数据挖掘之聚类算法——从女星三围数据谈起
Posted DataLearner
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘之聚类算法——从女星三围数据谈起相关的知识,希望对你有一定的参考价值。
声明
本文仅仅是利用三围数据进行严谨的研究学习,没有任何对女性不尊重的意思。阿祖非常热爱女性同胞,天地可鉴,特此声明。
关键词:聚类分析,R语言应用
这次主要介绍数据挖掘中基本的分析方法:聚类分析(Cluster Analysis)。
中国有一句老话,叫“物以类聚,人与群分”,讲的就是相同属性的东西、人总是可以聚为一类。这大概就是聚类的基本思想。顺便提一下,大陆叫聚类,台湾叫分群,讲的都是同一个东西,都能从老祖先的话里找到依据。所以,台湾是中国神圣不可分割的一部分。请支持一个中国,请支持九二共识。

回到我们的题目,让我们从三围数据谈起吧。假设你有一组女星的三围数据,如下图所示(截图只展示了部分数据,数据来源于网络)。你想按照身材数据把这些女明星分成若干个不同的组,那么当然身材好的就应该分到一组。换而言之,我们的聚类的依据就是把身材接近的人放到同一个类别。那么问题来了,我怎么样说她们身材是否接近呢?
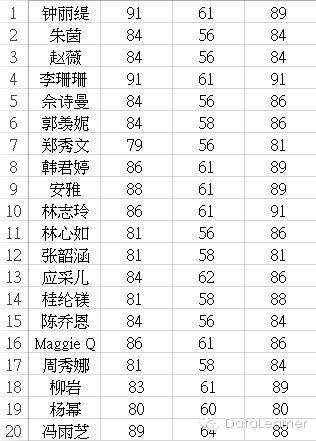
