kmeans聚类算法
Posted 小桂子的MachineLearning
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kmeans聚类算法相关的知识,希望对你有一定的参考价值。
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化而组间距离最大化。
Kmeans(k均值聚类)算法
在聚类问题中,给我们的训练样本是,每个训练样本没有标签,是一个非监督学习问题,我们要把这些样本划分到不同的类中。

图1展示了对n个样本进行kmeans聚类的过程,这里k=2
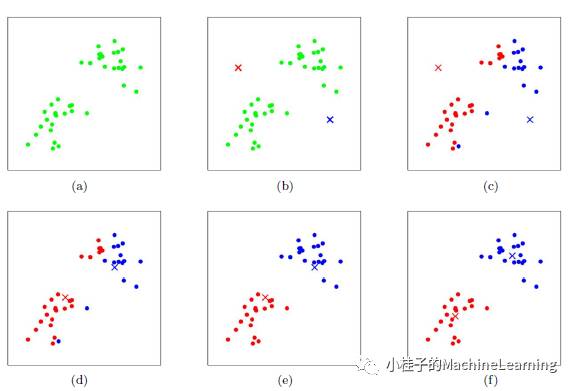
图1.分类过程
(a)图为所给的n个样本点;(b)图红色和蓝色的叉叉是随机选取的两个分类中心;(c)图将每个样本点分到距离近的分类中心的类中;(d)对红色类和蓝色类的样本点分别计算该类所有点的质心,得到新的分类中心;(e)图重复(c)图的过程,将n个样本点分到距离近的新的分类中心的类中;(f)图重复(d)图的过程,计算重新分类的点的新质心;按此步骤循环直至算法收敛。
那么kmeans算法能够保证收敛吗?我们定性分析一下:
定义畸变函数:
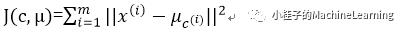
J为每个样本点到其所属类的距离的平方和。
假设J没有达到最小值,则可以固定每个类的质心不变,调整每个样本点所属的类使J减小;或者固定每个样本点所属的类不变,调整每个类的质心的坐标使J减小。而这两个过程就是kmeans算法中循环的两个过程,因而J是一个单调递减的过程,所以算法收敛。
畸变函数J是一个非凸函数,所以不能保证得到的最小值就是全局最小值,换句话说就是J有可能陷入局部最小值中。实际情况中,这种情况很少见,我们也可以多次运行kmeans算法选取其中最小值J的情况。
Kmeans算法的实现
1. Matlab 实现:
I)MATLAB对图片进行聚类分析:
rgb_image = imread('000054.jpg');
figure;
imshow(rgb_image);
title('rgb_image');
feat = double(rgb_image);
row_num = size(feat,1);
col_num = size(feat,2);
feat = reshape(feat,row_num*col_num,3); %reshape feat矩阵使得feat矩阵的每一行一个像素的点的特征
k=3;
[label,C,sumd] = kmeans(feat,k,'distance','sqeuclidean', ...
'Replicates',1);%按照像素点的特征聚类,分为k类。Label为分类标签,C为分类心的坐标,sumd为每个类的点到中心点的距离总和
pixel_labels =reshape(label,row_num,col_num);
figure;
imshow(pixel_labels,[]),title(‘聚类后的图片’);

原图

聚类后的图(k=3)
II)MATLAB对数据点进行聚类分析
Matlab kmeans Document例程:
rng default; % For reproducibility
Y =[randn(100,2)*0.75+ones(100,2);
randn(100,2)*0.5-ones(100,2)];
figure;
plot(Y(:,1),Y(:,2),'.');
title 'Randomly Generated Data';
opts =statset('Display','final');
[idx,C] =kmeans(Y,2,'Distance','cityblock',...
'Replicates',5,'Options',opts);
figure;
plot(Y(idx==1,1),Y(idx==1,2),'r.','MarkerSize',12)
hold on
plot(Y(idx==2,1),Y(idx==2,2),'b.','MarkerSize',12)
plot(C(:,1),C(:,2),'kx',...
'MarkerSize',15,'LineWidth',3)
legend('Cluster 1','Cluster2','Centroids',...
'Location','NW')
title 'Cluster Assignments and Centroids'
hold off
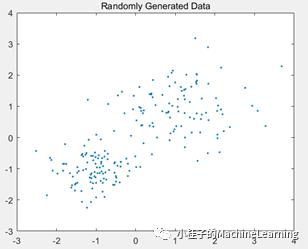
原图
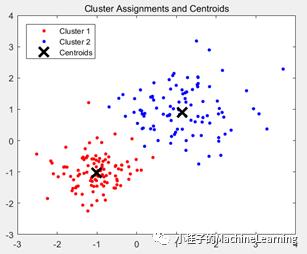
聚类后的图
2.Python实现:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from sklearn.cluster import KMeans
import pickle
rgb_image = mpimg.imread('images/000186.jpg')
#reshape rgb_image 使得每个像素点的特征作为一行
reshape_image=rgb_image.reshape(rgb_image.shape[0]*rgb_image.shape[1],rgb_image.shape[2])
k=3
labels = KMeans(n_clusters=k).fit(reshape_image) #用reshape_image 数据集训练kmeans模型
print labels
pickle.dump(labels,open('kmeans.pkl','wb')) #将训练好的kmeans模型保存到磁盘
labels_mat =labels.labels_.reshape(rgb_image.shape[0],rgb_image.shape[1]) #reshape标签矩阵
for i in range(k):
labels_mat[np.where(labels_mat==i)] = (255.0/(k-1))*i #k-1等分0~255,按照标签的大小顺序分配像素值
print labels_mat.shape
plt.imshow(labels_mat)
plt.axis('off')
plt.show()

原图
聚类后的图(k=3)
加载训练好的模型,对新输入的数据点进行分类
以上是关于kmeans聚类算法的主要内容,如果未能解决你的问题,请参考以下文章