基于聚类算法的家庭成员关系识别研究
Posted 5G工业物联
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于聚类算法的家庭成员关系识别研究相关的知识,希望对你有一定的参考价值。
相关链接:
2、
3、
DOI:10.3969/j.issn.1006-6403.2020.10.019
引用格式:袁鸢, 李成奇, 付文豪. 基于聚类算法的家庭成员关系识别研究[J]. 广东通信技术, 2020, 40(10): 76-79.
基于聚类算法的家庭成员关系识别研究
袁鸢、李成奇、付文豪
【摘要】随着电信运营商进入全业务运营时代,移动公司在宽带和家庭业务这两块业务存在后发弱点,被友商采用融合业务积极渗透移动客户,市场竞争日趋激烈。为适应新形势下市场竞争的要求,中国移动重点发展和推广家庭业务,增加客户对移动业务的粘性,降低个人客户被蚕食的风险。为提升家庭业务运营质量,客户家庭成员的准确识别显得尤为重要。本文通过利用K-means聚类算法挖掘同居住小区的客户交往圈关系,建立家庭成员识别模型,为家庭业务的发展提供数据支撑。
【关键词】聚类算法;K-means;成员识别
1 引言
随着各电信运营商进入全业务运营时代,中国移动在宽带及家庭业务存在后发弱点,竞争对手利用其全业务优势和移动公司在此领域业务的弱点,实施差异化的竞争策略,积极渗透移动业务,市场竞争日趋激烈。
2 现状分析
为适应新形势下市场竞争的要求,立足于移动公司在移动业务的先发优势和规模优势,通过业务融合重点发展和推广家庭业务,增加客户对移动业务的粘性,这样不仅能降低个人客户被蚕食的风险,更能在传统语音业务和数据业务的基础上取得进一步收入发展。然而,当前移动公司在发展宽带和家庭业务市场上存在如下几个问题。
(1)客户居住地信息和小区人数规模的不确定,不利于宽带资源的布放,容易造成资源覆盖的紧张或浪费。
(2)无法依靠人工或者简单的统计来实现客户家庭位置定位。
(3)缺失小区成员信息,对家庭客户的定位产生阻力。
(4)人工成本高,数据质量低,社区通讯录存在更新滞后、信息不完整等诸多问题。
(5)用户通信行为特征挖掘不够深入,没有结合通话时段与通话位置信息,无法通过用户交往圈准确分析判断其交往的用户角色。
(6)每个用户通信交往圈数据量大,没有有效的方法从用户的的通信交往圈中,区分哪些是该用户的核心交往圈用户,或仅靠传统的软件处理效率低下,而且效果极差,无法满足运营需要。
综上所述
,如何将聚类分析算法应用于电信行业家庭用户识别业务,通过使用机器学习聚类分析算法进行家庭成员分群,精确对社区用户进行群体分割,按家庭属性划分出簇群,以评估移动公司在家庭业务的市场分额和资源分配,并解决实际生产过程中的相关问题,已成为家庭市场营销的重要抓手。
3 家庭成员识别研究
电信行业家庭用户最明显的特征就是通过相互联系来形成交往圈,这一点跟复杂网络很类似。复杂网络一般是指节点数量多且节点间交互关系复杂的网络。社区结构是复杂网络的拓扑特点之一,整个网络由若干社区构成,社区内部节点的交互频繁,社区间节点的交互较弱。因此,当进行对一个复杂网络的社区发现时,通常情况下是可以使用聚类算法的。聚类算法源于图的划分问题,图划分的目标就是找到一种切割方法,使得切割最少的边就可以将结点分割为不相交的集合。
3.1 模型设计
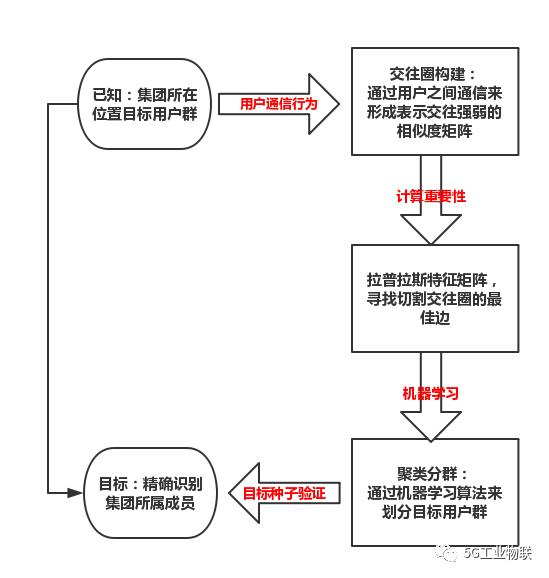
本模型的设计原理思想来源于聚类算法,其实现过程归纳为以下3个主要步骤。
(1)通过用户通信行为来构建表示出电信行业用户集的相似度矩阵W;
(2)通过计算相似度矩阵或拉普拉斯矩阵的前k个特征值与特征向量,构建特征向量空间;
(3)利用K-means聚类算法对特征向量空间中的特征向量进行聚类。如图1所示为设计原理图
[1]
。
