有关迭代大数据的聚类算法都在这里
Posted 化学数据联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有关迭代大数据的聚类算法都在这里相关的知识,希望对你有一定的参考价值。
现如今的企业正在处理爆发增长的数据,这无疑是公司发展中所面临的对打的挑战之一。赢得这个挑战的必杀技就是通过一种及时快速的方式提取、分析并做数据的处理。Clustering(聚类)无疑是分析大数据所用的一种必备的挖掘工具。但是由于很多领域当中的技术处理过程会产生大量的信息,这让大规模数据聚类已成为一项极具挑战性的任务。因此,研究人员已经使用并行编程模型处理并行聚类算法的难题。MapReduce是其中最具盛名的架构之一,由于架构本身的灵活性、变成简单以及容错性能受到了行业的青睐。但是这个架构依然存在明显的性能局限性,尤其是在处理迭代项目时。本次研究首先对将支持MapReduce支持扩展迭代算法所提出的迭代架构进行了综述。我们对这些技术进行了总结和概括,讨论了它们无可比拟的优势及限制并解释了它们是如何处理迭代项目的问题。为了帮助增强问题的理解,我们进行了深度回顾。因此我们相信使用MapReduce时候它并不会提供面面俱到的并行聚类算法的显著比较结果。本次研究的目的就是想为广大研究大数据聚类算法的科研人员提供进身之阶。
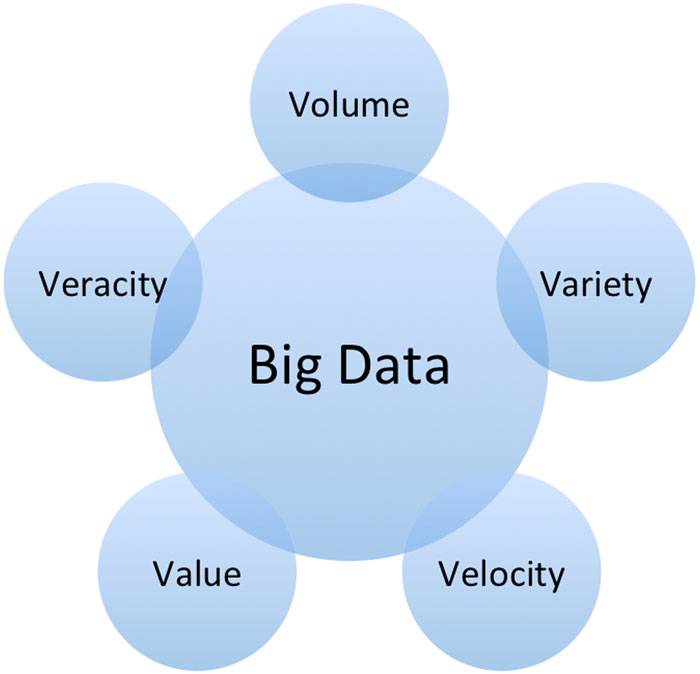
图1.大数据的5V特性
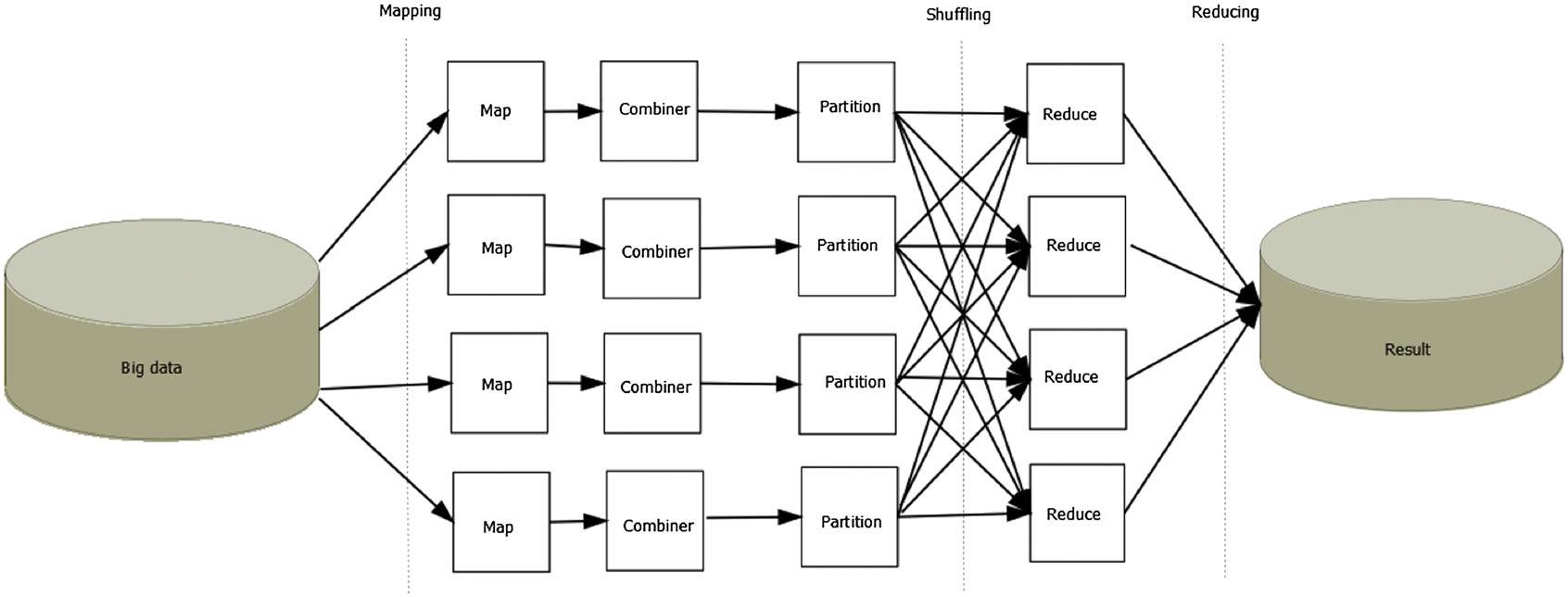
图2. MapReduce 体系结构
