技术新势力|常用聚类算法应用场景和技巧总结
Posted 亚信安全FacetoFace
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术新势力|常用聚类算法应用场景和技巧总结相关的知识,希望对你有一定的参考价值。
聚类问题是机器学习里一个相对简单的问题,它的使用的场景却非常多,下面介绍聚类算法的应用场景和一些常用的技巧。废话不说,直入正题。
一
什么叫聚类?
聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。是无监督的分类方式。
用个大白话说就是你要把一堆的数据给他聚成一团团的,所谓物以类聚,人以群分,聚类就是要把一些臭味相投的给它聚在一起。
二
聚类的应用场景
下面介绍我工作中会遇到的一些实际聚类场景:
寻找优质客户
运营商客户价值分群,比如:高价值客户,一般客户,易流失客户等。
推荐系统
物以类聚,人以群分,相似度越高的用户和物品他们的距离会越近,比如说一堆商品很密集的聚集在一起,我们就说这些商品很相似。推荐的时候可以考虑同一个聚簇里的商品。
我最近做的一个IPTV推荐模型,协同过滤的实现思路是这样的:
1. 先用矩阵分解得到隐因子模型,这相当于对数据进行降维处理。
2. 然后对产品和用户进行聚类。
3. 根据聚类结果进行推荐。
推荐系统内容比较多,这里就不展开介绍了。
孤立点检测
即离群点判别,对我们来说最主要的就是黑客攻击,比如正常的访问日志和异常的攻击日志是有区别的,我们提取特征,进行聚类分类,寻找孤立点,然后抽取孤立点的特征进行分析来发现黑客的入侵,以此来保障网站的安全。
图像压缩
可以用K-Means算法进行图像的压缩。
除了这些我们工作中会用到的,还有社区发现,生物进化树,金融欺诈等场景,有兴趣的同学可以线下研究。
三
什么样的数据可以做聚类?
到底什么样的数据我们可以拿来做聚类?在聚类之前我们需要做一个聚类趋势的评估。
聚类要求数据不能是均匀分布。
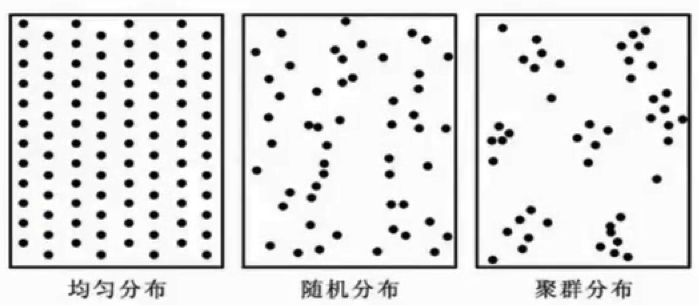
分析
左一:大家看上面的三张图,第一张图样本点都是均匀分布的,肉眼观察,直觉就是数据无论如何是不可能聚成一团团的。但是如果我们把一堆的样本数据直接扔给我们的机器算法比如K-MEANS 或者 DBSCAN,指定聚类的簇数K,我们会发现机器照样会按照我们的要求将数据分成K类,但是这样的分类是没有意义的,因为这些数值的性质就决定它是不适合做聚类的。
左二:是一个随机均匀分布的样本,如果拿来做聚类,虽然说有些地方的点比较密集,可是分类数会非常多,是没有意义的。
左三: 是一个非随机结构,可以看到图中大概有6,7个簇,簇内的点密集的聚在一起,这样的聚类是比较有意义的。
对于简单的两维,三维的样本我们直接画图用肉眼就能看出样本的分布情况,但是实际情况样本的维度会比较多,那么如何用程序评估样本是否适合做聚类呢?
