密度聚类算法:利用DBSCAN观察用户的地理分布
Posted 数据启蒙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了密度聚类算法:利用DBSCAN观察用户的地理分布相关的知识,希望对你有一定的参考价值。
提到聚类算法,大家第一时间会想到K-means,今天给大家介绍另外一种聚类算法:DBSCAN。DBSCAN是一种基于密度的聚类算法,不同于K-means(追求同类之间距离最小,不同类之间距离最大),其输出是密度相连的点的最大集合。DBSCAN聚类的结果可以形象地成为“簇”,这也反应其一大优势:可以发现任意形状的聚类集合。DBSCAN在处理空间分布如下图花圃的数据集时,有K-means无法比拟的优势。也由于能有效识别如街道、河流等区隔,DBSCAN可以说是地理位置聚类的利器。
下面我们详细介绍DBSCAN算法的内容:
一、DBSCAN算法的核心概念
邻域:某一对象周边的区域,如果指定半径E,则被称为E邻域。
核心对象:如果某一对象Ε领域内的样本数大于等于MinPoints(最小样本数),则称该对象为核心对象。
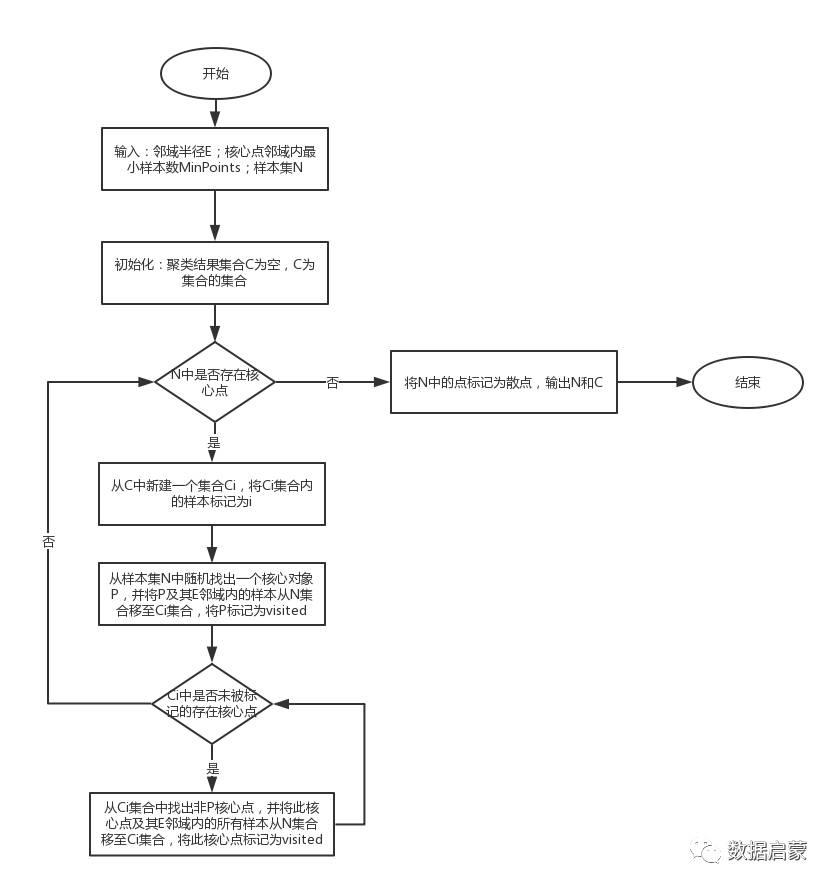
二、DBSCAN的实现过程
输入:邻域半径E;核心点邻域内最小样本数MinPoints;样本集N
初始化:聚类结果集合C为空,C为集合的集合
输出:聚类结果集合C
计算:
1、计算样本集N中的核心点,并标记为核心点。
2、从样本集N中随机找出一个核心对象P,并将P及其E邻域内的样本从N集合移至Ci集合,将P标记为visited。如果N中不存在核心点,则N中的点标记为散点,结束计算。
3、从C中新建一个集合Ci,将Ci集合内的样本标记为i。
4、从Ci集合中找出非P核心点,并将此核心点及其E邻域内的所有样本从N集合移至Ci集合,将此核心点标记为visited。
5、如果Ci中存在未被标记为visited的核心点,则转至第4步。否则转至第2步。
三、DBSCAN聚类的特点
1、DBSCAN的聚类过程就是把核心点串联起来,然后以核心点为中心,E为半径,圈出邻域内的样本。
2、DBSCAN的参数过多(K-means的一个参数已经让我们头疼,何况这里有两个),调参是个头疼问题。
3、如果样本间距离差别过大的话,不适合使用DBSCAN。原因是容易出现散点过多或者分类过少的问题。很难调整两个参数已达到较好的分类效果。
4、DBSCAN可以发现任何形状的样本集合,这种特性在某些场景下使用会有很好的效果,尤其在地理位置的聚类中。
四、利用Python包进行聚类的样例
1、Python包DBSCAN使用的是欧式距离,在进行经纬度的聚利时,最好将经纬度转成平面坐标。坐标转换函数如下:
import utm
def utm_exchange(row):
row['latitude'] = utm.from_latlon(row['user_latitude'], row['user_longitude'])[0]
row['longitude'] = utm.from_latlon(row['user_latitude'], row['user_longitude'])[1]
return row
2、利用平面坐标进行聚类,代码中包含两个参数:邻域半径eps=100米;核心对象邻域内最少样本数min_samples=10
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=100, min_samples=10).fit(position[['latitude', 'longitude']])
position['labels'] = db.labels_3、展示聚类结果,分别展示包含散点的结果和去除散点的结果,代码如下:
import matplotlib.pyplot as plt
labels = position['labels']
unique_labels = set(labels)
colors = plt.cm.Spectral(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = 'k'
class_member_mask = (labels == k)
xy = position[class_member_mask]
if k == -1:
plt.plot(xy['user_latitude'], xy['user_longitude'], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=2)
else:
plt.plot(xy['user_latitude'], xy['user_longitude'], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
研究样本的群体分布
排除散点之后的样本群体分布
以下往期文章:
以上是关于密度聚类算法:利用DBSCAN观察用户的地理分布的主要内容,如果未能解决你的问题,请参考以下文章