我们可以看到,在我们的三围数据中,一共有三个维度的数据。比如例子中的钟丽缇小姐三个维度的数据分别是91,61,89. (女神当年真是美得不要不要的啊!!当然,现在也是超正的!!!)

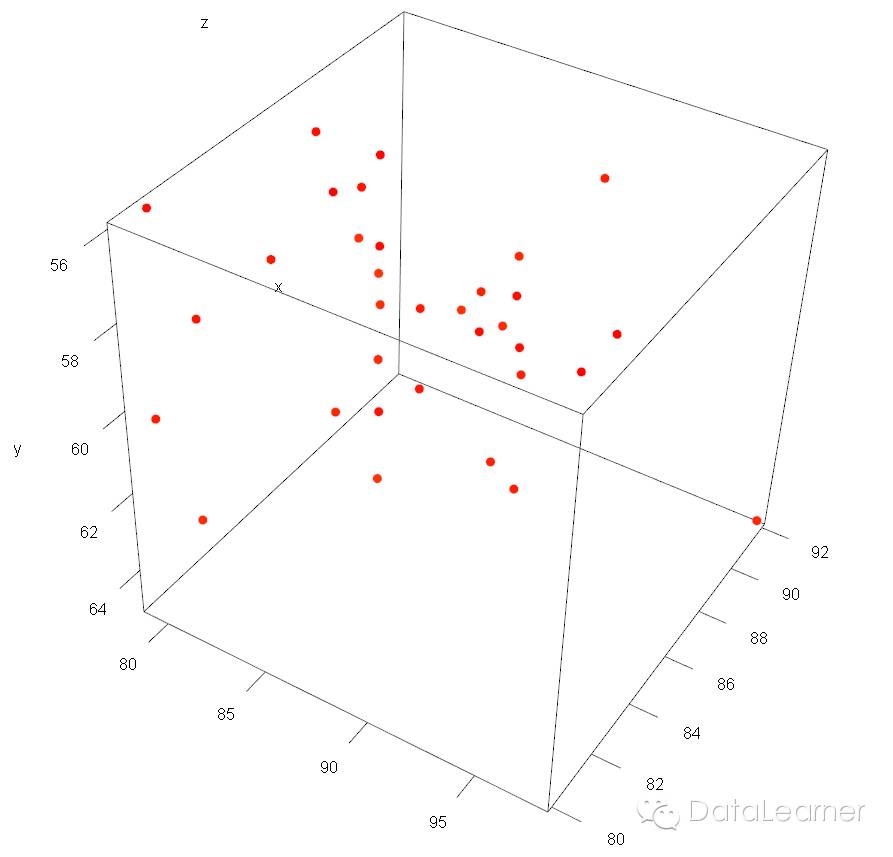
因此,我们就可以根据点与点之间距离的远近,把这些点聚成若干个类。在数据挖掘中,距离的衡量方式有很多种,本文采用大家最熟悉的欧氏距离(Euclidean distance),也就是点与点之间的真实距离进行聚类分析。我们借助上一篇文章介绍的工具R语言进行分析,采用的聚类算法是k-means。k-means算法,简而言之就是把n个点划分到k个聚类中,使得每个点都属于离他最近的一个聚类。(详细的k-means算法的介绍大概也许maybe会在之后的文章中介绍到。)
首先,我们用以下指令导入数据,并绘制出如上图所示的数据分布图:
接着,我们就可以进行聚类了。这时候,问题来了,我们要把他们聚成几类呢?也就是k-means的k要选择多少呢?在实际应用中,会根据具体的情况选择聚类的数目,或者根据聚类情况的好坏选择聚类的数目。
我们先假设聚成三类,我们可以通过下面简单的代码实现。第一行就是调用kmeans函数进行聚类;第二行是画出聚类之后的效果图;第三行是输出聚类的结果,也就是每个女明星应该属于哪个类。