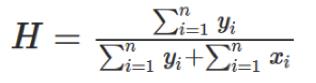
霍普金斯统计量(Hopkins Statistic)
(1 Xi)均匀地从D的空间中抽到n个点P1……Pn。也就是说,D空间中的每个点都以相同的概率包含在这个样本中。对于每个点Pi(1≤i≤n),我们找出Pi在D中的最近邻,并令xi为pi与它在D中的最近邻之间的距离,即xi=min{dist(pi,v)}v属于D
(2 yi)均匀地从D的*中抽到n个点q1……qn。对于每个点qi(1≤i≤n),我们找出qi在D-{qi}中的最近邻,并令yi为qi与它在D-{qi}中的最近邻之间的距离,即yi=min{dist(qi,v)}v属于D,v不等于qi。
这个统计量会告诉我们数据集D有多大可能遵守数据空间的均匀分布和随机分布。通过这个统计量可以验证我们的数据集是否适合做聚类。H接近于0时,是适合做聚类的,如果H接近1/2,表示样本在空间里是随机均匀分布的,不适合做聚类。这个看值的范围,可以判定聚类的趋势。
相信很多小伙伴一看到这些数学公式就晕菜了,这个Xi,和Yi定义看起来没啥差别啊,仔细看一下,Xi是样本空间的点,而Yi就是样本空间中实际的样本点。
简单画个图,图中红色的就是Xi,在样本空间中,但不是D中的样本点,黑色圆点就是Yi了。
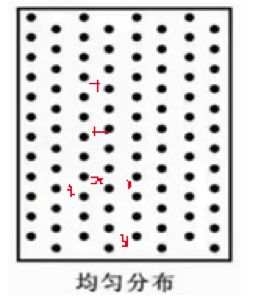
那么想象一下,如果D空间中样本点都是均匀分布的,这样Xi中的点在D中的最近邻连加和Yi中的点在D中的最近邻距离连加应该数值差别不大,H就会非常接近1/2。
下面假设D空间的样本点是可以聚簇的,因为我们选择Xi是均匀的选取,所以有一些Xi会落在簇里,当然肯定有很多Xi会落在簇外,大家都知道在簇团里空间的距离是相对近的,肯定会有大量的Xi它离簇团里最近的点的距离都不会太小,所以Xi值比较大,因为Yi是在簇团里取的,所以Yi值相当于Xi会小很多,所以H值会比较少,接近于0。
该值在区间[0, 1]之间,[0.01, 0.3]表示数据结构regularly spaced,该值为0.5时数据是均匀分布的,[0.7, 0.99]表示聚类趋势很强。
所以大家在做聚类之前,先做一个霍普金斯统计量计算,来说明你用聚类建模是否合理,专家看到这样的分析报告就会觉得你非常的专业。
四
常用聚类算法
算法的介绍随便一搜就能找到很多现成的资料。下面找了几个比较常用的算法,结合我的经验做一个简单的介绍。 算法具体原理自行查阅相关资料。
K 均值聚类(K-Means)
使用 K 均值聚类,是基与距离的聚类方法,我们希望将我们的数据点聚类为 K 组。K 更大时,创造的分组就更小,就有更多粒度;K 更小时,则分组就更大,粒度更少。
K-means算法的优缺点
l 有效率,而且不容易受初始值选择的影响
l 不能处理非球形的簇
l 不能处理不同尺寸,不同密度的簇
l 离群值可能有较大干扰(因此要先剔除)
K-Means算法的可视化演示可在这里查看:https://www.naftaliharris.com/blog/visualizing-k-means-clustering/,可以像读漫画一样理解。平面上的每个数据点都根据离自己最近的重心加了颜色。你可以看到这些重心(更大一点的蓝点、红点和绿点)一开始是随机的,然后很快进行了调整,得到了它们各自的聚类。
上面这个演示大家可以玩玩,一个老外做的,可以选取数据类型,动态的看到聚类过程的变化。
基于密度的聚类方法:DBSCAN
l DBSCAN = Density-Based Spatial Clustering of Applications with Noise n
l 本算法将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类
比如下面这些任意形状分布的数据集,用DBSCAN就能达到很好的分类效果。DNSCAN算法的可视化演示可在这里查看:
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
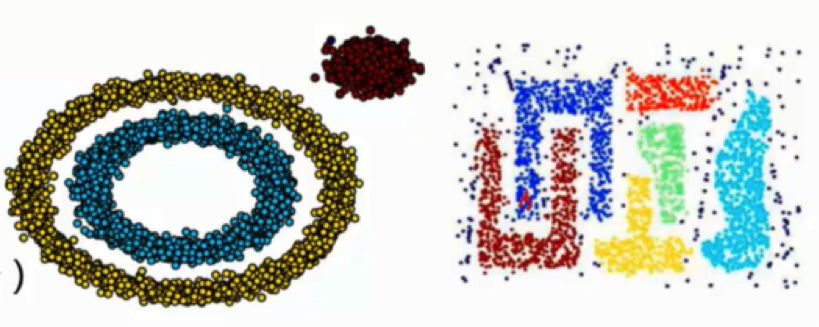
优点
