Sklearn入门之k-means聚类算法
Posted 爬虫俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn入门之k-means聚类算法相关的知识,希望对你有一定的参考价值。
本文编辑:胡 婧
技术总编:张学人
有问题,不要怕!访问
http://www.wuhanstring.com/uploads/5_aboutus/爬虫俱乐部-用户问题登记表.docx (复制到浏览器中)下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
爬虫俱乐部隆重推出数据定制及处理业务,您有任何网页数据获取及处理方面的难题,请发邮件至我们邮箱statatraining@163.com,届时会有俱乐部高级会员为您排忧解难!
关于sklearn库之前已经介绍了一种回归算法(多元线性回归),一种判别算法(线性判别分析),这两种都属于有监督学习的范畴,今天我们来介绍一种经典的聚类算法——k-means。相对于回归和判别分析,聚类算法不会根据已知类别的样本调整分类器的参数,属于无监督学习范畴。
经典的k-means算法主要有如下步骤:
第一步:从数据集中随机选取K个样本作为初始聚类中心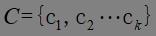 。
。
第二步:针对数据集中的每个样本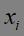 ,计算它到K个聚类中心的距离并将其分到距离最小的聚类中心对应的类中。
,计算它到K个聚类中心的距离并将其分到距离最小的聚类中心对应的类中。
第三步:针对每个类别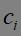 ,重新计算它的聚类中心
,重新计算它的聚类中心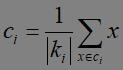 。即属于该类所有样本的质心。
。即属于该类所有样本的质心。
第四步:重复第二步和第三步,当聚类中心移动小于给定的误差时,迭代停止。
下面通过对红楼梦的120个章节进行聚类(红楼梦分章节的txt文件已上传到腾讯云),来给大家介绍如何通过Sklearn库进行k-means聚类。本文的主要思路是:
(1)使用jieba模块对各个章节进行分词。
(2)通过sklearn. feature_extraction. tex模块将文本向量化。
(3)通过sklearn. cluster. KMeans模块使用k-means算法对向量进行聚类。
由于jieba库是python的第三方库,首次使用需要在联网的状态下在命令行输入 pip install jieba ,安装完成后会提示安装成功。下面我们分别读入120个章节,并进行jieba分词。程序如下:
import jieba
result=[] #定义一个空的列表,保存章节内容
for i in range(1,121): #各章节的txt命名形式为:1.txt,2.txt...120.txt
filename="E:\python程序\k-means\book\"+str(i)+".txt" #txt文件所在位置,小编的是在e盘下面,可更改
with open(filename,"r",encoding='utf-8') as fp: #将txt文件读入成str格式
words=fp.read()
seg_list=list(jieba.cut(words, cut_all=False)) #运用结巴精确模式分词,并将分析结果保存成一个list
seg_cut=" ".join(seg_list) #对分开的词以空格分隔,并合并成str形式
result.append(seg_cut) #将各章节分词后的结果保存在名为result的列表中最终分词结果保存在了result中:
一般的文本分析会将自身并无明确的意义的词,如:语气助词、副词、介词、连接词等作为停用词,但是我们聚类是想讨论的是红楼梦前80回和后40回的写作风格是否有显著差别。所以这里我们把红楼梦中的人名地名和标点符号作为停用词,试图减少情节对分类效果的影响。停用词我们保存在名为stop_words的txt文件中,并将其上传到腾讯云。下面读入停用词表:
with open("E:\python程序\k-means\stop_words.txt","r",encoding='utf-8') as f: #读入停用词表
stop_word = f.read()
stop_word = stop_word.splitlines() #将停用词表保存成列表的形式接下来,通过词袋模型和TF-IDF模型对文本进行进一步处理,使其转换成矩阵的形式。这我们简单介绍一下这两种模型:
词袋模型:在词集的基础上如果一个词在文档中出现不止一次,统计其出现的频数。
TF-IDF模型:用以评估某一字词对于一个文件集或一个语料库的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
对于这两种模型的计算,可以运用sklearn库中两个类CountVectorizer和TfidfTransformer,其具体用法如下:
