聊聊聚类算法
Posted 机器学习blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊聚类算法相关的知识,希望对你有一定的参考价值。
K-Means聚类算法
提起聚类算法,最常用的算法就是K-Means聚类算法。
K-Means算法中,首先选出k个初始的聚类中心,然后对所有样本点计算这些样本点到k个聚类中心的距离,距离哪个聚类中心最近就将其分为哪个聚类。完成一次迭代之后,需要对每个聚类重新计算该聚类的中心点,接下来对所有样本进行如上操作,并且重新计算所有聚类的中心点,以此类推,如此迭代下去,直至下一次迭代之后聚类中心跟上一次的聚类中心相同,或者下一次迭代之后的聚类中心跟上一次聚类中心相比变动很小,或者达到预设的迭代次数。
针对k-means算法难点之一在于k的选择,一般来讲选择k的标准可以参考误差函数的拐点所对应的k。
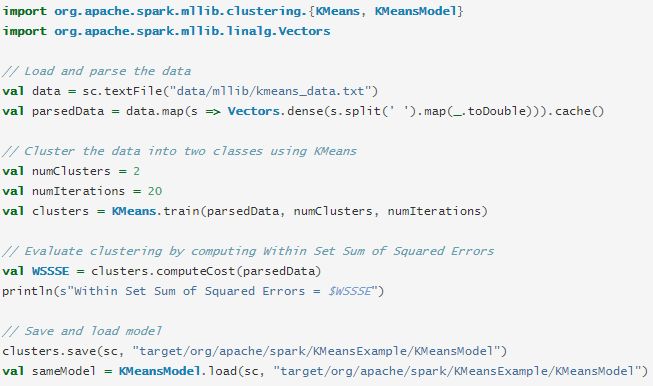
下面是spark中kmeans示例代码,spark中的kmeans需要事先指定需要聚成多少类,即numClusters,还需要指定迭代次数,即numIteration。
谱聚类算法
还有一个比较有名的聚类算法即谱聚类。谱聚类这种算法跟图论紧密关联,其思想在于用边权连接样本点,这里的权值跟两点之间的距离相关,距离越近权值越大,距离越远,权值越小。然后对样本点和边权构成的图进行切分,目标在于使得切图后子图之间的边权和越低越好,同时各个子图内的边权和越好越好。
谱聚类算法步骤如下:
构建相似矩阵,其中最常用的方式是全连接法,而且这种方法中最常用的核函数为高斯径向核RBF,这点跟支持向量机类似,在支持向量机中,最常用的核函数也是径向基核函数
基于第一步中的相似矩阵构建邻接矩阵和度矩阵
构建拉普拉斯矩阵,并对该拉普拉斯矩阵进行标准化
针对第三步中标准化之后的拉普拉斯矩阵,求出最小的若干个(这里的个数需要事先指定)特征值以及各个特征值对应的特征向量
将第四步所得特征向量构成的矩阵按行进行标准化,得到特征矩阵
将第五步中的特征矩阵的所有行作为样本,然后利用事先指定的聚类算法进行聚类,聚类个数需要事先指定,得到最终聚类结果
谱聚类能够比较好的处理稀疏类型的数据,这是因为谱聚类的主要思想在于计算相似度矩阵。另外,谱聚类中包含了降维的过程,这可以使得在高维数据中应用谱聚类时算法复杂度有所降低;但是针对原始的样本维度特别高的情形,如果不能很好地降维,则谱聚类的算法复杂度或聚类效果可能比较难以达到理想的效果。另外,谱聚类的效果跟相似矩阵紧密关联,相似矩阵不同,聚类效果一般也不同。
DBSCAN算法
DBSCAN(Density-Based Spatial Clustering and Application with Noise)这种算法通常用于对带有噪声的空间数据进行聚类。
在DBSCAN中,有三类点,示例如下,其中x是中心点,y是边界点,z是噪声点。
在DBSCAN中有三个比较重要的概念,定义如下
直接密度可达:一个点A是从B直接密度可达即为B是中心点并且A在B的ϵ邻域中。
密度可达:点A跟点B是密度可达的即为如果B通过若干个中心点可以连接到A.。
密度可连:两个点A和B密度可连即为如果A和B跟同一个中心点C密度可达。
DBSCAN算法步骤如下
1 对每个样本点xi,计算该样本点跟其他样本点的距离。针对每个开始点xi,找出该样本点的邻域内的点。如果某个点的邻域内的点大于或等于MinPts,则将该点标记为中心点或已访问。
2 针对每个中心点,如果该点没有标记为属于某个聚类,则新建一个聚类。针对每个中心点,将所有密度可连的点标记为跟该中心点属于同一个聚类。
3 对所有未访问的点递归执行 1 2。
DBSCAN的优势在于不需要知道聚类个数;DBSCAN能够发现比较复杂的聚类形状;它能够标示出噪声。
高斯混合模型
还有一种聚类算法是基于高斯混合分布的,即高斯混合模型(Gaussian Mixture Model, GMM),这种聚类算法针对每个样本点,能够给出该样本点属于每个类的概率,这一点跟k-means,DBSCAN等算法有所不同,不同点在于这种算方法不是将每个样本聚到某个类中。高斯混合模型涉及到各个类的均值和方差,为求解各个类的均值和方差,通常利用期望最大(Expectation-Maximization)算法来求解。
下面是spark中高斯混合模型的示例,其中需要输入聚类个数,如setK,结果中能够输出各个聚类中心,各个聚类的协方差,以及各个聚类的权重。
以上是关于聊聊聚类算法的主要内容,如果未能解决你的问题,请参考以下文章