记一次百G数据的聚类算法实施过程
Posted 数据与算法联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次百G数据的聚类算法实施过程相关的知识,希望对你有一定的参考价值。
如题,记一次百G数据的聚类算法实施过程,用的技术都不难,spark和kmeans,我想你会认为这没有什么难度,我接到这个任务的时候也认为没有难度,可是一周之后我发现我错了,数据量100G的确不大,但难度在于我需要对 kmeans 的 train过程执行将近3000次,而且需要高效的完成。那么问题就来了,如何保证高效和准确性。(声明小编对Spark也不是说很熟悉)
需求
数据格式为三列,第一列为类别ID,第二列为商品ID,第三列为价格,数据格式如下
数据有很多条,数据量为将近100G,存储在hdfs上,第一列品类ID不唯一,每个品类ID下有多个商品ID,商品ID唯一,价格为浮点型数据
现在要对每个品类下的价格进行聚类,得到1~7个价格level(7level的价格要比6level的价格高,以此类推)
▲▲▲▲▲
第一次尝试很天真,思路也很正常,如下:
1:全量加载数据,形成rdd
2:数据split之后,按key进行groupby
3:针对每个key(也就是类别ID)进行kmeans聚类和预测,并将结果写入hdfs
4:加载每个类别的结果,进行聚合形成最终结果
那么开始写代码。papapa写了一堆,发现groupBy之后的数据格式是CompactBuffer,转化成spark kmeans train所需要的格式之后,代码卡着不会动,不明所以(我估计是格式没有转正确,不是kmeans 所需要的格式,但是如果不是kmeans 需要的格式,应该会报错呀),后来当我把代码打包,提交到集群上运行时,提示我kmeans train所在的函数中没有指定master url,可是我明明指定了,后来才发现是因为,我在rdd操作过程中能够,嵌套了函数,函数中又重新使用了rdd,也就是说rdd 不能嵌套rdd使用,具体可参考 Spark 为什么 不允许 RDD 嵌套-如 RDD[RDD[T]],而我在本地测试时指的都是local,没有进行报错,至此这条路行不通,也就是说不能按这样的思路执行
在该思路的基础上进行改进:
既然rdd不能嵌套rdd使用,何不先得到所有的类别id,然后在全量数据总filter单个类别id进行kmeans操作呢?
该代码,测试,伪代码如下:
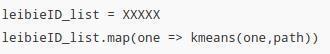
需要注意的是 leibieID_list.map 操作并不是分布式的,而是for 循环,这样3000个类别id运行完,时间可想而知,是极其耗时的,所以这条路也失败了(不是说行不通,是因为耗时)
经过上边的尝试发现不行,那么我想是不是先全量读取数据,然后按照类别ID,将同一个类别ID的数据写到一个文件(或者文件夹下),然后再对之操作
开始写classify by ID 的代码,这里遇到了问题是如何让同一个类别ID的数据写到一个文件中,上网查了一些资料,可以参考之前整理的笔记
Spark多路径输出和二次排序
这里边有实现的办法,但是还有一个问题,对全量数据(100G)进行shuffle的时候,由于数据量特别大,也特别占用资源,往往会出现一些内存上的错误。
这里采用的策略是将全量数据rdd进行random split,然后for循环遍历split之后的rdd,进行saveAsTestFile,保存的目录这样设计

这样的话,就可以避免大量数据 shuffle 耗费资源的问题了,而且也不影响后续数据的使用,同时这一步也会把类别id提取出来,保存在hdfs上,供下一步使用。
经历了上一步的数据准备,开始step 2的开发,第二步的思路:
加载第一步保存的类别id list文件,分成5份,启动5个spark任务进行train,至此,思路是正确的,但却忽略了一个很严正的问题:数据倾斜
由于是随机对类别 id 进行分组操作,那么不能保证没组中每个类别id对应的数据条数的大概一致性,也就是存在某个ID 数据条数只有几十条,而有些ID 数据条数千万条,这种情况下就会导致代码在运行过程中,有些task很快运行完了,有些执行了好久也没完事。
有了第二次的经验,想法就是如何将数据条数差不多的分到同一组里,我采用的方法是进行统计,按照10的X次方形式进行分组,比如说
所以这里采用合并和拆分的策略,比如说将1,2,3合并到一组,4、5、6分别拆成两组,7、8、9合成一组,这样就会保证每组运行的时间是差不多的。(实际情况中,要根据数据的分布进行合理的拆分和合并)
总结
至此,问题算是最终解决了,相比原先的MR版本,时间缩减了将近8个小时,在整个优化的过程中,其实对于经验足够的开发者来说,可能很快就会解决,但对于我们这些新手,可能就要耗费些时间,涨涨记性了,在整个过程中对spark也算是有进一步的了解了。
▲▲▲▲▲
◆ ◆ ◆ ◆ ◆
-完-
以上是关于记一次百G数据的聚类算法实施过程的主要内容,如果未能解决你的问题,请参考以下文章