5分钟学会K均值聚类算法
Posted ItStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5分钟学会K均值聚类算法相关的知识,希望对你有一定的参考价值。
 我 相 信 这 么 优秀 的 你
我 相 信 这 么 优秀 的 你
已 经 置 顶 了 我
K均值(K-means)算法
算法介绍 :
K-means是一个常用的聚类算法来将数据点按预定的簇数进行聚集。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
MLlib工具包含并行的K-means++算法,称为kmeans||。Kmeans是一个Estimator,它在基础模型之上产生一个KMeansModel。
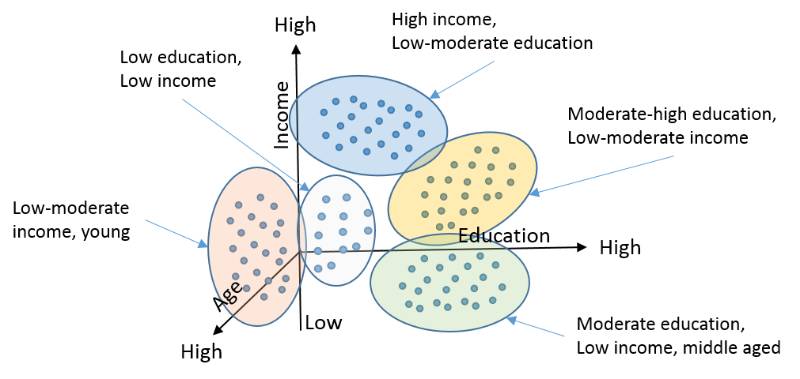
K-means的意义和使用场景:
在无任何先验分类知识的情况下,自动发现数据集的分类。例如:
在大量文本中发现隐含的话题;
发现图像中包含的颜色种类;
从销售数据中发现不同特征顾客的分类。
算法步骤
假设希望将训练数据集x^{(i)} (i = 1, 2, 3,..., m)分为K类;
在x^{(i)} (i = 1, 2, 3,..., m)中,随机选择K个作为初始分类的图心(centroids) mu _{1}, mu _{2}, mu _{3},..., mu _{K};
遍历x^{(i)},计算出和每个x距离最近的图心mu ^{(i)},记录当前x属于第i类;
遍历K种分类,分别计算上一步中,划归其中的所有x点的中心点,将该点设置为本分类中心的图心;
迭代上两步,直到图心位置收敛。
Matlab仿真:K-means过程
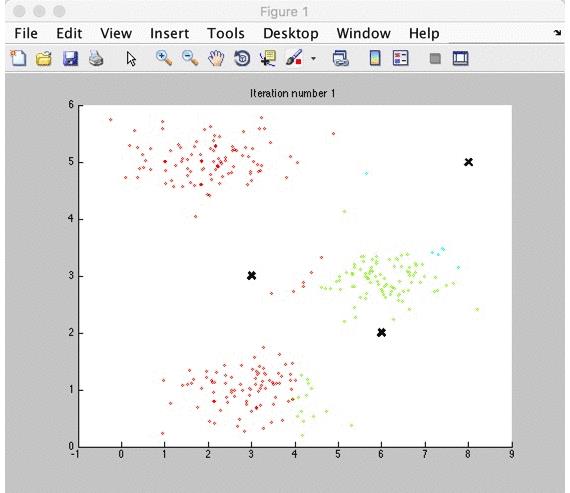
随机初始化 Random Initialisation
由于初始的图心是随机选择的,K-means可能陷入局部最优而导致最终的图心无法收敛到合适的位置。可以使用随机初始化来解决这个问题:
多次运行K-means算法,计算c^{(1)},..., c^{(m)}, mu _{1},..., mu _{k};
计算Cost Function J = (c^{(1)},..., c^{(m)}, mu _{1},..., mu _{k}),函数代表了聚类的失真程度;
选择J最小的那一组初始化以及最终的计算结果。
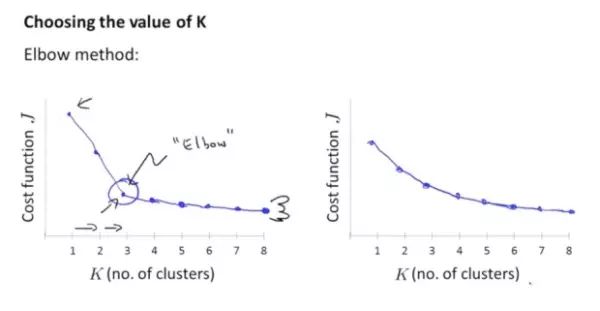
选择聚类数量
使用「肘方法」Elbow Method
逐渐增加K,并分别计算Cost Function J,寻找J较小的K,如图:
理论上,当分类数量K增大时,J将逐渐变小;
但也可能陷入局部最优的问题,导致k增大时,J反而增大。此时需要重新随机初始化后再次计算。
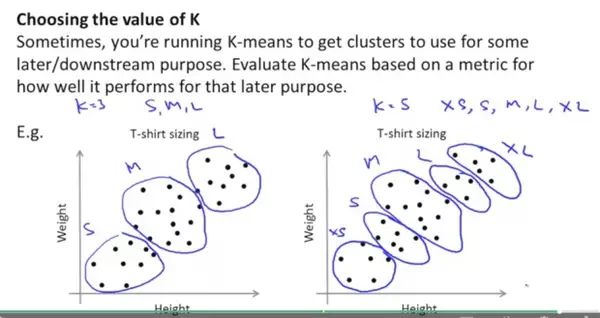
Ng推荐的办法:向自己提问「我为什么要使用K-means」?充分理解聚类的需求以及聚类后能向下游贡献什么东西,往往能从中发现真正合适的聚类数量。例如下图:
横轴为衣服店顾客的身高,纵轴为顾客的体重。当你理解了顾客可能分为「S、M、L」三类,或者「XS、S、M、L、XL」五类时,最终选择的分类数量可能比较make sense,而不是完全依赖Cost Function算出一个10类或者4类,最终并没有太大实际意义。
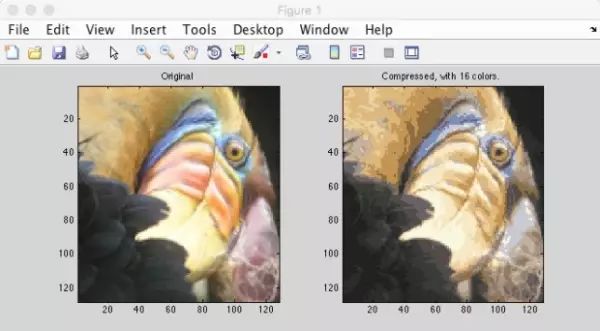
实践:使用K-means压缩图像
思路:
对一个RGB图像执行K-means算法,寻找能描述图像的16种主要颜色分类;
将每个像素点聚类到这16种颜色分类中,并分别替换为对应分类的颜色;
对每个像素使用颜色的索引来代替3维的RGB亮度值,由此可以将图像的大小压缩到六分之一
仿真图:
如果想对算法进行更一步的学习,或者想查看源代码的同学,可以扫描下方下方海报的二维码或者直接搜索程序员小助手的微信,更有原价199元一次的ItStar大咖提高班课程免费开放给大家,想报名的同学赶快加入吧!

听说点赞和分享的朋友都已走上人生巅峰
以上是关于5分钟学会K均值聚类算法的主要内容,如果未能解决你的问题,请参考以下文章