聚类算法大解析
Posted 数据皮皮侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法大解析相关的知识,希望对你有一定的参考价值。
聚类算法
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。
KMeans
KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的数据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
簇中所有数据的均值 通常被称为这个簇的“质心”(centroids)。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
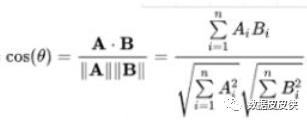
对于一个簇来说,所有样本点到质心的距离之和越小,我们就认为这个簇中的样本越相似,簇内差异就越小。而距离的衡量方法有多种,令表示簇中的一个样本点,表示该簇中的质心,n表示每个样本点中的特征数目,i表示组成点的每个特征,则该样本点到质心的距离可以由以下距离来度量:
欧几里得距离:
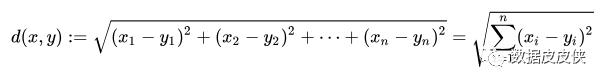
余弦距离:
sklearn.cluster.KMeans
1class sklearn.cluster.KMeans (n_clusters=8, init=’k-means++’,
2 n_init=10, max_iter=300, tol=0.0001,
3precompute_distances=’auto’, verbose=0, random_state=None,
4copy_x=True, n_jobs=None, algorithm=’auto’)参数 n_clusters
n_clusters是KMeans中的k,表示着我们告诉模型我们要分几类。这是KMeans当中唯一必填的参数,默认为8 类,但通常我们的聚类结果会是一个小于8的结果。通常,在开始聚类之前,我们并不知道n_clusters究竟是多少,因此我们要对它进行探索。
第一步
当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这个数据集的数据分布,以此来为我们聚类时输入的n_clusters做一个参考。
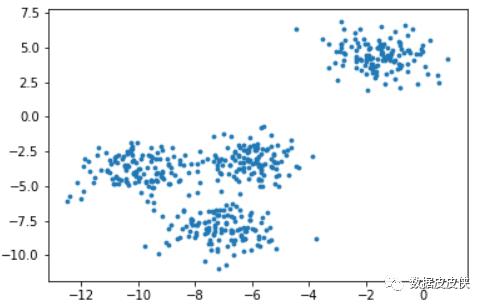
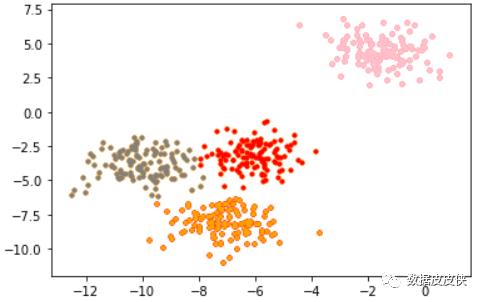
该数据集是sklearn.dataset里的make_blobs数据,根据观察可以发现其实数据大致上可以划分为4个簇。
第二步
基于这个分布,我们来使用Kmeans进行聚类。
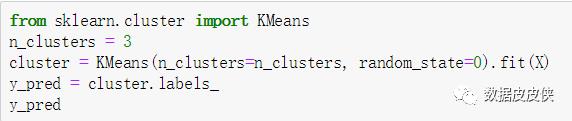
再对被划分到不同簇的数据进行可视化,观察结果。
第三步
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚类,是完全依赖于评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。其中轮廓系数是最常用的聚类算法的评价指标。
1) 样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离
2) 样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中得所有点之间的平均距离 根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。
单个样本的轮廓系数计算为:
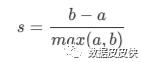
第四步
根据绘制的轮廓系数分布图和聚类后的数据分布图来选择我们的最佳的n_clusters。
由此可以看出,综合来说n_clusters选取2或4时拥有较好的表现。
总结
本次对KMeans及其评价指标的介绍就到此结束了,但还有更多适用于不同情况的聚类算法值得我们去探索及学习,例如DBSCAN与OPTICS等。基于不同的距离计算及簇划分方法得来的结果是不一样的,本次主要在于介绍KMeans这一较为常用的聚类算法的实际使用、可视化及调参方法,希望读者能有所收获。
以上是关于聚类算法大解析的主要内容,如果未能解决你的问题,请参考以下文章