聚类算法之Density Peaks
Posted 人工智能算法与技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法之Density Peaks相关的知识,希望对你有一定的参考价值。
聚类算法是无监督学习领域的一类重要方法,今天介绍的Density Peaks方法是2014年发表于Science上的一种聚类方法。
聚类就是将数据分为不同的簇,那么,什么是簇?下图中展示了两个容易区分的簇。
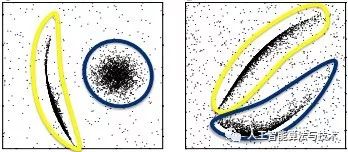
但很多时候,簇不像上图这样规则,例如下图所示的两张图片中,各有两个形状不一的簇。
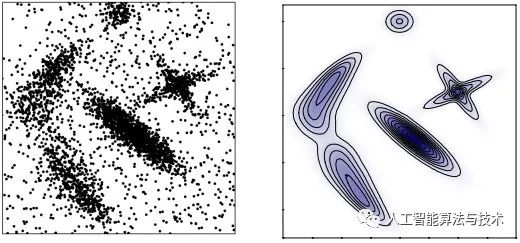
要对上面这样的数据进行聚类,可以采用下面的簇的定义:
簇就是点密度的峰值,即Density Peaks
使用Density Peaks算法进行聚类分为五步:
计算出每个点的局部密度
对每个点,计算它与所有比它密度大的点的距离,并找出其中的最短距离
以点密度为横轴,以第2步计算出来的最短距离为纵轴,绘制出散点图
散点图中的离群点即为聚类中心
将所有点归并到比它密度大的最近邻中,即完成聚类
下面几幅图展示了一个聚类过程示例
第1、2步: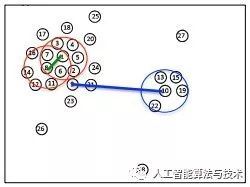
第3步: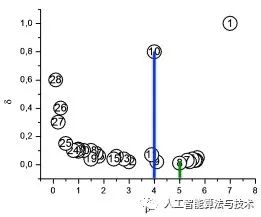
第4步: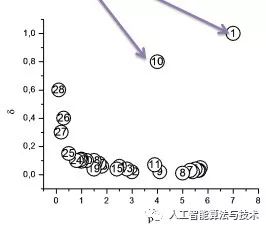
第5步:
可以看到,这种方法非常简单直接,且效果也很好。
上图展示了这种算法的实际聚类效果,结果非常理想。
通常进行聚类的第一选择是Kmeans,因为这一方法最为经典,可用函数库也非常多。但对于不规则簇的数据集,这一算法的效果常常不如人意,这时不妨尝试一下Density Peaks等基于密度的聚类方法,或许有令人惊艳的表现。
以上是关于聚类算法之Density Peaks的主要内容,如果未能解决你的问题,请参考以下文章