sklearn聚类算法用于图片压缩与图片颜色直方图分类
Posted 启示AI科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn聚类算法用于图片压缩与图片颜色直方图分类相关的知识,希望对你有一定的参考价值。
上期文章:机器学习之SKlearn(scikit-learn)的K-means聚类算法
我们分享了sklearn的基本知识与基本的聚类算法,这里主要是机器学习的算法思想,前期文章我们也分享过人工智能的深度学习,二者有如何区别,可以先参考如下几个实例来看看机器学习是如何操作的
不同K值下的聚类算法
首先我们随机创建一些二维数据作为训练集,观察在不同的k值下聚类算法的区别
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans# X为样本特征,Y为样本簇类别, 共1000个样本,
# 每个样本4个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1],[2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2,centers=[[-1,-1], [0,0], [1,1], [2,2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],random_state =9)
y_pred = KMeans(n_clusters=2, random_state=9)
y_pred = y_pred.fit_predict(X)
plt.figure()
plt.subplot(1,2,1)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.subplot(1,2,2)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()利用KMeans函数新建一个聚类算法,这里设置为2分类
y_pred = KMeans(n_clusters=2, random_state=9)然后进行分类
y_pred = y_pred.fit_predict(X)
新建对象后,常用的方法包括fit、predict、cluster_centers_和labels。fit(X)函数对数据X进行聚类, 使用predict方法进行新数据类别的预测, 使用cluster_centers_获取聚类中心, 使用labels_获取训练数据所属的类别, inertia_获取每个点到聚类中心的距离和代码截图
