大数据实战第11期:Kmeans聚类算法做薪酬学历分析
Posted 云会计大数据前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战第11期:Kmeans聚类算法做薪酬学历分析相关的知识,希望对你有一定的参考价值。
云会计大数据智能研究所

我想学Python
Hello,大家好!
这里是重庆理工大学CABD Team大数据战队数据分析组,在上期,采集组的小伙伴就异常处理问题为大家做了生动的讲解。我们分析组也不甘示弱,在分享过利用朴素贝叶斯分类器进行数据分类后,本期为大家带来数据分析与机器学习上用于聚类的算法——k-means算法。通过k-means聚类算法,我们将对薪酬学历数据集进行聚类分析。
01
什么是聚类和Kmeans
今天说聚类,我们必须要先理解聚类和分类的区别,很多人第一眼看聚类,就会将其与分类混为一谈。

分类是从特定的数据中挖掘模式,作出判断的过程。比如邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,邮箱就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。为什么邮箱能够实现自动过滤呢?这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,邮箱分类器就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”,这就是分类。
聚类的根本目的也是把数据分类,但不同的是事先我们是不知道如何去分类的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。在聚类的结论出来之前,我们是完全不知道每一类有什么特点的,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。
02
利用Kmeans算法进行薪酬学历的分类
同样使用三家招聘网上网络爬虫得来的数据,经过文本处理,得到三个csv数据文件,分别命名为“1.csv”、“2.csv”、“3.csv”。
步骤
第一步:需求模块导入
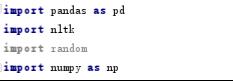
在编译器里导入pandas、nltk、random、numpy模块。具体操作如下:
第二步:文本信息转换
使用edu_type函数将学历的文本信息数字化。具体操作如下:

第三步:数据读取与合并
引入数据文件,即csv文件,使文件矩阵化。去掉矩阵的第一列,提取处理好的第四列数据,将处理好的矩阵上下合并。具体操作如下:

第四步:k-means分类器设计
将上一步骤处理好的数值进行for循环带入分类器,进行分类。具体操作如下:

第五步:学习信息文本化
方便清晰看见聚类效果,将学历信息重新文本化,具体操作如下:

第六步:运行代码,输出结果
对数据集中每一行数据进行分类,并对相同类别进行聚类。
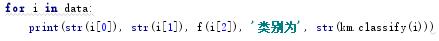
部分结果:

聚类结果分析:
我们可以看到对于不同的特征值,Kmean聚类器1做出了四种分类,四种分类的特点通过分析为:
0代表着该类工资较高,学历要求也较高
1代表着该类工资最高,且学历要求最高
3代表着该类工资一般,无特别学历要求
4代表该类工资一般,且学历主要以大专、本科为主

03
总结


项目总指导:程平 教授、博导
CABD Team大数据战队数据分析组
图文来源:王爽 王立宇 (2017级MPAcc)
文字排版:严雨桃 (2017级MPAcc)
以上是关于大数据实战第11期:Kmeans聚类算法做薪酬学历分析的主要内容,如果未能解决你的问题,请参考以下文章