推荐|数据科学家需要了解的5大聚类算法
Posted 全球人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐|数据科学家需要了解的5大聚类算法相关的知识,希望对你有一定的参考价值。
聚类是一种涉及数据点分组的机器学习技术。给定一个数据点集,则可利用聚类算法将每个数据点分类到一个特定的组中。理论上,同一组数据点具有相似的性质或(和)特征,不同组数据点具有高度不同的性质或(和)特征。聚类属于无监督学习,也是在很多领域中使用的统计数据分析的一种常用技术。本文将介绍常见的5大聚类算法。
K-Means算法
K-Means算法可能是最知名的聚类算法,该算法在代码中很容易理解和实现。
K-Means聚类
1.首先我们选择一些类或组,并随机初始化它们各自的中心点。为了计算所使用类的数量,最好快速查看数据并尝试识别任何一个不同的分组。中心点是和每个数据点矢量长度相同的矢量,上图标记为“X”。
2.每个数据点是通过计算该点与每个组中心的距离进行分类的,然后再将该点分类到和中心最接近的分组中。
3.根据这些分类点,通过计算群组中所有向量的均值重新计算分组中心。
4.重复以上步骤进行数次迭代,或者直到迭代之间的组中心变化不大。选择结果最好的迭代方式。
因为我们只是计算点和组中心之间的距离,计算量很少,所以K-Means算法的速度非常快,具有线性复杂度O(n)。
K-Means算法的缺点是必须选择有多少个组或类,因为该算法的目的是从不同的数据中获得信息。另外,K-means算法从随机的选择聚类中心开始,因此不同的算法运行可能产生不同的聚类结果。其结果缺乏一致性,而其他聚类方法结果更一致。
K-Medians算法是和K-Means算法相关的另一个聚类算法,该算法不用均值重新计算组中心点,而是使用组的中值矢量,因此对异常值不太敏感,但对于数据量较大的数据集运行速度慢很多。
Mean-Shift聚类算法
Mean-Shift聚类算法基于滑动窗口,并尝试找到密集的数据点区域。该算法是一个基于质心的算法,这就意味着该算法的目标是定位每个组(类)的中心点, 通过更新候选中心店作为滑动窗口的平均值,然后在后续处理阶段对这些候选串口进行过滤,消除临近重复点,形成最终的中心点集及其对应的组。
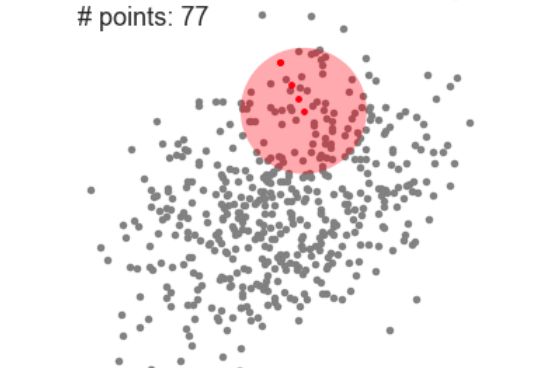
Mean-Shift聚类算法的单个滑动窗口
1.如上图所示的二维空间中的点集合,我们从一个随机选择的C点为中心,以r为半径的圆形华东窗口开始。Mean-Shift算法是一种爬山算法,将内核一步步迭代移动到一个较高密度的区域,直到收敛为止。
2.每次进行迭代的时候,通过移动中心点到窗口内点的平均值,将滑动窗口移动到更高密度的区域。滑动窗口的密度和窗口内部点的数量成正比。
3.我们继续根据平均值移动滑动窗口,直到直到没有方向可以移动使其容纳更多的点。如上图所示,继续移动这个圆,直到窗口内的数量(密度)不再增加为止。