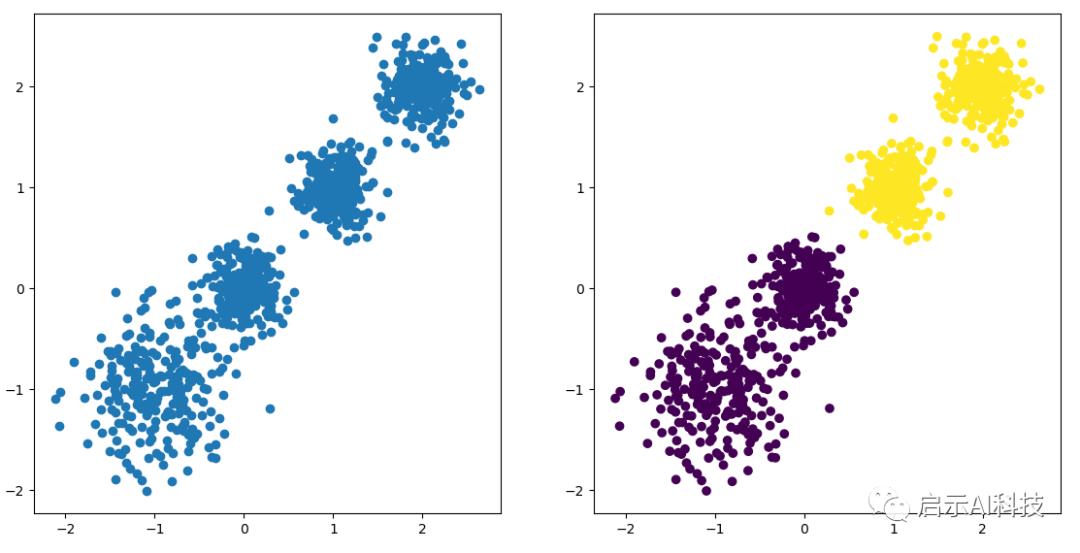
KMeans 2 分类
当然3分类,4分类我们只需要修改一下KMeans函数中的n_clusters参数即可
y_pred = KMeans(n_clusters=3, random_state=9)
y_pred = KMeans(n_clusters=4, random_state=9)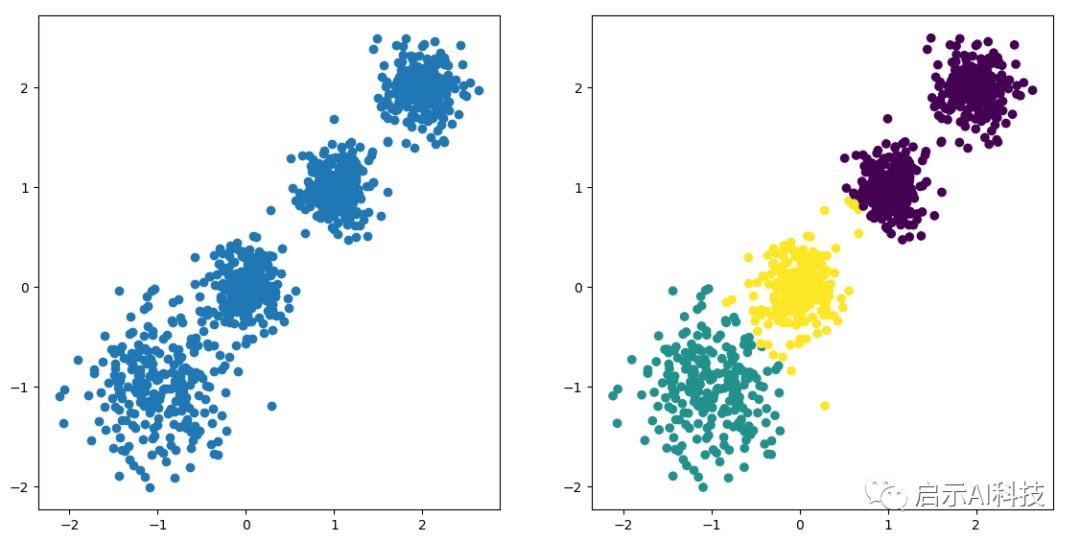
KMeans 3 分类
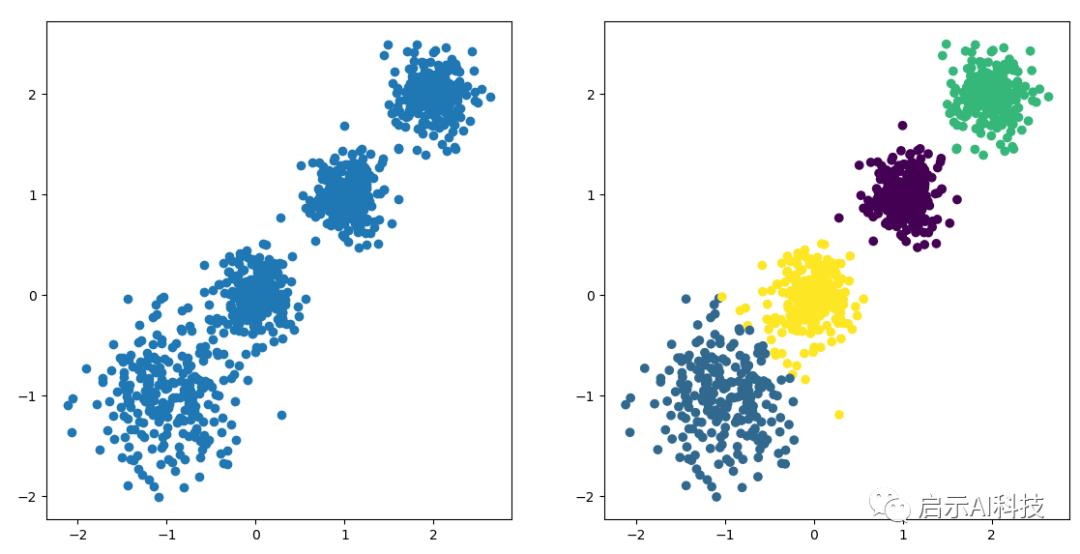
KMeans 4 分类
图片颜色直方图的聚类
用于相似图片搜索引擎的Python OpenCV图像直方图
谷歌百度以图搜图如何实现?教你打造属于自己的相似图片搜索引擎
我们以前的文章分享过颜色直方图的概念,既然图片有不同的像素组成的,我们可以获取图片直方图的数据,进行sklearn的聚类来查看图片那个色素使用的最多。
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import cv2
import numpy as np
def RGBhistogram(clt):
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
(hist, _) = np.histogram(clt.labels_, bins=numLabels) hist = hist.astype("float")
hist /= hist.sum() return hist
def plot_bar(hist, centroids):
bar = np.zeros((50, 300, 3), dtype="uint8")
startX = 0
for (percent, color) in zip(hist, centroids):
print(str(percent)[0:4])
endX = startX + (percent * 300)
cv2.rectangle(bar, (int(startX), 0), (int(endX), 50),
color.astype("uint8").tolist(), -1)
cv2.putText(bar, str(percent)[0:4], (int(startX), 10),
cv2.FONT_HERSHEY_SCRIPT_COMPLEX, 0.5, (100, 200, 200), 1)
