无监督学习Density Peaks聚类算法(局部密度聚类)
Posted Python爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无监督学习Density Peaks聚类算法(局部密度聚类)相关的知识,希望对你有一定的参考价值。

博客:http://blog.csdn.net/zzz_cming
作者好文推荐:
前言:Density Peaks聚类算法和DBSCAN聚类算法有相似的地方,两者都是基于密度的聚类方式。自己是在学习无监督学习过程中,无意间见到介绍这种聚类算法的文章,感觉Density Peaks聚类算法方法很新奇,操作也很简答,于是自己也动手写一下了。
聚类算法主要包括哪些算法?
主要包括:K-means、DBSCAN、Density Peaks聚类(局部密度聚类)、层次聚类、谱聚类。
若按照聚类的方式可划分成三类:第一类是类似于K-means、DBSCAN、Density Peaks聚类(局部密度聚类)的依据密度的聚类方式;
第二种是类似于层次聚类的依据树状结构的聚类方式;
第三种是类似于谱聚类的依据图谱结构的聚类方式。
什么是无监督学习?
无监督学习也是相对于有监督学习来说的,因为现实中遇到的大部分数据都是未标记的样本,要想通过有监督的学习就需要事先人为标注好样本标签,这个成本消耗、过程用时都很巨大,所以无监督学习就是使用无标签的样本找寻数据规律的一种方法
聚类算法就归属于机器学习领域下的无监督学习方法。
无监督学习的目的是什么呢?
可以从庞大的样本集合中选出一些具有代表性的样本子集加以标注,再用于有监督学习
可以从无类别信息情况下,寻找表达样本集具有的特征
分类和聚类的区别是什么呢?
对于分类来说,在给定一个数据集,我们是事先已知这个数据集是有多少个种类的。比如一个班级要进行性别分类,我们就下意识清楚分为“男生”、“女生”两个类;该班又转入一个同学A,“男ta”就被分入“男生”类;
而对于聚类来说,给定一个数据集,我们初始并不知道这个数据集包含多少类,我们需要做的就是将该数据集依照某个“指标”,将相似指标的数据归纳在一起,形成不同的类;
分类是一个后续的过程,已知标签数据,再将测试样本分入同标签数据集中;聚类是不知道标签,将“相似指标”的数据强行“撸”在一起,形成各个类。
一、基于局部密度聚类算法——Density Peaks
1、背景介绍
Density Peaks聚类算法是在2014年 6 月份,由Alex Rodriguez 和 Alessandro Laio 在 Science 上发表了一篇名为《Clustering by fast search and find of density peaks》的文章,这为聚类算法的设计提供了一种新的思路。
虽然这个算法从Science上发表后受到争议——部分学者觉得这篇思想简单、操作方便的聚类算法还达不到能在Science上发表的水平。这可能也是其他学者的恨吧。值得一提的是,发现Density Peaks聚类算法的两位科学家都不是研究数学,也不是研究算法分析的,而是西班牙研究化学的科学家。
2、定义局部密度大小——
Density Peaks聚类算法要是用文字描述是有一些费解的,我尽量用图解释一下:
下图是一个样本空间点的分布图,一共分布着28个点:
事先给定一个邻域半径
数学公式如下右所示,即比较两点距离
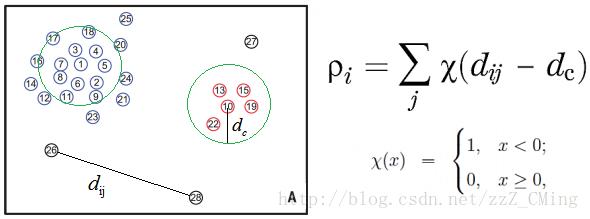
可得的结论:
3、定义聚类中心距离——
Density Peaks聚类算法的巧妙之处:就是在于聚类中心距离
根据局部密度的定义,我们可以计算出上图中每个点的密度,依照密度确定聚类中心距离
1.首先将每个点的密度从大到小排列:
2.先确定密度最大的点的聚类中心距离——i点是密度最大的点,它的聚类中心距离
3.再确定其他点的聚类中心距离——其他点的聚类中心距离是等于在密度大于该点的点集合中,与该点距离最小的的那个距离。例如i、j、k的密度都比n点的密度大,且j点离n点最近,则n点的聚类中心距离等于
4.依次确定所有的聚类中心距离
聚类中心距离
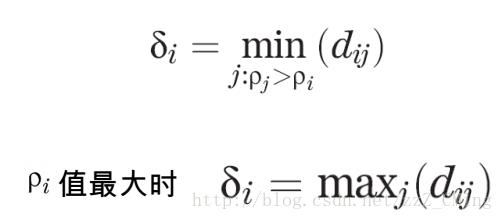
4、决策图确定聚类簇核心、簇边缘
Density Peaks聚类算法就是依据每个点的局部密度大小
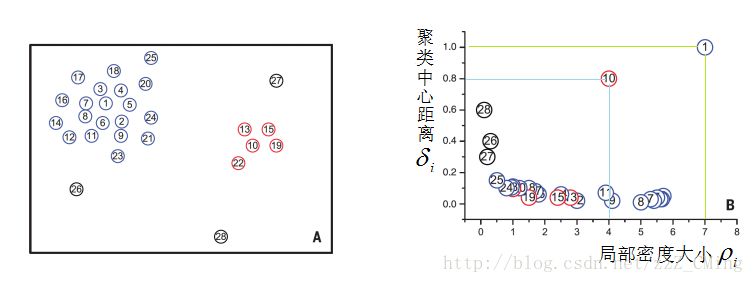
从B图中可以清楚的看出来:
分布在右上角区域的是聚类的核心点:周围密度很大,且没有其他核心点;
分布在靠近
分布在靠近
现实意义就是:北京联合天津、廊坊等地构成帝都经济群,上海联合无锡、常州、苏州构成长江三角洲经济群,广州深圳形成珠三角经济群。北京、上海、广州相当于聚类核心点;天津虽然也很发达,但是由于它离北京很近,所以天津只能是正常点。
5、Density Peaks聚类算法的意义
聚类算法中最困惑的地方就是选定K值等于多少才算合适,Density Peaks聚类算法给出了一种比较好的确定K值的方式:定义
赞赏作者


Python爱好者社区历史文章大合集:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。
以上是关于无监督学习Density Peaks聚类算法(局部密度聚类)的主要内容,如果未能解决你的问题,请参考以下文章