4.我们在步骤1-3中会使用很多个滑动窗口,直到所有的点都位于一个窗口内为止。当多个滑动窗口重叠时,保留包含最多点的窗口,然后根据其所在的窗口,将数据点进行聚类。
下图展示了所有的滑动窗口从头至尾的运动过程,其中,每个黑点表示滑动窗口的质心,每个灰点表示一个数据点。
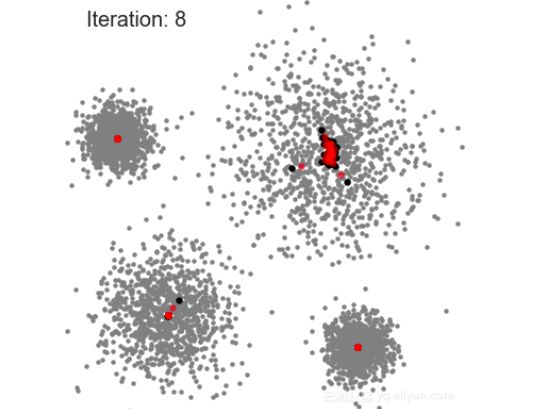
Mean-Shift算法过程
这和K-Mean聚类算法相比,由于Mean-Shift可以自动选择聚类的数量,因此不需要手动选择。这是一个很大的优势,事实上,聚类中心向最大密度点聚合也很理想。该算法的缺点是窗口半径的选择相对来说不重要。
具有噪声的基于密度的聚类方法(DBSCAN)
DBSCAN是一种基于密度的聚类算法,它类似于Mean-Shift算法,但是具有显著的优点。
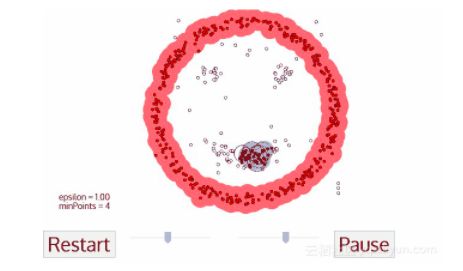
1.DBSCAN从一个未被访问的任意一个数据点开始。该点的领域用距离ε划分(ε距离内所有的点都是领域点)。
2.如果领域内有足够多的点(最大值为minPoints),则聚类过程开始,并且当前的数据点成为新的聚类过程中的第一个点。否则,标记该点味噪声(稍后,这个噪声点可能成为聚类的一部分)。在这两种情况下,该点被标记为“已访问”。
3.对于新的聚类过程中的第一个点来说,其ε距离领域内页成为同一个聚类中的一部分。这个过程使ε领域内所有的点都属于同一个聚类,然后对刚添加到聚类中的所有的新点重复该过程。
4.重复步骤2和3,直到可以确定聚类中所有的点为止,即我们访问并标记了聚类的ε邻域内所有的点。
5.一旦我们完成了当前的聚类,我们对新的未访问到的点进行检索和处理,发现一个更进一步的聚类或噪声。重复这个过程,直到我们标记完成所有的点,每个点都被标记为一个聚类或噪声。
与其它聚类算法相比,DBSCAN算法具有很多优点:首先,该算法不需要固定数量的聚类。其次,它将异常值识别为噪声,而不像Mean-Shift算法,即便是数据点非常不同,也会将其放入聚类中。另外,该算法可以找到任意大小和任意形状的聚类。
DBSCAN算法的主要缺点是,当密度不同时,该算法的性能相对较差。这是因为当密度发生变化时,不同的聚类,用于识别邻近点的距离阈值ε和minPoints的值将会不同。对于高维数据也会有这种缺点,因为距离阈值ε难以估计。
基于高斯混合模型(GMM)的期望最大化(EM)聚类算法
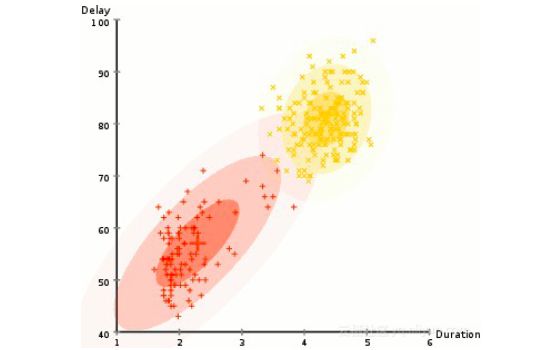
K-Means聚类算法的主要缺点之一就是它使用了聚类中心平均值。通过下图我们可以明白为什么这不是一个最佳方式。左侧的人眼看的非常明显,有两个半径不同的圆形,二者中心相同。由于这些聚类的平均值非常接近,K-Means并不能处理这种情况。同样是使用均值作为聚类中心,右侧的图像也不能使用K-Means聚类算处理。

K-Means聚类算法不能处理的两种情况