startX = endX return bar首先我们建立2个函数,一个主要是计算直方图数据,另一个主要来显示图片色素的条形图
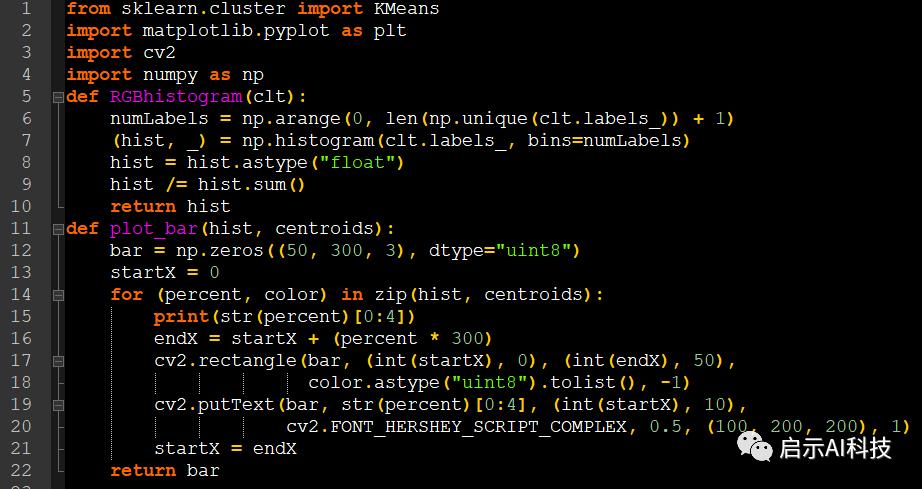
代码截图
image = cv2.imread("12.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img = image.reshape((image.shape[0] * image.shape[1], 3))
clt = KMeans(n_clusters=3)
clt.fit(img)
hist = RGBhistogram(clt)
bar = plot_bar(hist, clt.cluster_centers_)
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.imshow(bar)
plt.show()首先读取一张图片,进行图片的resize,这里主要是减少数据量
使用sklearn的kmeans算法进行颜色色素的聚类,这里选择3聚类,那么我们主要显示数据量最多的前三个色素
clt = KMeans(n_clusters=3)
clt.fit(img) 新建对象后,常用的方法包括fit、predict、cluster_centers_和labels。fit(X)函数对数据X进行聚类, 使用predict方法进行新数据类别的预测, 使用cluster_centers_获取聚类中心, 使用labels_获取训练数据所属的类别, inertia_获取每个点到聚类中心的距离和sklearn的kmeans算法聚类完成后,把聚类好的数据进行直方图的数据统计,然后进行数据的整理,这里我们整理前3个主要的色素,利用每个色素的百分比进行条状图的画图,并显示色素的百分比例
hist = RGBhistogram(clt)
bar = plot_bar(hist, clt.cluster_centers_)最后显示图片以及统计好的色素条状图
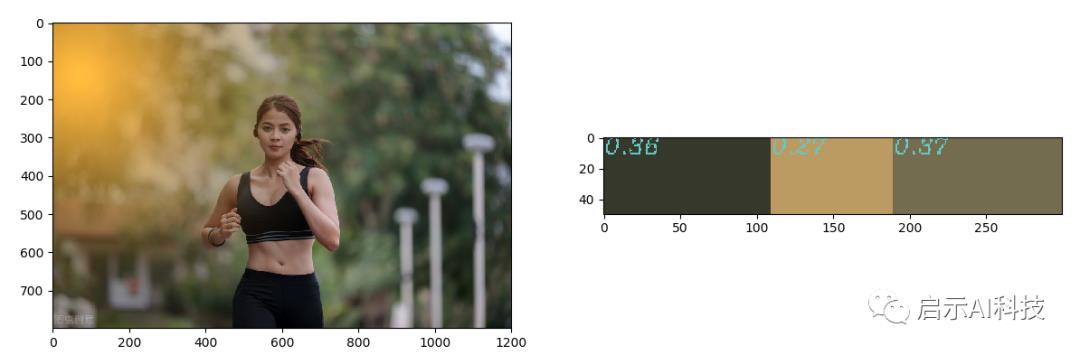
图片颜色聚类
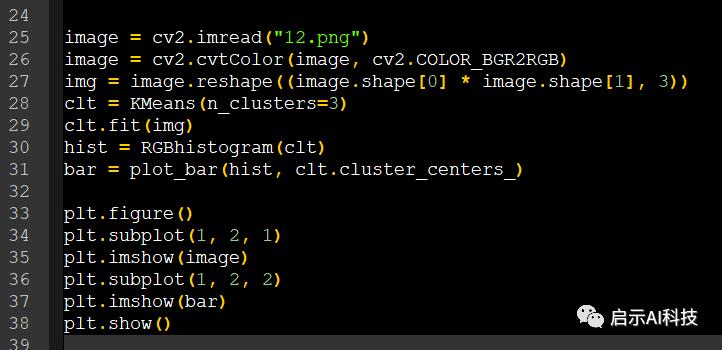
代码截图
sklearn聚类算法用于图片压缩
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.utils import shuffle
import cv2# 加载图片
# 加载图像并转换成二维数字阵列
image = cv2.imread('13.png')
