层次聚类算法优化
Posted 易学统计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了层次聚类算法优化相关的知识,希望对你有一定的参考价值。
题记:本文是个人的读书笔记,仅用于学习交流使用。
01
解决什么问题
02
最优聚类个数
代码和前面的一样,首先确定簇的数目,应该将method的值改为Ward.D2:
numWard <- NbClust(df, diss = NULL, distance = "euclidean",min.nc = 2, max.nc = 6, method = "ward.D2", index = "all")
上完跑完的结果显示,看花线下面,有二个指标认为2个分类最好,18个指标认为3个分类最好,二个指标认为6个分类是最好的。
这次的结果也没什么变化,根据少数服从多数原则,簇的数目是3。看一下Hubert指数图,最优解也是3个簇。
下面是Hubert指数图。
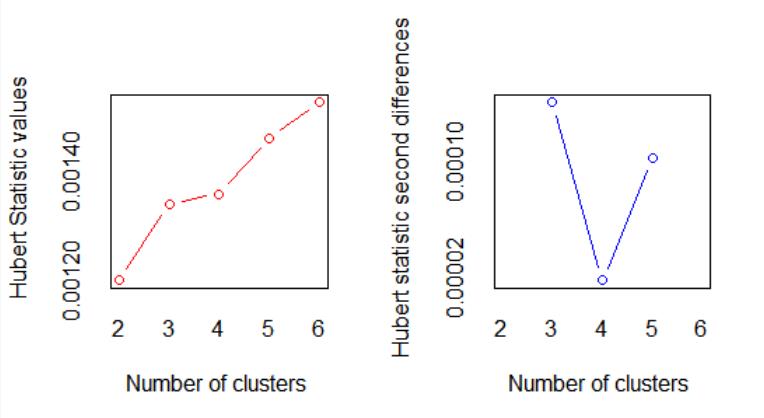
可以看到,左图在3个簇的地方有个拐点,右图在3个簇的时候达到峰值。下面的Dindex图也提供了同样的信息。
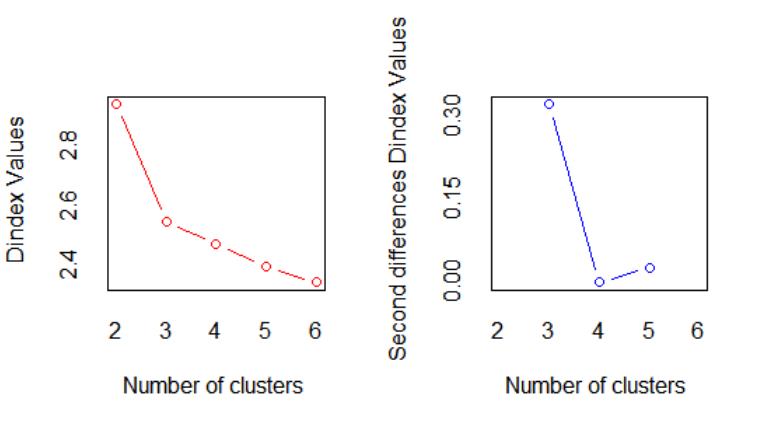
由此我们得到最优的聚类个数为3个。
03
构建模型
选择3个簇进行聚类,现在计算距离矩阵,并建立层次聚类模型。如下所示:
### 选取分类个数为3搭建模型dis <- dist(df, method = "euclidean")hcWard <- hclust(dis, method = "ward.D2")par(mfrow =c (1, 1))plot(hcWard, labels = FALSE, main = "Ward's-Linkage")
层次聚类可视化的通用方式是画出树状图,可以用plot函数实现。
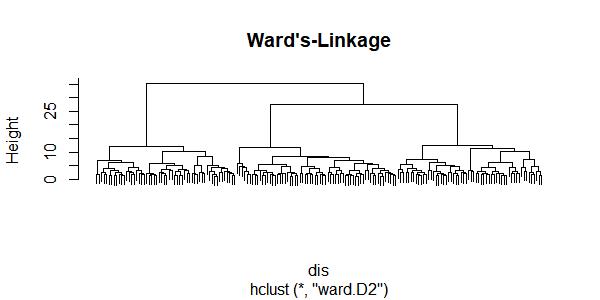
图中显示的3个簇区别十分明显,每个簇中观测的数量大致相同。计算每个簇的大小,并与品种等级标号进行比较:
ward3 <- cutree(hcWard, 3)table(ward3, wine$Class)
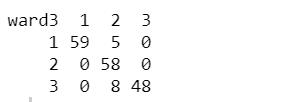
这个表中,行是簇标号,列是品种等级标号。聚类结果匹配了93%的品种等级。与最大距离法相比,这种方法和品种等级的分类更加匹配。
04
算法对比
aggregate(wine[, -1], list(comp3), mean)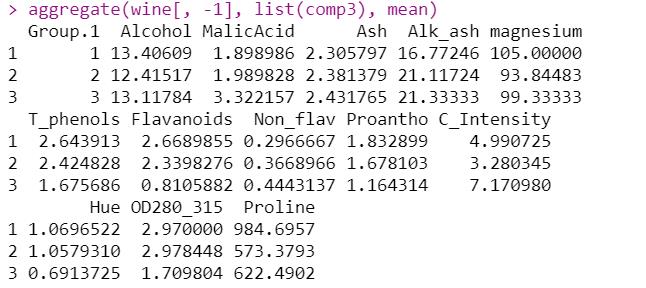
aggregate(wine[, -1], list(ward3), mean)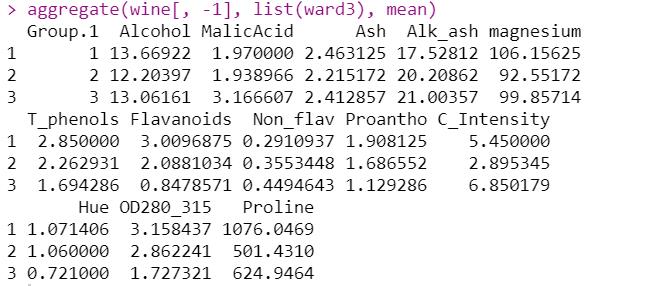
假设我们对两种聚类方法中的Proline值很感兴趣,可以生成一个带有两幅箱线图的统计图进行比较。首先要准备制图区域,使两幅图并列排列。使用par()函数即可:
par(mfrow =c (1, 2))
参考文献
薛毅等.统计建模与R软件.清华大学出版社
Cory Leismester.精通机器学习.基于R.人民邮电出版社
作介绍:医疗大数据统计分析师,擅长R语言。
欢迎各位在后台留言,恳请斧正!
更多阅读
长按二维码
易学统计
以上是关于层次聚类算法优化的主要内容,如果未能解决你的问题,请参考以下文章