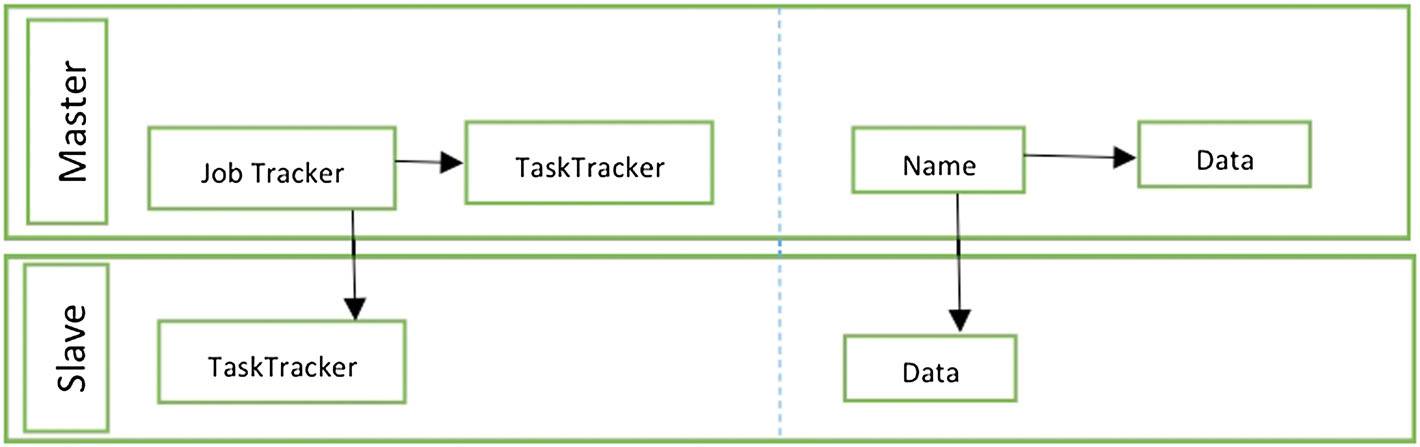
图3. Hadoop分布式文件系统和MapReduce在Hadoop中的铺设
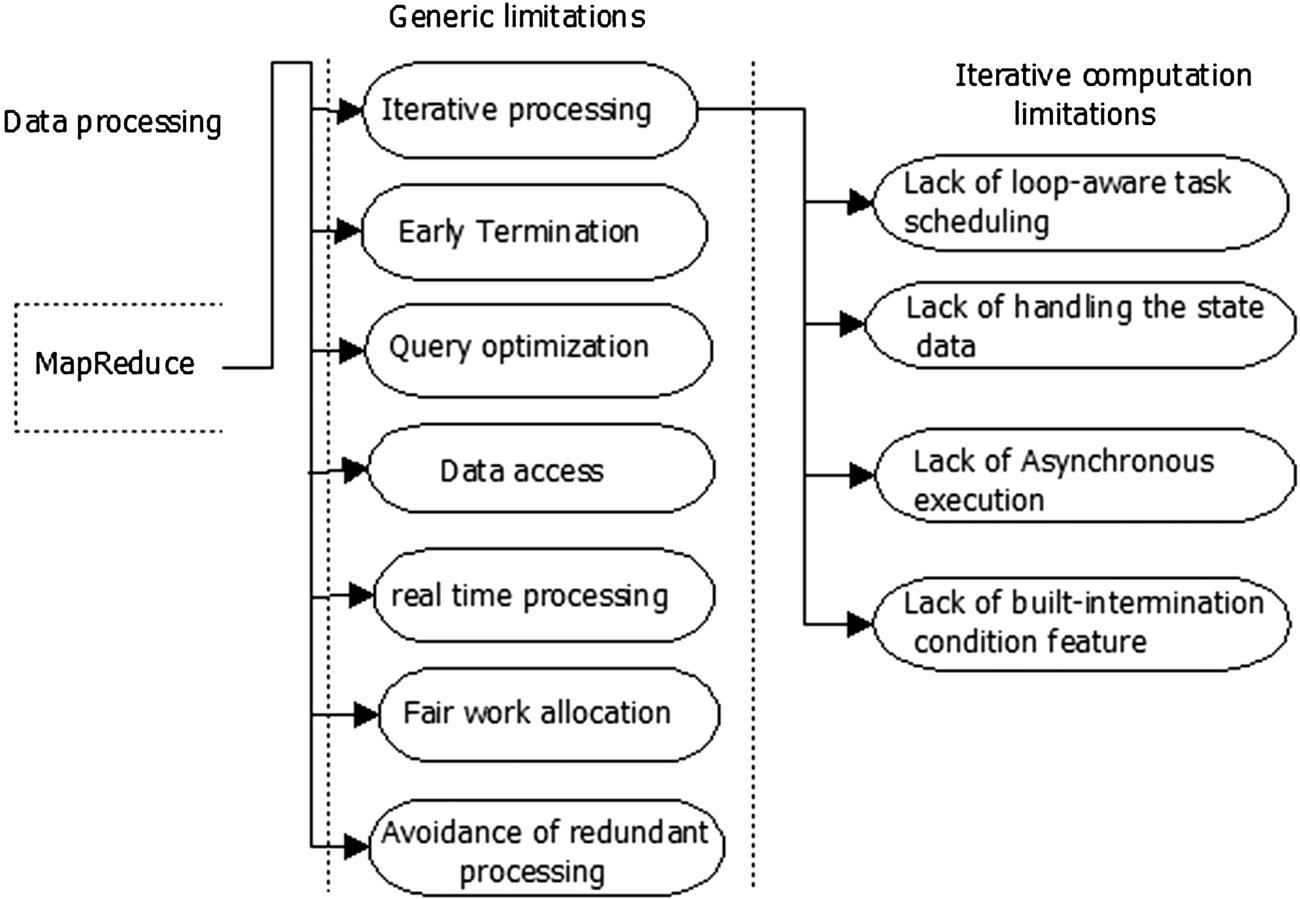
图4. MapReduce的局限性
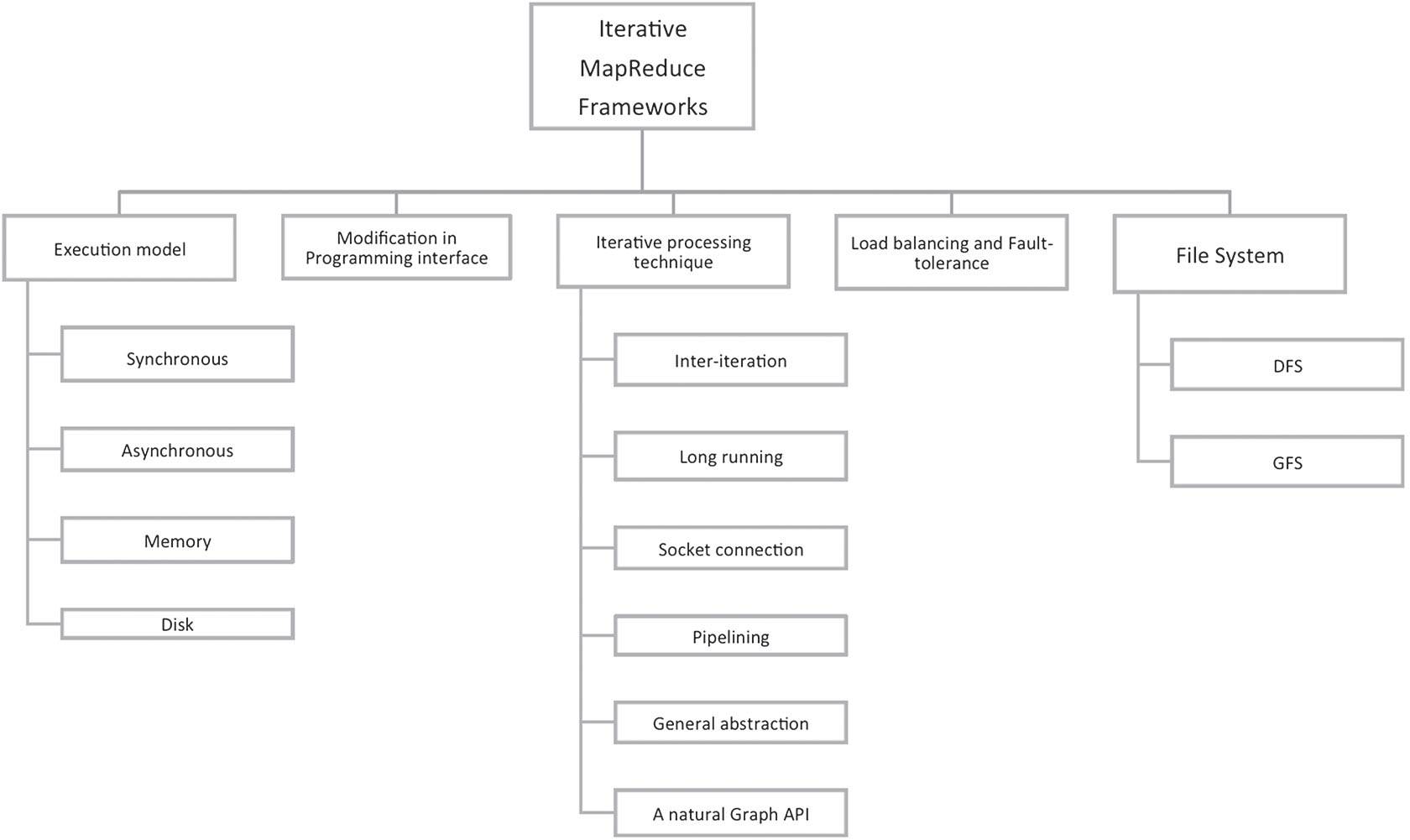
图5. 迭代MapReduce架构的分类系统
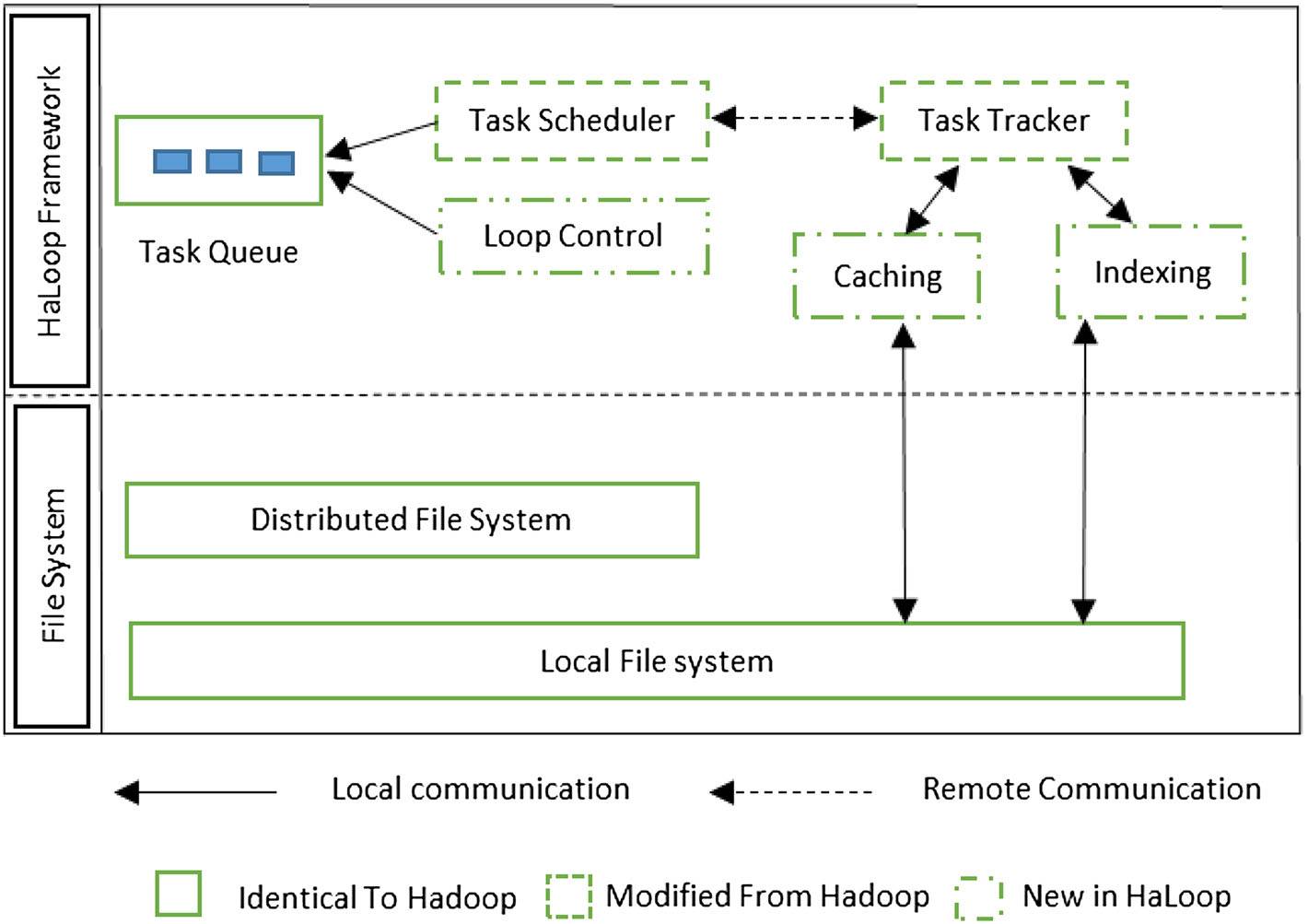