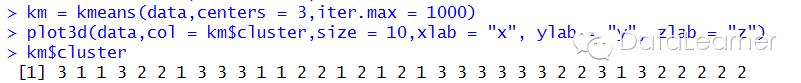
当我们分成三类的时候,聚类的结果如下图所示(也就是第二行代码实现的效果)
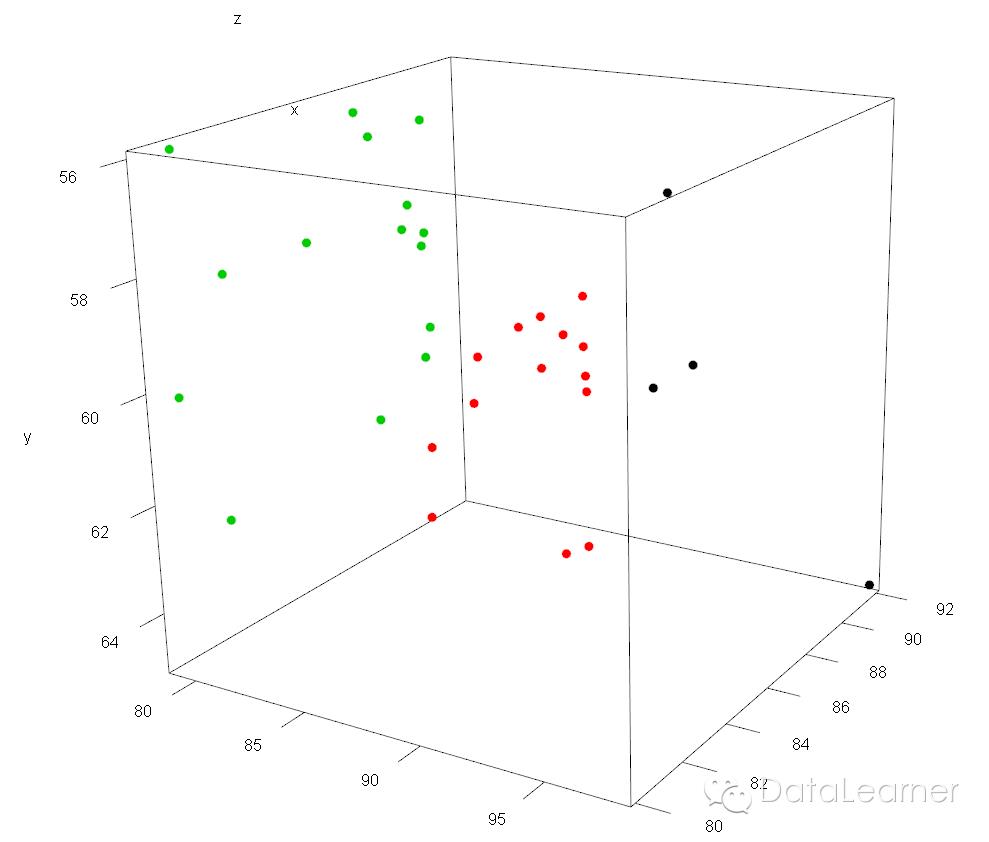
我们可以看到,图中相同颜色的点属于相同的聚类。三个聚类之间似乎有无形的界限把她们分隔开了,真是冥冥之中早已注定啊。
但是,可能你觉得这个分类的效果还不够好啊,右下角那位姐姐明明甩其他姐姐几条街的啊,于是你想,要不分四类分五类看看。于是,我们采用上述同样的代码,只是分别修改参数center = 4与center = 5,于是就有了:
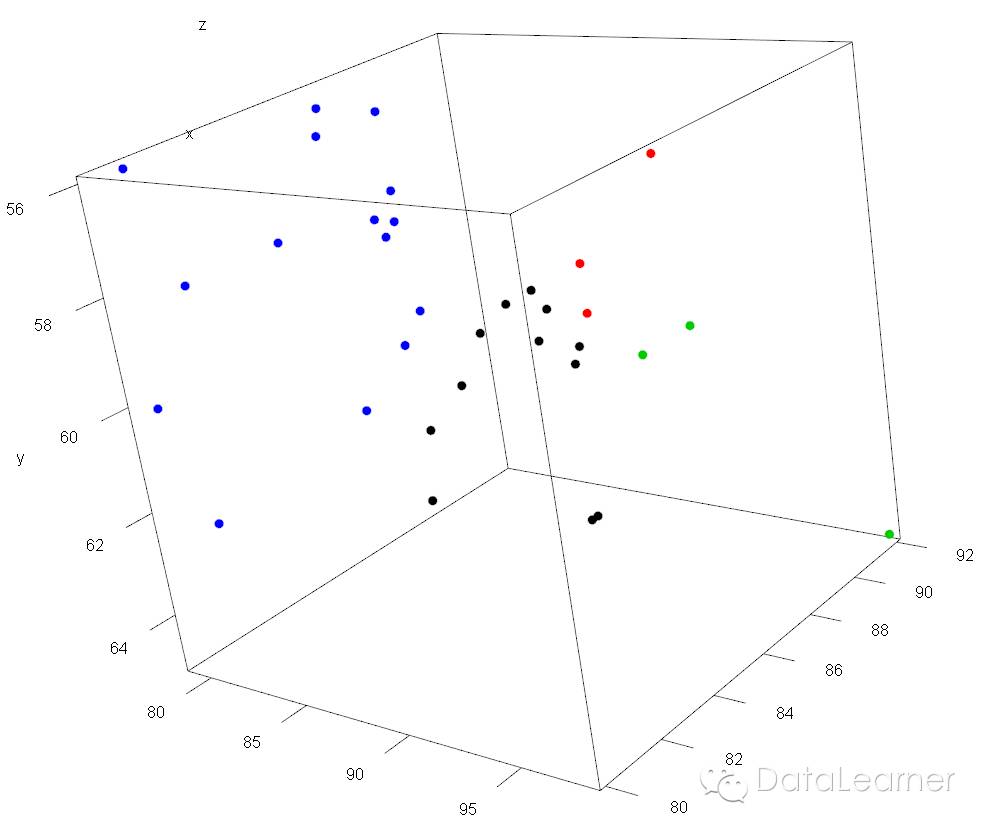
如上图,数据就被聚成了四个类。
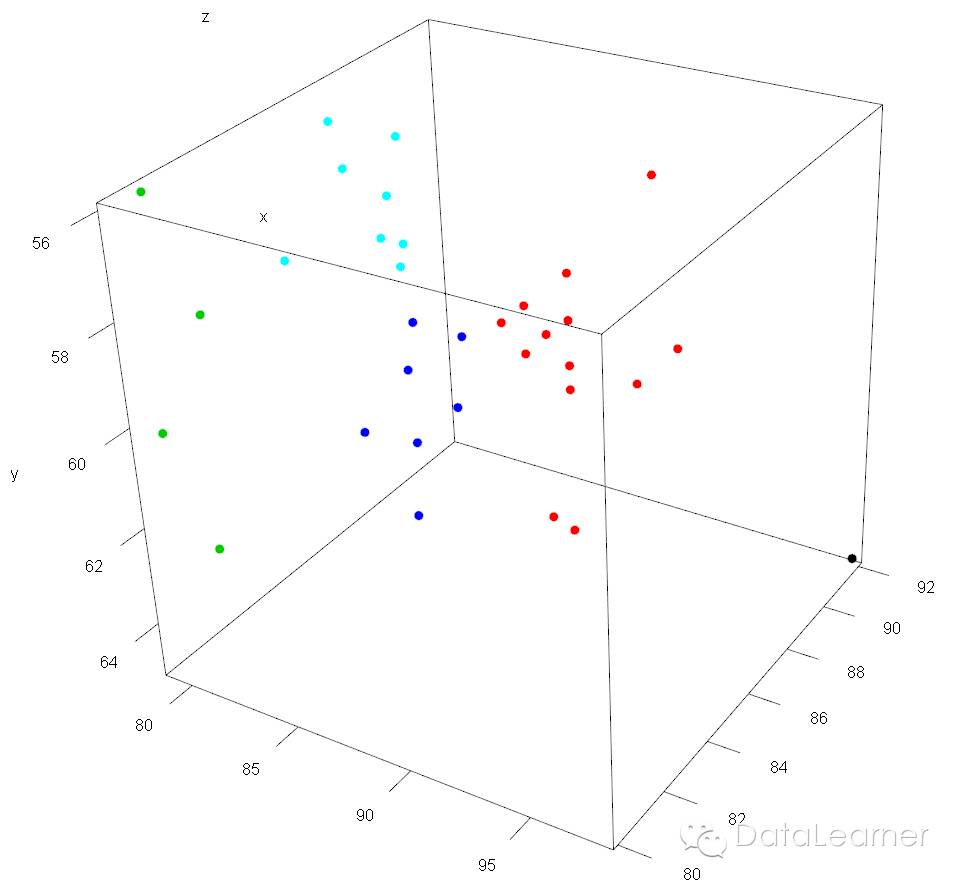
如上图,数据被聚成了五类。到了这里,右下角的那位姐姐终于自成一个聚类了。恭喜恭喜!!而其他四个聚类里的姐姐也都显得挨得蛮近了,真是姐妹情深。再次印证了老祖先的话,“物以类聚,人以群分”啊!!!

自此,我们就成功地把女明星按照三围的数据聚成了若干个不同的类别。
