LDA聚类算法及其应用
Posted RM数据工作室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LDA聚类算法及其应用相关的知识,希望对你有一定的参考价值。
思想简介
Latent Dirichlet Allocation是Blei等人于2003年提出的基于概率模型的主题模型算法,LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中的潜在隐藏的主题信息。该方法假设每个词是由背后的一个潜在隐藏的主题中抽取出来。
对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
1.对每一篇文档,从主题分布中抽取一个主题
2. 从上述被抽到的主题所对应的单词分布中抽取一个单词
3. 重复上述过程直至遍历文档中的每一个单词。
当求解出tassign-model.txt后,其他输出都可以通过tassign-model.txt计算得出。
LDA图模型
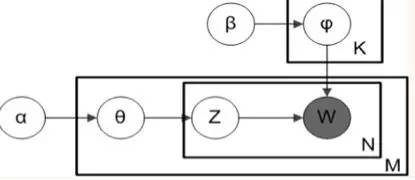
图中的阴影圆圈表示可观测变量(observed variable),非阴影圆圈表示潜在变量(latent variable),箭头表示两变量间的条件依赖性(conditional dependency),方框表示重复抽样,重复次数在方框的右下角。这里对应了LDA的生产过程。
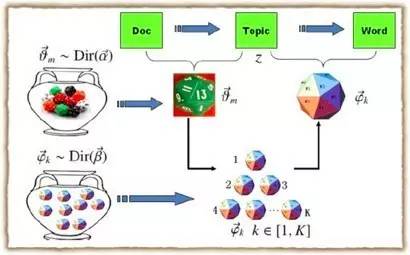
每次生成一篇新的文档前,上帝从服从α为参数的Dir分布的坛子中抽取出一个doc->topic骰子,然后重复以下步骤:
i. 投掷这个doc->topic骰子,得到一个topic编号z。
ii. 从服从β为参数的dir分布的坛子里共K个topic-word骰子中选择编号为z的那个,投掷这枚骰子,于是得到一个词。
Gibbs Sampling
怎么得到θ和φ的后验估计?有贝叶斯公司知道,后验通过先验和似然进行计算。
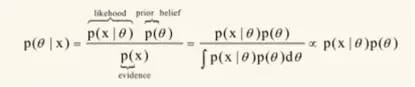
直接计算θ和φ的分布是有困难的,这里采用通过计算每篇文章的每个词所属的主题,然后在计算θ和φ的分布。这里是多维随机过程,可以证明在经过多轮抽样后随即变量收敛。证明过程这里不作讨论。在初始情况下,对每篇文章的每个单词设置随即的主题,然后开始抽样过程,我们从代码来解读sampling过程。
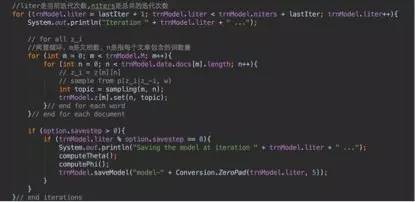
这里的第一层循环是每次迭代,第二层循环是语料集的每一篇文章,第三层循环是文章的每一个词,训练里是sampling函数,来具体看看里面是什么:
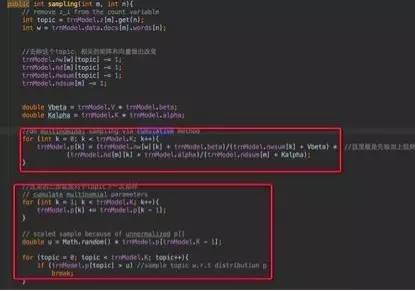
注意第一个红框,求的值为第m篇文章的第n个词选取k为主题(乘号后面的值)并且在k主题下选取w作为词(乘号前面的值)的概率。每个值都是似然加上先验,似然即为从语料中和上一层迭代得到的结果,先验即为超参alpha和beta。为什么是直接相加,则是dir分布的参数被称为伪计数的原因。(这里不作证明)。
第二个红框是怎么得到下一个抽样的过程,由上已经得到主题k的所有概率,把这里值加和在一起,然后在[0,sum(p(k))]的均匀分布抽样u,如果u在哪个p(k)里那么k即为抽样值。
结果展示:

