如何使用K-MEANS聚类算法解决分类问题
Posted SAS建模
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用K-MEANS聚类算法解决分类问题相关的知识,希望对你有一定的参考价值。
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
对于聚类问题,我们事先并不知道给定的一个训练数据集到底具有哪些类别的标签,只是先行设定分类类别的数量,然后通过K-means算法将具有相同特征或者相似特征的数据样本聚集到一起,形成分组。之后,我们可以根据每一组的数据的特点,给定一个相应的类标签。
要了解K-MEANS算法,先要了解两个概念,第一是质心,第二是距离。
首先说一下质心,质心可以认为就是一个样本点,或者可以认为是数据集中的一个数据点P,它是具有相似性的一组数据的中心,即该组中每个数据点到P的距离都比到其他质心的距离近。 k个初始类聚类质心的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的质心,初始地代表一个聚类结果,当然这个结果一般情况不是合理的,只是随便地将数据集进行了一次随机的划分,具体进行修正这个质心还需要进行多轮的计算,来一步步逼近我们期望的聚类结果:具有相似性的对象聚集到一个组中,它们都具有共同的一个质心。 另外,因为初始质心选择的随机性,可能未必使最终的结果达到我们的期望,所以我们可以多次迭代,每次迭代都重新随机得到初始质心,直到最终的聚类结果能够满足我们的期望为止。
然后是距离,距离实际上是相似性的度量,其定义也有很多种,常见的有:街区距离,欧式距离,闵可夫斯基距离等。一个好的距离定义一般满足一下四个条件:
d(x,y)=d(y,x)
若x不等于y,则d(x,y)>0
若x等于y,则d(x,y)=0
d(x,y)小于等于d(x,z)+d(z,y)
K-means算法的过程
1. 随机选择N个质心;
2. 计算数据集中数据点分别属于哪一个质心所在的组中,将数据集中所有数据点聚成N个组;
3. 根据上一步计算得到的N组数据点,分别重新计算出一个新的质心;
4. 重复步骤2-3,直到计算得到的质心与上一次计算得到的质心的距离变化很小(满足指定阈值,或收敛);
5. 再次读入所有观测,将每个观测归类到与其距离最近的质心所在的类,分类结束。
K-means算法代码
proc fastclus data=数据集 <seed=>|<maxc=>|<radius=>|<maxiter=>|<out=>;
var 变量;
run;
选项seed=用来指定作为类种子的数据集;
