学习心得018K均值聚类算法
Posted 量化金融科技前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习心得018K均值聚类算法相关的知识,希望对你有一定的参考价值。


K均值聚类算法是假定所有数据对象可分为 k 个簇,每个簇的中心用均值表示 ;通过利用距离度量对象间的相似性和误差平方和准则作为聚类的准则。

首先选定k个初始聚类中心,根据最小距离原则将每个 数据对象分配到某一簇中 ;然后不断迭代计算各个簇的聚类中心并依新的聚类中心调整聚类 情况,直至收敛(准则函数J的 值不再变化)

选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心until 簇不发生变化或达到最大迭代次数

1import numpy as np
2import matplotlib.pyplot as plt
3from sklearn.cluster import KMeans
4
5###加载数据集
6dataMat = []
7fr = open("USPS-4k2_far.txt") # 注意,这个是相对路径,请保证是在当前可执行代码这个目录下执行。
8
9for line in fr.readlines():
10 temp = []
11 curLine = line.strip().split(' ')
12 #fltLine = map(float, curLine) # 映射所有的元素为 float(浮点数)类型
13 temp.append(float(curLine[0]))
14 temp.append(float(curLine[1]))
15 dataMat.append(temp)
16
17train = np.array(dataMat)
18
19###训练模型
20k = 4 # k为簇的数量
21km = KMeans(n_clusters=k) # 初始化
22cls = km.fit(dataMat) # 拟合
23km_pred = km.predict(dataMat) # 预测
24centers = km.cluster_centers_ # 质心
25
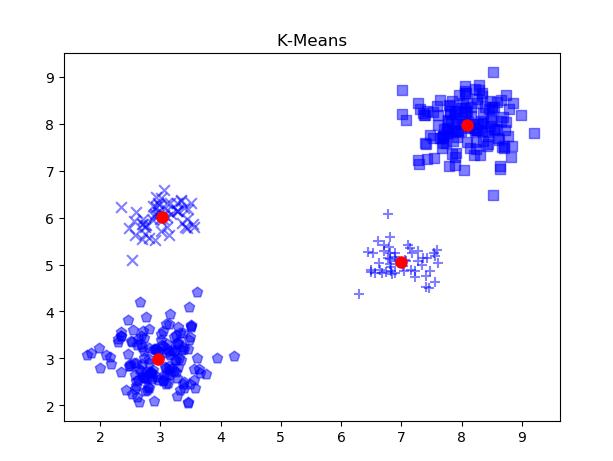
26###可视化结果
27print(km_pred)
28markers = ['p', '+', 'x','s']
29for i in range(k):
30 members = cls.labels_ == i
31 plt.scatter(
32 train[members, 0], train[members, 1], s=60, c='b', marker=markers[i], alpha=0.5)
33 #在图中标注质心的位置
34for i in range(k):
35 plt.plot(centers[i,0], centers[i,1], marker= 'o',color = 'red',markersize=8)
36plt.title("K-Means")
37plt.show()



以上是关于学习心得018K均值聚类算法的主要内容,如果未能解决你的问题,请参考以下文章