拓展一下,假如这里的数据不是三个维度的数据,而是更多维度的数据,比如加上身高、体重、年龄等等各种特征,我们也是一样可以根据点与点之间的距离来对这些点进行聚类。只是这个时候,这些代表了女明星的点就不是在一个三维的空间里而是在五维、六维甚至更多维度的空间里面了。记得以前有一次参加一个比赛,要根据一群教练执教的水平分成几个不同的等级,当时我们就是用聚类的方法去做,将执教水平相近的教练聚到同一个类里去。
在这里多说几句,这篇文章中我们举了三围数据作为例子,但是,即使我们对三围数据是什么不了解也不是很重要。因为阿祖也不是很清楚三围到底是什么。(认真脸) 在这里,我们只要知道这三个特征可以用来表示一个人的身材就够了。当这些特征(feature)被确定下来以后,所有的数据就只是一些数字的组合而已,正如本文例子中,每一个数据就是表示一个点而已。这也是数据挖掘、数据分析的一个特点。
下一篇文章会介绍分类分析,题目暂时就叫做《数据挖掘之分类算法——从女神相亲经历谈起》。(excuse me?女神需要相亲?) 聚类与分类的区别,会等分类介绍完,再做一些比较。
如果你坚持读到了这里,请接受来自阿祖最真挚的感谢。阿祖在这里想请教各位两个问题:1. 敢不敢关注我一下? 2. 敢不敢分享一下?
*文中女星三围数据、女星图片及表情图片均来自网络,侵删。
以上是关于数据挖掘之聚类算法——从女星三围数据谈起的主要内容,如果未能解决你的问题,请参考以下文章