,B 属于上面的种子点,C,D,E 属于下面中部的种子点)
(3) 接着,我们要移动种子点到属于他的“点群”的中心。
(4) 然后重复第 2)和第 3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了 A,B,C,下面的种子点聚合了 D,E)。
2 k-means算法流程
根据上述步骤,画出算法的执行流程如下图10所示。图中,(1) 到(4)步分别对应上面的(1) 到(4)。整个计算流程如下:
(1) 确定样本集,然后根据需要分成的类别数k,随机选取k个中心点
(2) 分组,将样本点X1...Xn分给离它们最近的中心点,并计算每个中心点到样本点的距离和,作为(4)判断中心点是否变动的依据。
(3) 重新选取中心点,用新的簇的均值最为新的中心点
(4) 重新计算每个样本点到中心点的距离和,与(2)中算出的距离和对比,判断中心点是否改变,即算法是否收敛。
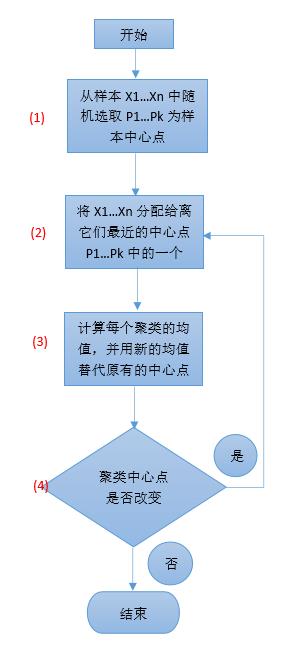
图10. k-means算法流程图
由上述流程可看出,流程中最关键的为最后三个步骤。下面我们用公式来表示后面三步所执行的操作。 以上是关于机器学习算法之 k-means 聚类算法的主要内容,如果未能解决你的问题,请参考以下文章
公式中,样本为从