聚类算法K-means
Posted AI研发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法K-means相关的知识,希望对你有一定的参考价值。

聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为k个聚类,以便使得所获得的聚类满足以下条件:同一聚类中的数据对象相似度较高;不同聚类中的对象相似度较小。相似度可以根据问题的性质进行数学定义。
K-means(也叫K均值)算法就是解决这类问题的经典聚类算法。它的基本思想是以空间中k个点为中心,进行聚类,对最靠近他们的对象归类,通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
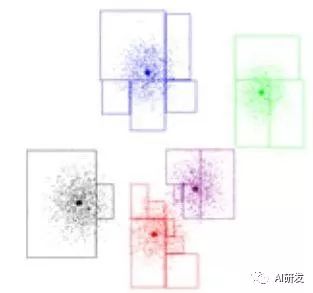
算法的基本步骤为:
1. 从 n个数据对象任意选择k 个对象作为初始聚类中心;并设定最大迭代次数 。
2. 计算每个对象与k个中心点的距离,并根据最小距离对相应对象进行划分,即,把对象划分到与他们最近的中心所代表的类别中去;
3. 对于每一个中心点,遍历他们所包含的对象,计算这些对象所有维度的和的均值,获得新的中心点;
4. 如果聚类中心与上次迭代之前相比,有所改变,或者,算法迭代次数小于给定的最大迭代次数,则继续执行第2 、3两步,否则,程序结束返回聚类结果。

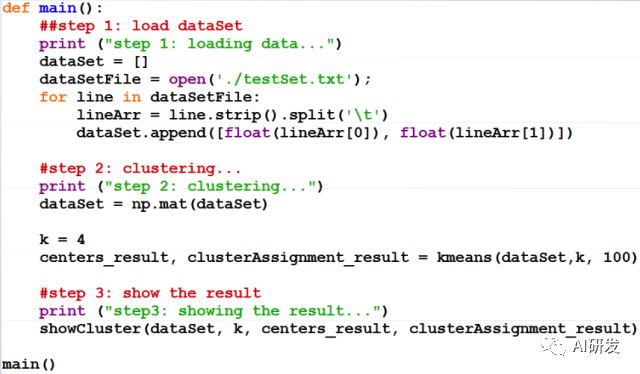
以下是K-means算法的运行过程,编程语言为Python:
运行程序,下面依次是将数据聚为两类、三类、四类的程序结果图。
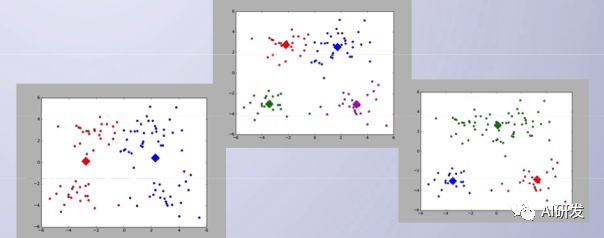
大家也可以通过调整迭代次数,观察生成簇的变化。
更多AI算法请关注下期AI研发!
(以上图片来自网络)
以上是关于聚类算法K-means的主要内容,如果未能解决你的问题,请参考以下文章