CountVectorizer:可以统计列表中各个字符串的词频。通过stop_words参数可以加入停用词表。max_df可以设置为范围在[0.0 1.0]的float型数值,在文档中出现频率高于max_df的词不作为关键词。min_df类似于max_df,在文档中出现频率低于min_df的词不作为关键词。我们这里将stop_words设置为前面构造的停用词表stop_word,将max_df设置为0.8,min_df设置为0.2。
TfidfTransformer:将词频矩阵转化为TF-IDF权重矩阵。
处理程序为:
from sklearn.feature_extraction.text import CountVectorizer #文本文档集合转换为令牌计数矩阵
from sklearn.feature_extraction.text import TfidfTransformer #将计数矩阵转换为标准化的tf或tf-idf表示
vectorizer=CountVectorizer(stop_words=stop_word,min_df=0.2,max_df=0.8)#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频,去除停用词
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(result))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-id存储在名为weight的矩阵中最终可以看到,得到的关键词有782个,如下图所示:
得到的TF-IDF权重矩阵为:
以上就将文本转化成矩阵的形式,现在就可以使用k-means算法对文本进行聚类了。k-means算法的实现是基于sklearn库中的cluster.KMeans模块。其中简要介绍一下KMeans模块的几个参数:
n_clusters:K值,即类的数量。这里我们设置为2。
max_iter: 最大的迭代次数,到达最大的迭代次数让算法可以及时退出循环。这里我们设置成500。
init:初始化质心的选择方式。我们这里选择k-means++方法,确定一个质心后,选择离这个质心最远的观测值作为下一个质心,加快收敛速度。
random_state:确定初始化质心生成的随机数,保证程序的可重复性。这里设置成10010。
聚类程序如下:
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=2,init='k-means++',max_iter = 500,random_state=10010) # 构造聚类器
label_pred = estimator.fit_predict(weight)这样聚类结果就存储在label_pred。为了方便观察类别分布,我们以散点图的形式来展示章节的类别分布,程序如下:
import matplotlib.pyplot as plt
x=list(range(1,121))
plt.scatter(x,label_pred,s=10)
plt.show()最终结果如下:
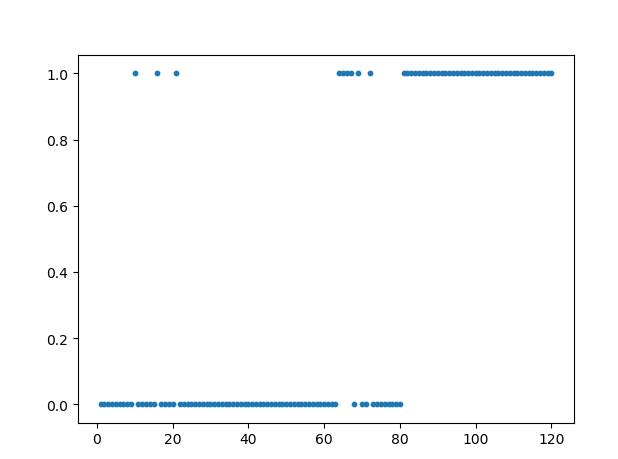
可以直观的看到80章是一个分隔点,除去几个异常的点,前80章分为一类,后40章分为一类,这也和我们知道的后40回为后人所续是一致的。
以上就介绍了对红楼梦进行k-means聚类的全过程,对于文本的处理过程和K-mean参数的选取仍有很多的不严谨的地方,但作为一个简单的例子我们就不去深究,结果也仅供参考。如果各位读者在日常使用中遇到此类问题,都可通过留言或者发邮件与我们联系,我们会竭诚为您解答。
注:本文需要的红楼梦的txt,停用词表以及原程序都已经上传到了腾讯云,链接为
https://stata-club-1257787903.cos.ap-chengdu.myqcloud.com/k-means.zip
爬虫俱乐部是您身边的科研助手,能够为您在数据处理、实证研究中提供帮助。承蒙近四万粉丝的支持与厚爱,我们在腾讯课堂推出了网络视频课程,专注于数据整理、网络爬虫、循环命令编制和结果输出…李老师及团队精彩地讲解,深入浅出,注重案例与实战,让您更加快速高效地掌握Stata技巧及数据处理的精髓,而且可以无限次重复观看,在原有课程基础上已上传了全新的内容!百分百好评,简单易学,一个月让您从入门到精通。绝对物超所值!观看学习网址:
https://ke.qq.com/course/286526?tuin=1b60b462,
敬请关注!
对爬虫俱乐部的推文累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫!
往期推文推荐
关于我们
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
以上是关于Sklearn入门之k-means聚类算法的主要内容,如果未能解决你的问题,请参考以下文章