(1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
(2)与K-MEANS比较起来,不需要输入要划分的聚类个数;两个参数就够了
(3)聚类簇的形状没有偏倚;
(4)可以在需要时输入过滤噪声的参数。
(5)擅长找到离群点(检测任务)
缺点
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)高维数据有些困难(可以做降维)
(3)参数难以选择(参数对结果的影响非常大)
(4)Sklearm中效率很慢(采用数据消减策略)
层次聚类(HAC)
「让我们把 100 万个选项变成 7 个选项。或者 5 个。或者 20 个?呃,我们可以过会儿决定。」
层次聚类类似于常规的聚类,只是你的目标是构建一个聚类的层次。如果你最终的聚类数量不确定,那这种方法会非常有用。比如说,假设要给京东或者淘宝市场上的项目分组。在主页上,你只需要少量大组方便导航,但随着你的分类越来越特定,你需要的粒度水平也越来越大,即区别更加明显的项聚类。
在算法的输出方面,除了聚类分配,你也需要构建一个很好的树结构,以帮助你了解这些聚类之间的层次结构。然后你可以从这个树中选择你希望得到的聚类数量。
更多有关层次聚类的详细信息,可参阅这个视频:https://www.youtube.com/watch?v=OcoE7JlbXvY
除了上述三个主要的算法,还有一些高级的聚类算法。比如模糊聚类。
模糊聚类
基于概率模型进行聚类,一个样本点既可以属于A类,也可以属于B类,如果说K-means属于硬聚类,那么模糊聚类就是一种软聚类, 样本点对聚簇的归属 ,用概率来描述,比如属于A的概率:70%,属于B的概率:30%。
具体的数据原理,有兴趣的同学自己找资料看看。
最大期望(EM)算法
其实深入的研究一下EM算法,我们会发现不管是K-Means还是模糊聚类他们的数学背景都是来源于EM算法这个更大更抽象的算法。
五
常用聚类算法实际应用对比
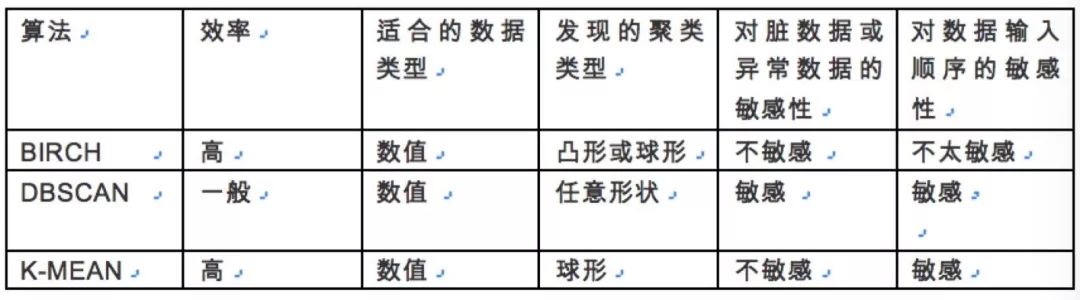
下面介绍几个经常会用到的算法,K-MEANS, DBSCAN,BIRCH
从效果上说DBSCAN是最好的,准确率最高,如果没有特殊的要求首选肯定是DBSCAN,但是上面也提到了它的一个明显的缺点,当数据量增大时,它要求较大的内存,消耗很大。
BIRCH是基于半径做聚类,它是一种增量的方式,所以速度非常快,远远超过了DBSCAN,适合大数据量场景,但是他的算法准确率是不如DBSCAN的,而且它对脏数据和异常数据是不敏感的。
K-MEAN是最简单的,而且效率也高,但是准确度相对差些,但是在我们打算开始一个聚类任务时,可以先用K-MEANS试跑看看效果,它的效率高,很快能看到聚类的效果。
六
要做归一化么?
通常情况下我们在聚类之前都会对特征做归一化处理,是为了消除数值之间的差异性。做完归一化之后相当于每个特征权重都是一样的。可是实际情况可能并不是这样的,特征的权重可能在本质上就是有差异的,所以做完归一化的效果不见得会更好。
这就需要我们结合实际情况做个分析,我们可以做个权重加强进行分析评估。
七
如何确定聚类簇数K?
l 经验判断:例如样本点数目为n,则取k=sqrt(n/2)
l 肘方法:以离差平方和为基础
参考韩家炜《数据挖掘概念和技术》P317页
l PSF或PST2这类统计方法:也是围绕离差平方和展开的方法。
如果想得到好的聚类效果可以:先通过观察层次聚类时PSF和PST2的取值决定聚类簇数,然后再用K-Means聚类。
l 信息论方法与信息准则
l 交叉验证
其中经验判断,不太靠谱,如果你实在没什么方法入手,也可以拿它来试一把。我一般的做法就是肉眼观察结合上述的科学方法比如肘方法来确定一个K值的大概范围,结合数据的业务特征,还有一些数据分析的经验来决定分类数,比如做一个电信客户价值分类,大概根据业务和数据特征我觉得分3类比较合适,然后预先我就令K=3 ,然后把数据扔到算法模型里去跑看一下效果,如果效果还OK,可能就会再根据一些聚类硬性效果评价指标来做一个K值调整,上述的方法大家可以都试试,有的方法可能得出的K值明显就是不对的,所以在确定最佳聚类数目的时候要多尝试几种方法,并没有固定的套路。
八
如何评估聚类的质量?