LDA应用
1、 相似文档发现
这个方法可以被用作新闻推荐中,正文详情页的“相关推荐”,该方法所述的相似文档是指的“主题层面”上的相似,这就比其他的基于word来挖掘的相似度更有意义。

模型输出文档下主题的分布文件theta-model.txt,计算两个文档分布的差异。常用的距离有:海林格距离和KL距离(相对熵)。
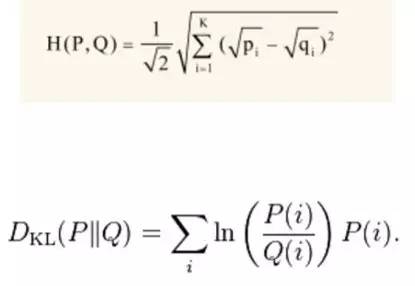
2、 新闻个性化推荐
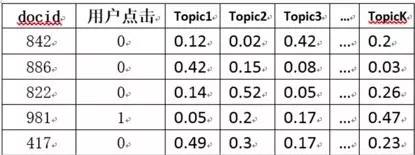
方法一:LDA+LR.通过LDA训练得到的theta文件,可以得到上图右部分。再通过用户的点击为标签,通过LR做有监督训练,得到所有主题的权重Wi,再用这个weight向量对每篇新的新闻文章使用线性加权公式: doc_score = w1 * topic1 + w2 * topic2 + …,从大到小按照score排序后,可以立即为用户提供个性化推荐。
方法2:user profile记录喜好topic法算法步骤:
1.提取topic:文章LDA训练后的theta文件,提取每篇文章概率最大的前3个topic主题
2.save topic—>user profile:当用户访问文章A后,就把文章A的top 3的topic贴到用户兴趣档案里,并将概率分值相加,如果过了1天用户没有访问网站或访问这个topic的文章,就按照该topic乘以0.8衰减,直至衰减到0。
3.产生推荐:下次用户再次访问网站时,从用户兴趣档案找出用户最感兴趣(分值最大)的k个topic,然后选取这几个topic下热门的文章为用户推荐。
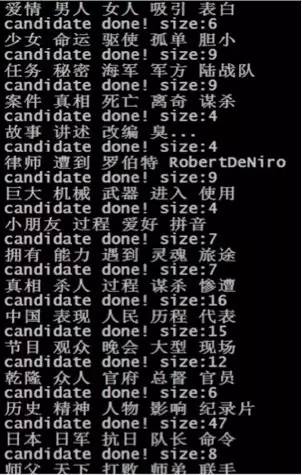
3、 自动打标签
算法实现也很简单,需要模型输出的theta和phi文件。根据该文章最大主题编号找出该文章下该概率最大主题编号下的概率最大n个word词(max top n),(换句话说:该文章最大主题下的最大概率的n个词)作为该文章标签输出。
4、 wordRank
目的:是选取当前文档下具有代表性特征的词。方法:读取phi文件,由于phi中的概率值是topic—>word 的,而我们需要的是word—>topic的反向关系,因此计算Wc={Wc1,…Wck},计算公式如下,也即是将 phi 文件矩阵转置后归一化(这里的大写K是主题总数,c是当前词)。然后计算与噪音向量[1/k,…,1/k]的距离。下面是一个汽车语料得到的结果:

wordRank的结果可以帮助分类器作特征选择。例如我们需要按照店家给出的商品标题描述分类,但是,如果你仔细观察店家给出的商品标题,会发现如下情况:店家为了增加他们被搜索命中的机会,通常在标题上填写很多重复冗余无用的信息,比如图上的标题中“套头”这个词的意思是:没有扣子或者拉链的,必须从头上套着穿的。但是这个词是不能用作分类的依据的,搜索时我只想按照商品的主要特征词来分类,而非“套头”。
LDA的应用有很多,它只是一个中间结果,我们可以在这个中间结果基础上做出自己的运用,上面的应用也可以进行优化。
以上是关于LDA聚类算法及其应用的主要内容,如果未能解决你的问题,请参考以下文章