携英第四期丨机器学习之密度聚类算法
Posted 西电华俱sharing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了携英第四期丨机器学习之密度聚类算法相关的知识,希望对你有一定的参考价值。
分享时间:2017 年 12 月 13 日 15:00
分享人:郑晨曦、陈强
分享主题:机器学习之密度聚类算法
分享人简介:通信工程学院硕士,电子与通信工程专业,研一,机器学习方向
密度聚类算法
在“无监督学习”中,训练样本的标记信息是未知的,所谓聚类,目标就是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。密度聚类,顾名思义,便是针对样本数据分布的紧密程度来考察数据之间的关联性,进而分类。
密度聚类亦称"基于密度的聚类" (density-based clustering) ,此类算法假设聚类结构能通过样本分布的紧密程度确定.通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。

密度聚类算法核心
主要特点:发现任意形状的聚类;处理噪音;一遍扫描;需要密度参数作为终止条件
输入: e — 半径
MinPts — 给定点在 e 邻域内成为核心对象的最小领域点数
D — 集合
输出: 目标类簇集合
方法: repeat
1) 判断输入点是否为核心对象
2) 找出核心对象的e 邻域中的所有直接密度可达点
Util 所有输入点都判断完毕
repeat
针对所有核心对象的 e 邻域所有直接密度可达点找到最大密度相连对象集合,中间涉及到一些密度可达对象的合并。
Util 所有核心对象的 e 邻域都遍历完毕
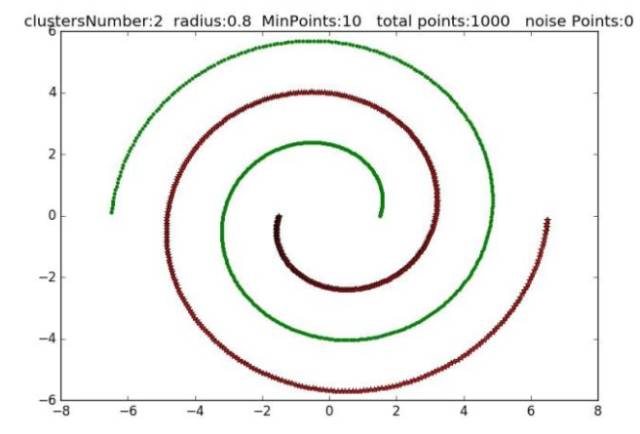
SAR图形变换检测
RBM是有两个层的浅层神经网络,它是组成深度置信网络的基础部件,受限玻尔兹曼机在无监督情况下学习重构数据,在可见层和第一隐藏层之间进行多次正向和反向传递,而无需加大网络的深度。在重构阶段,第一隐藏层的激活值成为反向传递中的输入。这些输入值与同样的权重相乘,每两个相连的节点之间各有一个权重,就像正向传递中输入x的加权运算一样。这些乘积的和再与每个可见层的偏差相加,所得结果就是重构值,亦即原始输入的近似值。

重点来了!
哇!认真的男生最帅!

秉着对学习认真负责的态度,请看图说话,看不清楚的放大了看,还不清楚的私信发廊小妹

咦?上面的文字好像放错位置了(认真脸)?不管了,小妹要去和大神们讨论什么是密度聚类算法了
爱你们
天气越来越冷,你们要替我好好照顾自己呦!
编辑丨发廊小妹
以上是关于携英第四期丨机器学习之密度聚类算法的主要内容,如果未能解决你的问题,请参考以下文章