高斯混合模型(GMM)算法的灵活性比K-Means算法的灵活性要高。假设GMM算法中的数据呈高斯分布,这样我们就有两个可以描述聚类形状的参数:均值和标准差。以二维分布为例,这就意味着聚类可以有各种类型的椭圆形(因为在x和y方向都有标准差)。因此,每个单独的聚类都分配了一个高斯分布。
为了找到每个聚类的高斯参数(均值和标准差),我们使用称作期望最大化(EM)的一种优化算法。
1.首先选择聚类的数量(和K-Means算法一样),然后对每个聚类的高斯分布参数进行随机初始化。我们也可以通过快速查看数据来为初始化参数提供一个较好的预测。
2.为每个聚类分配这些高斯分布,计算每个数据点属于一个特定聚类的概率。这个点越靠近高斯中心,就越有可能属于该聚类。因为使用高斯分布,我们假设大部分数据更加靠近聚类中心,因此可以比较直观的看出来。
3.基于这些概率,我们计算一组新的高斯分布参数,这样就可以最大化聚类内部数据点的概率。然后我们使用数据点所在位置的加权来计算新的高斯分布参数,其中,权重是数据点属于特定聚类的概率。
4.重复步骤2和3进行迭代,直到收敛位置。重复迭代,其分布并没有太大变化。
GMM算法有两大优势。首先,GMM算法比K-Means算法在聚类协方差上具有更高的灵活性。根据标准差的参数不同,集群是任何形状的椭圆,而不限于圆形。K-Means实际上是GMM算法的一个特例,其中每个聚类的协方差在所有维度上都近似0。其次,由于GMM算法使用概率,每个数据点都可以有多个聚类。因此,如果一个数据点位于两个重叠的聚类中间,我们可以简单地将其定义为类,即有X%的概率属于1类和Y%的概率属于2类。
合成聚类算法-AHC
合成聚类算法分为两大类:自上而下或自下而上。自下而上算法首先将每个数据点视为单个聚类,然后连续的合并(聚合)成对的聚类,直到所有的聚类合并成包含所有数据点的一个单个聚类。因此,自下而上的分层聚类被称为合成聚类算法或AHC。聚类的层用树(树状图)表示,树的根是收集所有样本的唯一聚类,叶子是只有一个样本的聚类。图解如下:
1.首先将每个数据点视为一个单一聚类,即如果数据集中有X个聚类。然后,我们选择一个度量测量两个聚类之间的距离。在本例中,我们使用平均连接,它将两个聚类间的距离定义为第一个数据集中的数据点和第二个聚类中数据点之间的平均距离。
2.每迭代一次,将两个聚类合并成为一个,作为平均连接最小的聚类。根据我们选择的聚类度量,这两个聚类间的距离最小,因此最相似,则应该合并起来。
3.重复步骤2直到遍历到树的根,即包含所有数据点的唯一一个聚类。通过这种方式,我们可以根据最后需要多少聚类,只需选择何时停止组合聚类,即何时停止构建树。
合成聚类算法不需要指定聚类的数量,甚至可以选择哪个数量的聚类最好。另外,该算法对距离度量的选择并不敏感,而对于其他算法来说,距离度量的选择至关重要。
推荐《深度学习系列课》
或点击“”,查看详情
以上是关于推荐|数据科学家需要了解的5大聚类算法的主要内容,如果未能解决你的问题,请参考以下文章