图6. Haloop 架构
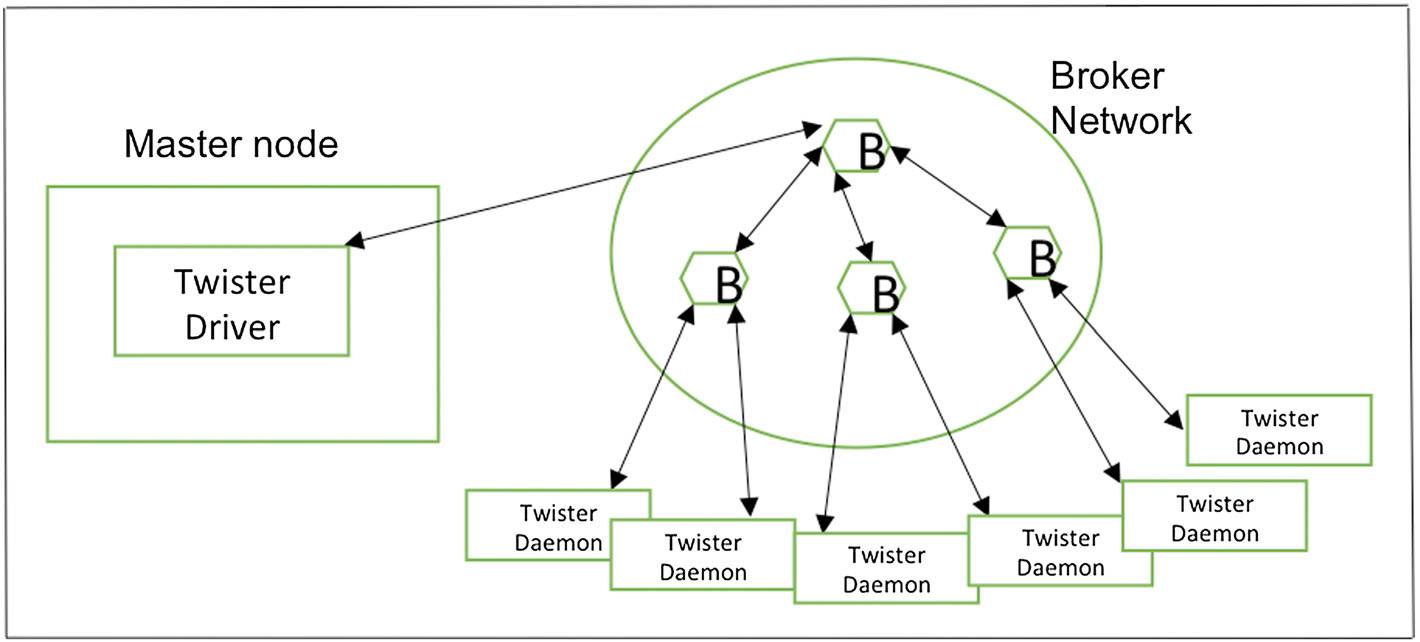
图7. Twister架构

图8. IMapReduce的数据流
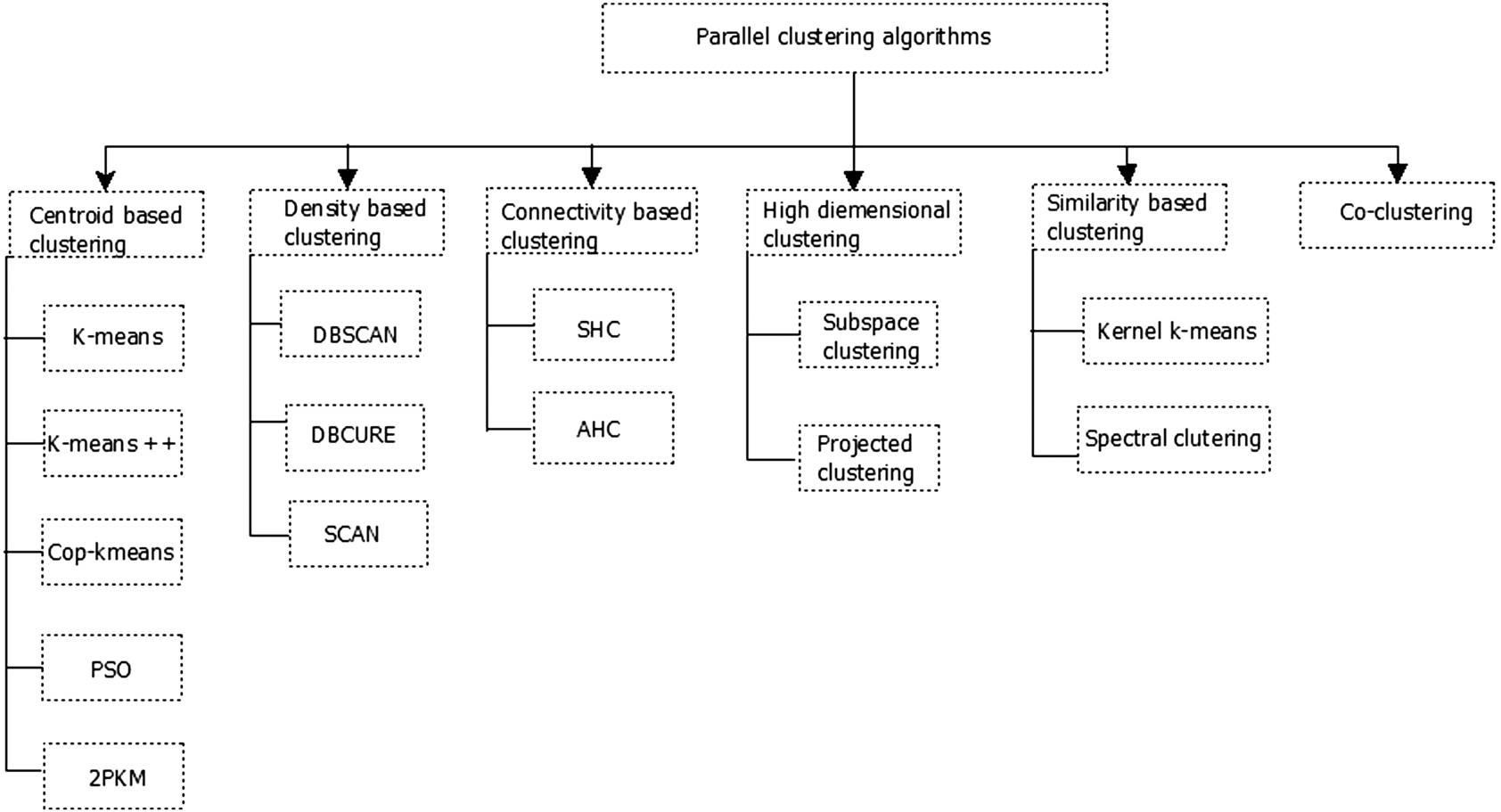
图9. 并行聚类算法的分类系统
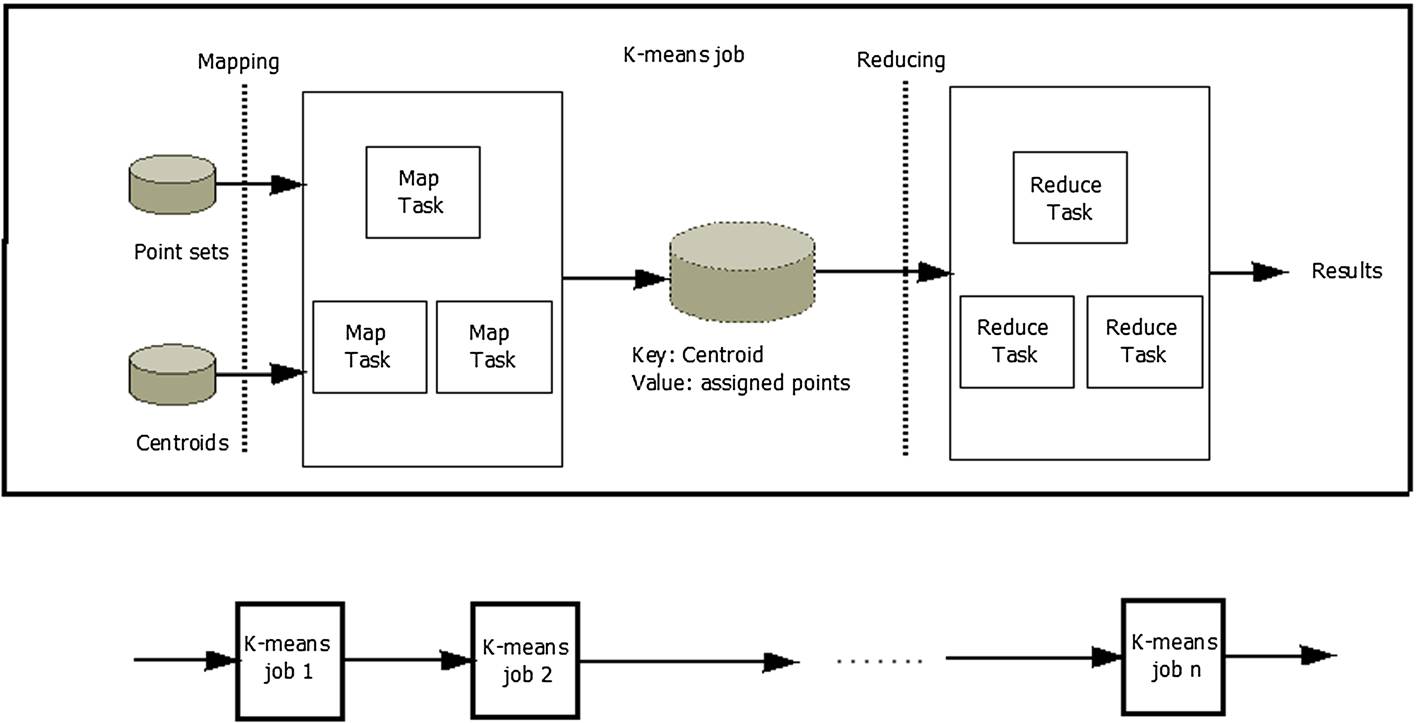
图10. 并行k均值为基础的MapReduce
