从分类预测到聚类算法,有何不同?
Posted 智能小熊猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从分类预测到聚类算法,有何不同?相关的知识,希望对你有一定的参考价值。
文|智能小熊猫
No.1
聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有标记样本构成的训练不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
分组的原则是组内的距离最小化,组间的距离最大化。
No.2
K-means算法
在最小化误差函数的基础上将数据划分为预判定的K类,采用距离作为相似性的评级指标;
即:两个对象的距离越近,其相似度越大。
算法实现:
1
从N个样本数据中随机选取K个对象作为初始的聚类质心;
2
分别计算每个样本到各个聚类中心的距离、将对象分配到距离最近的聚类中;
3
所有对象分配完成之后、重新计算K个聚类的质心;
4
与前一次的K个类聚中心比较,如果发生变化,重复过程2,否则转过程5;
5
当质心不再发生变化时,停止聚类过程,并输出聚类结果。
No.3
Hierarchical Clustering(层次聚类)算法
按照某种方法进行层次分类,直到满足某种条件为止,方法分为两类:
凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大簇,直到所有队形都在一个簇中,或者某个终结条件被满足。
分类:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者某个终结条件被满足。
算法实现:
1
将每一个对象归为一类,共得到N类,每类仅包含一个对象,类与类之间的距离就是他们所包含的对象之间的距离;
2
找到最接近的两个类合并成一类,于是总的类数少了一个;
3
重新计算新的类与所有旧类之间的距离;
4
重复第2步和第3步,直到最后合并成一个类为止。
No.4
GMM(高斯混合模型)算法
聚类算法大多数通过相似度来判断,而相似度又大多采用欧式距离长短作为衡量依据。
GMM采用新的判断依据:概率,通过属于某一类的概率大小来判断最终的归属类别。
基本思想:任意形状的概率分布都可以用多个高斯分布去近似,也就是说由多个高斯分布组成。
这些高斯分布线性加成在一起就组成了GMM的概率密度函数。
No.5
以K-means算法为例,计划将样本数据分成3个聚类,求每个聚类的质心和对应的样本数量!
Id |
R |
F |
M |
1 |
27 |
6 |
232.61 |
2 |
3 |
5 |
1507.11 |
3 |
4 |
16 |
817.62 |
4 |
3 |
11 |
232.81 |
5 |
14 |
7 |
1913.05 |
6 |
19 |
6 |
220.07 |
7 |
5 |
2 |
615.83 |
... |
... |
... |
... |
算法中采用的数据集见上面表格,样本容量为940,样本的特征为3。
import pandas as pddata = pd.read_excel("./consumption_data.xls",index_col="Id")data_zs = 1.0*(data-data.mean())/data.std()
导入数据,对数据进行标准化处理。
from sklearn.cluster import KMeansmodel = KMeans(n_clusters=3, n_jobs=4, max_iter=500)model.fit(data_zs)
导入聚类模块,设置参数:聚类数为3,最多迭代次数为500,训练模型。
r1 = pd.Series(model.labels_).value_counts()r2 = pd.DataFrame(model.cluster_centers_)r = pd.concat([r2, r1],axis=1)r.columns = list(data.columns)+["类别数目"]r
输出质心和聚类标签,统计每个聚类下的样本数量,整合数据!
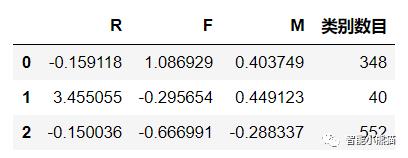
从数据结果中可以看出:
显示分成了三个聚类;
第一个聚类为“0”,R特征质心为-0.159118,F特征的质心为1.086929,M特征的质心为0.403749,样本集中348个样本属于这个聚类;
第一个聚类为“1”,R特征质心为3.455055,F特征的质心为-0.295654,M特征的质心为0.449123,样本集中40个样本属于这个聚类;
第一个聚类为“2”,R特征质心为-0.150036,F特征的质心为-0.666991,M特征的质心为-0.288337,样本集中552个样本属于这个聚类;
说明:质心数据与样本集中的数据相差较大的原因是原始数据经过了标准化处理。
更多往期文章

智能小熊猫
ID : Wisdom_Little_Panda
您的关注,我的动力!

PS:智能小熊猫连续更文的第12篇,今天也是隔离期满的日子!
自由真好...
随手点个在看吧
以上是关于从分类预测到聚类算法,有何不同?的主要内容,如果未能解决你的问题,请参考以下文章