通俗的说就是看看我们的聚类有没有美感,比较理想的聚类是样本明显的聚成几团,同一类间很密集很紧凑,不同类之间也分的很清晰,离的比较远,中间也没有什么杂音,噪点。这样的聚类就很美。一般不够美的聚类可能有下面几个原因:
1. 聚簇数选的不对
2. 算法选择不是很好,比如你用基于距离的方法可能不是很好,换成基于密度的会好些。
这种情况就需要聚类评估,它用来描述你聚类的质量。
其实聚类并没有统一的评价指标,因为不同聚类算法的目标函数相差很大,有些是基于距离的,有的基于密度。下面介绍一些我工作用常用的。
因为没有标签,所以一般通过评估类的分离情况来决定聚类质量。类内越紧密,类间距离越小则质量越高。我用到过的有sklearn中的Silhouette Coefficient和Calinski-Harabaz Index,sklearn里面解释的很清楚,直接把数据和聚类结果作为输入就可以了。
九
高维度如何聚簇?
当样本的特征维度比较高时,需要先做降维,再做聚类。
降维就是在保留数据结构和有用性的同时对数据进行压缩。常用的降维方法有:PCA(主成分),深度学习的稀疏自编码(Autoencoder)。
稀疏自编码是一个压缩再解压的过程,属于无监督学习范畴,可以把特征直接当作标签作为输入,输出也是本身,我们利用回归层上一层的那个全连接层,也就是那个被压缩的特征,作为特征的输出,这个特征的维度是被压缩过的,但是可以代表之前的高维特征分布。
我个人喜欢用深度学习的Autoencoder,降维的效果比较好。降维之后聚类的速度会明显加快,准确率损失不大。
十
大数据量时,如何做聚类?
l CLARA:一种基于随机选择的聚类算法,思想就是用实际数据的抽样来代替整个数据,用于对大数据集进行快速聚类。大数据处理的三种基本思路是,关键字:抽样,精度,性能。
l Mini Batch KMeans:是一种能尽量保持聚类准确性下,能大幅度降低计算时间的聚类模型。
l BIRCH:它是一种增量的方式,速度也很快,但是精度会有损失。
但是实际我在工作中遇到这种大数据量问题时,我通常尝试是先对数据进行分类,然后再做聚类。总之各种方法都试试看看哪个速度更快,效果更好。
十
一
超级大群如何处理?
80%的数据分布在1%的空间内,而剩下的20%的数据分布在99%的空间内。聚类时,分布在1%空间内的大部分数据会被聚为一类,剩下的聚为一类。当不断增加K值时,模型一般是对99%空间内的数据不断进行细分,因为这些数据之间的空间距离比较大。
而对分布在1%空间内的数据则很难进一步细分,或者即使细分了,也只是剥离出了外侧少量数据。
解决办法:那么为了解决这个问题,一种可行的方法是是对特征取LOG,减轻长尾问题。经过这两种方法处理后,都能较好的对玩家进行分类。下图是上图中的数据点取LOG后得到的分布图。
缺点:取LOG的方法的缺点在于,会使数据变得不直观,不好理解。
十
二
可视化的聚类分析报告
我常用的就是雷达图和概率密度图,这两个图可以很直观的看出每个类簇的数据分布特征。具体使用方法网上的资料很多。
上图是业务背景是基于IPTV半年用户订购数据做的一个基于订购的客户价值分析模型,我选取了4个维度的用户特征。分类之后画了一个雷达图辅助分析。
L(Length):表示客户关系长度。
R(Recency):表示客户最近一次购买的时间有多远。
F(Frequency):表示客户在最近一段时间内购买的次数。
M (Monetary):表示客户在最近一段时间内购买的金额。
图中可以清晰的看出每个类簇在RFML这四个维度上的数值分布,方便我们分析和解析定义类簇。
作者简介:
数据创新部 李晓燕
从事创新产品的设计和开发
以上是关于技术新势力|常用聚类算法应用场景和技巧总结的主要内容,如果未能解决你的问题,请参考以下文章