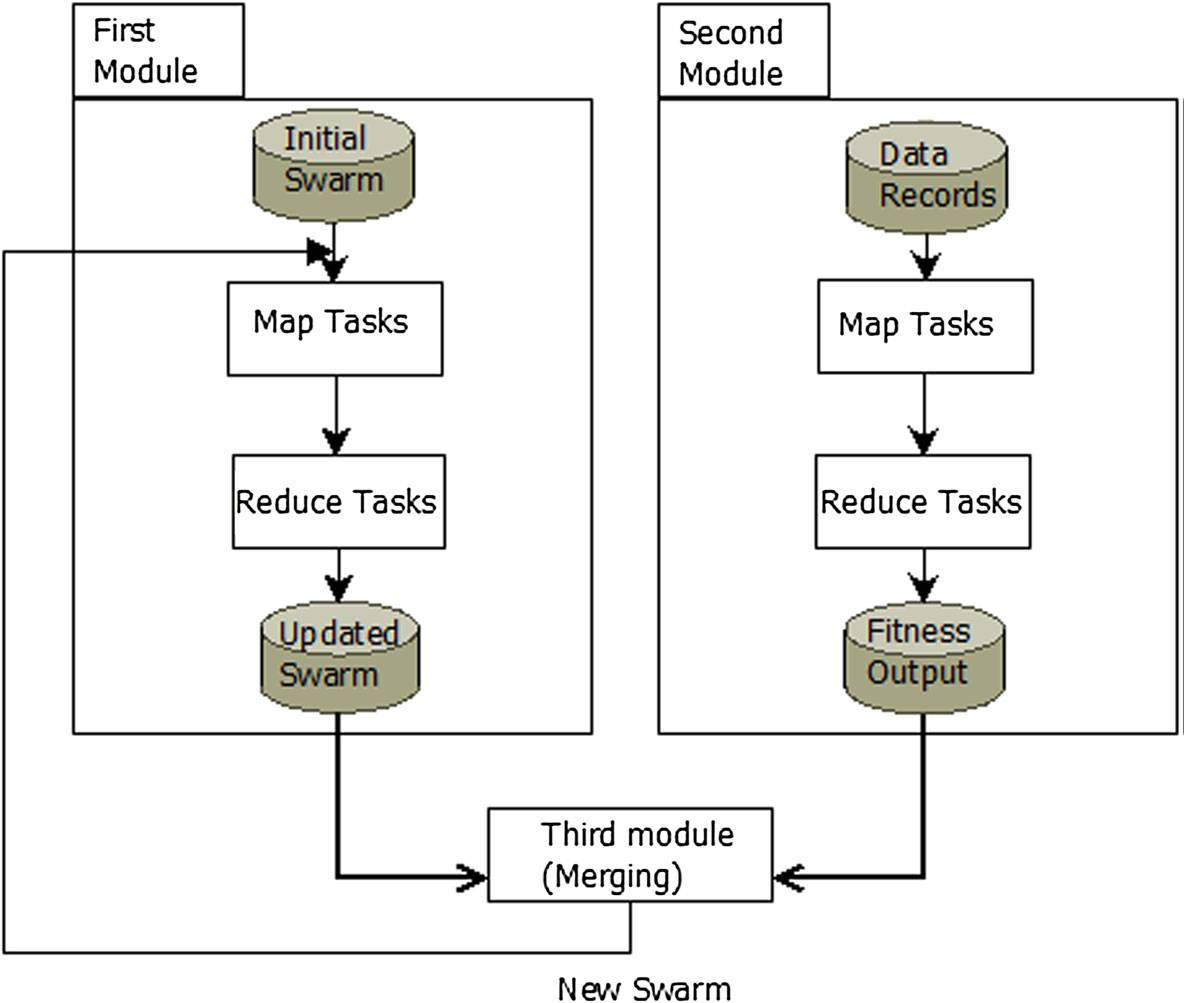
图11. 粒子群优化结构
图12. 平行分层聚类的阶段
崭新的领域,等待更多新研究。数据正在以指数速度迅速增长,但是并行处理模型的进步速度相对缓慢。我们发现MapReduce在处理迭代应用的时候存在局限性。除此之外,引入几个重要大数据并行处理模型的最新工艺和技术仍旧不能解决迭代算法的问题。
概括来说,本次研究的主要发现主要有以下几点:
很有必要从长计议并行处理模型的设计,设计要结合现存并行处理模型的指标,以便于让算法具有更好的容差能力,并可以支持迭代算法。
但是MapReduce/Hadoop的执行不支持迭代工艺,但是这不应该成为终结MapReduce的原因。这是因为MapReduce和迭代算法比较比较的时候,前者的发展更加成熟,而且很多供货商也支持这种技术。因此混合系统是处理迭代大数据算法的备选方案。
并行数据处理有助于改进庞大数据集的聚合时间,但是也会降低质量和性能。因此主要中心就是在大数据的内容的质量和速度之间做出恰当的取舍。
找到能够被并行处理的聚合算法的综合研究目的并未达成。值得注意的是,找到可以淘汰算法固有依赖性的方法是最大的挑战。
大部分实验使用的是标准MapReduce,因此,研究方向很可能是运用更加平行的聚合算法。
除非特别注明,本站所有文章均不代表本站观点。报道中出现的商标属于其合法持有人。请遵守理性,宽容,换位思考的原则。
本文由本平台编辑编译,并经化学数据联盟首发,转载请注明化学数据联盟。
点击“阅读全文”,了解详情
以上是关于有关迭代大数据的聚类算法都在这里的主要内容,如果未能解决你的问题,请参考以下文章