image = np.array(image, dtype=np.float64) / 255w, h, d = original_shape = tuple(image.shape)
assert d == 3
image_array = np.reshape(image, (w * h, d))
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=64, random_state=0).fit(image_array_sample)
labels = kmeans.predict(image_array)这里我们首先加载图片,并把图片转换到二维数字阵列
image_array_sample = shuffle(image_array, random_state=0)[:1000]如上便是把图片数据进行无序打乱,这样会避免人为的一些干扰,尽可能的还原数据的真实性
然后使用
kmeans = KMeans(n_clusters=64, random_state=0)函数进行数据的聚类操作的新建类,这里
新建对象后,常用的方法包括fit、predict、cluster_centers_和labels。fit(X)函数对数据X进行聚类,使用predict方法进行新数据类别的预测,使用cluster_centers_获取聚类中心,使用labels_获取训练数据所属的类别,inertia_获取每个点到聚类中心的距离和
进行fit图片聚类后,进行图片的标签预测
kmeans.predict(image_array)
新建对象后,常用的方法包括fit、predict、cluster_centers_和labels。
fit(X)函数对数据X进行聚类,
使用predict方法进行新数据类别的预测,
使用cluster_centers_获取聚类中心,
使用labels_获取训练数据所属的类别,
inertia_获取每个点到聚类中心的距离和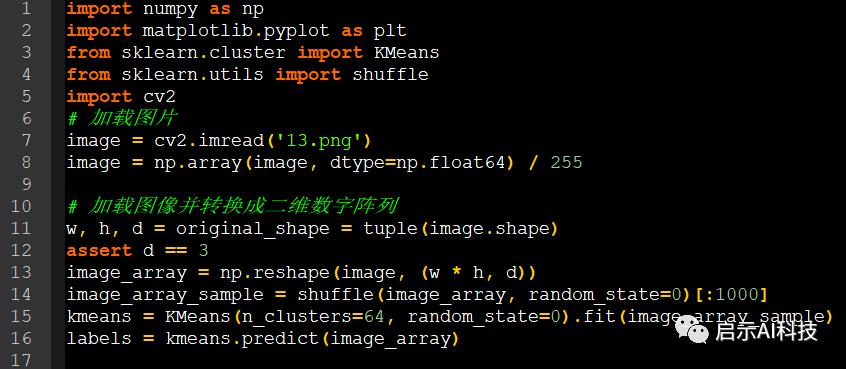
代码截图
神经网络预测完成后,便可以进行图片的压缩了,我们新建一个压缩图片函数,传递的参数为kmeans.cluster_centers_, labels, w, h,然后重新组成图片数据
#重组压缩图片
def recreate_image(codebook, labels, w, h): d = codebook.shape[1]
image = np.zeros((w, h, d)) label_idx = 0
for i in range(w):