选项maxc=指用户允许聚类分析生成的分类数目的最大值;
选项radius=是更新聚类中的的阈值;
选项maxiter=为最大迭代次数;
选项out=则是输出数据集;
var语句用来指定进行聚类分析的变量。
K-means算法应用案例
在当今NBA联盟有着众多三分投射好手,但是,同样为三分射手,球员们也有着不同的功能属性,这里我们就采用K-MEANS算法对2015-2016赛季三分球命中率排名前50的三分高手进行聚类,试图将这些三分好手们分成不同类别。
首先,我们从场均三分球投射次数以及场均三分球命中次数这两个维度进行分析观察。
proc fastclus data=nba maxc=5 maxiter=10 out=clus;
var three_point_made_per_game three_point_attempt_per_game;
run;
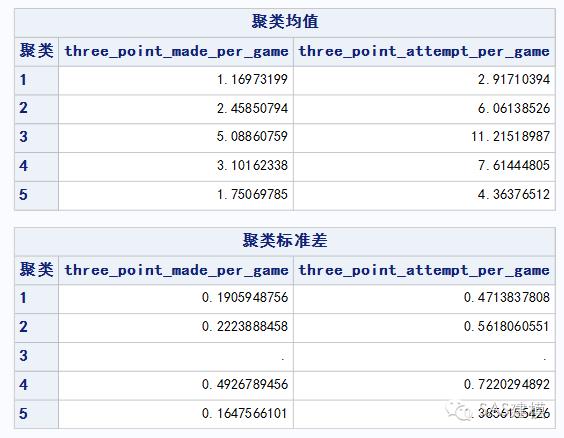
样本中的50位当今NBA顶级三分射手中,三分命中率均在38.2%以上。我们将所有球员分为5类, 其中我们发现库里自成一派(组3),汤普森和罗瑞紧随其后(组4)。
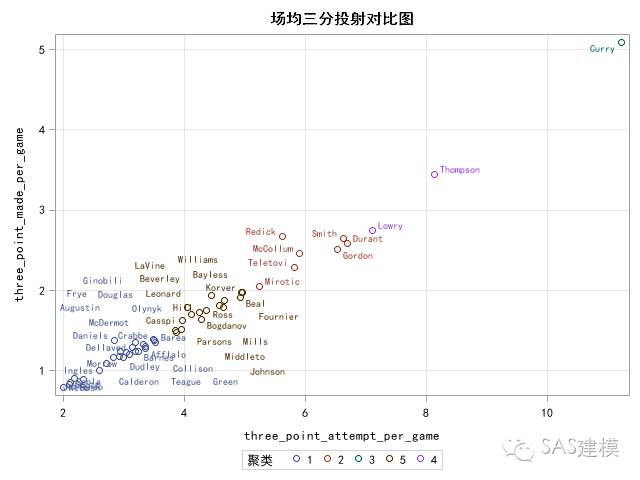
下赛季即将加盟勇士的KD也位列第三梯队(组2)。。。
看到这个之后对手们都是这样的。。。

我们再从三分命中率和两分命中率的角度来看看聚类的结果。
proc fastclus data=nba maxc=5 maxiter=10 out=clus;
var two_point_FG three_point_FG;
run;
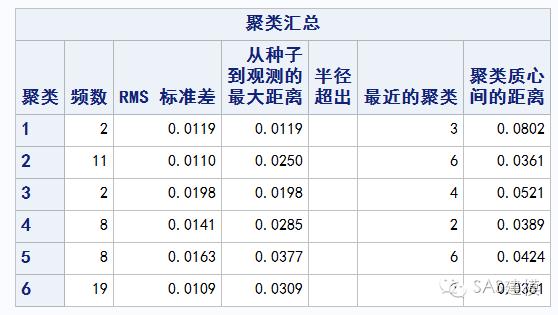
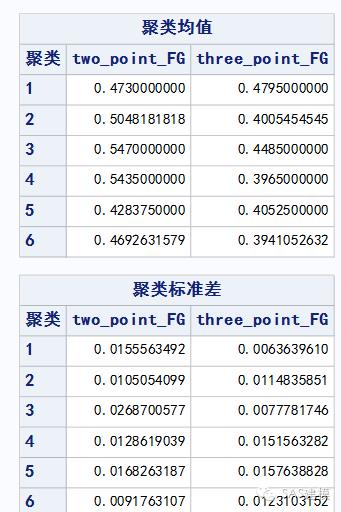
通过对三分命中率和两分命中率进行聚类分析将样本中50位顶级三分射手划分为6类。我们可以对这6组球员进行归纳。
1. 顶级专职三分射手:雷迪克,丹尼尔斯。
2. 球队稳定得分点:汤普森,卡尔德隆,科沃尔等。
3. 高效的进攻杀手:库里,伦纳德。
4. 高效的锋线刺刀:杜兰特,帕森斯等。
5. 主要轮转球员:史密斯,拉什等。
6. 拥有大量球权的明星球员或稳定得分点:麦科勒姆,希尔等。
当然,综合考虑出手权以及命中率可以得到更好的聚类效果,大家不妨一试。
数据源:http://www.basketball-reference.com/
后台回复“职位”可获得最新内推职位信息
以上是关于如何使用K-MEANS聚类算法解决分类问题的主要内容,如果未能解决你的问题,请参考以下文章