for j in range(h):
image[i][j] = codebook[labels[label_idx]] label_idx += 1
return image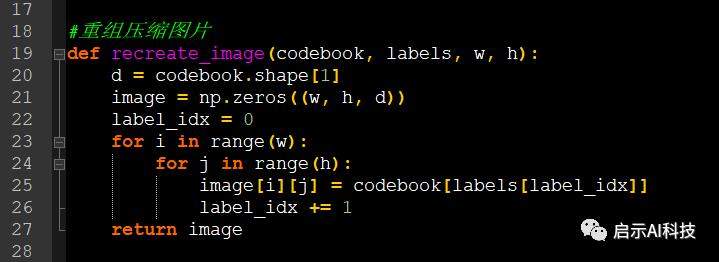
代码截图
最后显示照片
# 与原始图像一起显示所有结果
plt.figure()
plt.subplot(1, 2, 1)
plt.axis('off')
plt.title('Original image ')
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.axis('off')
plt.title('Quantized (64 colors, K-Means)')
plt.imshow(recreate_image(kmeans.cluster_centers_, labels, w, h))
plt.show()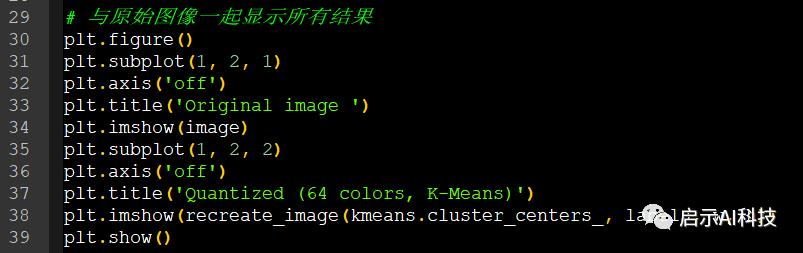
代码截图
这里我们新建一个画布,包括1行2列,1行1列显示原始数据,1行2列显示压缩后的图片,从压缩图片可以看出,很多地方的颜色都已经被弱化,但是保留了绝大部分的数据,也能够很好的反映图片,这在神经网络进行大量数据提取计算时,是很有必要的,避免大量的计算
图片压缩
通过以上几个聚类的分享,我们已经了解到了聚类的基本用法,想了解更多算法的小伙伴们可以参考官方教程。
以上主要是机器学习的算法思想,深度学习当然也可以来实现类似的功能,比如CNN 卷积神经网络,机器学习的算法都是现成的,一些前辈已经完成的算法,我们可以直接使用,具体深度学习,我们需要搭建自己的神经网络,进行不同神经网络的训练学习
深度学习与机器学习区别
机器学习与深度学习
机器学习:实现人工智能的方法
机器学习直接来源于早期的人工智能领域,传统的算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。从学习方法上来分,机器学习算法可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习。
深度学习:实现机器学习的技术
深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
无论机器学习,还是深度学习都是帮助我们实现未来的人工智能的强有力工具,当然随着算法的不断完善,相信后期还会有更完善的学习算法。
以上是关于sklearn聚类算法用于图片压缩与图片颜色直方图分类的主要内容,如果未能解决你的问题,请参考以下文章