3.2 算法的实现和应用

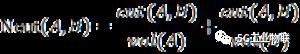
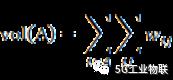
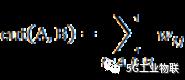

谱聚类算法是一种配对聚类方法,算法仅与数据点的数目有关,而与维数无关,因而可以避免由于特征向量的过高维数所造成的奇异性问题。谱聚类通过特征分解,可以获得聚类判据在放松了的连续域中的全局最优解。与其它聚类算法相比,谱聚类具有识别未知分布数据集聚类方面的能力,非常适合于许多实际问题,而且执行起来比较容易。
聚类数目不需要人工确定,而是自动迭代循环,找寻CH指标最佳时候的K值。
考虑到自动迭代的过程,计算成本过高,不可能从最小值2迭代到全部用户数,这是业务上需要高效快速的生产要求不符合。故模型针对此问题做了如下处理:提前找寻社区家庭户数,一般的社区都是有固定房屋总数且发布到互联网上,且数据是比较精确的。通过此就得获得最后社区划分的聚类数的大致范围,即K
min
与K
max
用于自动迭代聚类模型数
[3]
,此处理方式一定最大程度上减少模型自动迭代次数。比如社区房屋总数X户,考虑说不可能入住率百分百,通过互联网房地产中介数据了解到社区的入住率y%,加之移动用户市场覆盖率z%左右,故自动迭代范围的计算方式:
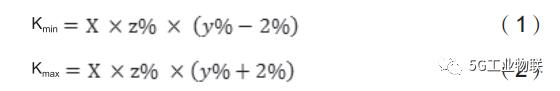
算法中由相似度矩阵得到拉普拉斯矩阵后,接下来要确定所需特征向量的数目,它与最终的聚类数目相等。虽然该数目可以由人工确定,但是准确地给出对聚类效率和最终的聚类质量有直接影响的数目值是个非常困难的问题。因此,如何自动确定聚类数目成为谱聚类需要解决的关键问题之一。
基于数据集样本几何结构的指标根据数据集本身和聚类结果的统计特征对聚类结果进行评估,并根据聚类结果的优劣选取最佳聚类数,这些指标有Calinski-Harabasz(CH)指标,Davies-Bouldin(DB)指标Weightedinter-intra(Wint)指标,Krzanowski-Lai(KL)指标,Hartigan(Hart)指标,In-Group Proportion(IGP)指标等。本文主要采用的是Calinski-Harabasz(CH)指标。
CH指标通过类内离差矩阵描述紧密度,类间离差矩阵描述分离度,指标定义为:
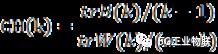
其中,n表示聚类的数目,k表示当前的类,trB(k)表示类间离差矩阵的迹,trW(k)表示类内离差矩阵的迹。可以得出CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
3.3 家庭成员识别模型设计
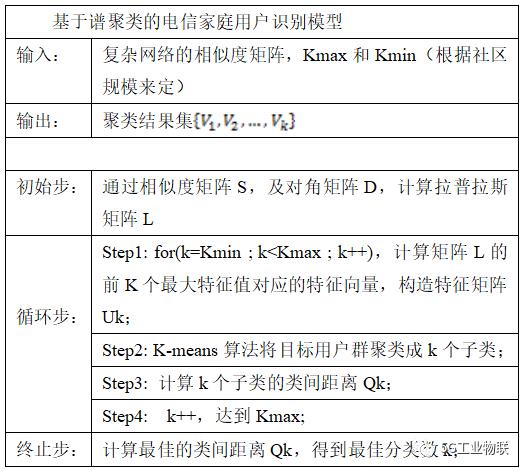
模型基于谱聚类算法,小区成员数据来自于客户居住地识别模型结果,整体实验方法主要是通过对社区目标用户群及其通信情况数据的处理,构建目标用户交往圈,使用机器学习聚类分析算法,以成员通信紧密度为维度,以群内成员联系紧密,群间成员联系稀疏为原则,选取最佳分群数目,对目标用户群进行分群操作,分割出社区中的家庭簇群
[4]
。
表1 基于谱聚类的电信家庭用户识别模型
4 效果验证
4.1 验证环境和工具
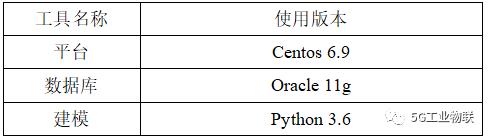
该模型的实现,是在Linux平台上实现的,在这个实现过程中,用oracle数据库存取数据,对数据进行初步清洗,利用python进行数据预处理、分析及聚类,最后是以excel和txt文件的形式输出结果。具体模型使用工具如表2所示。
表2 模型使用工具
4.2 实验数据
模型将东莞市**小区作为测试样本进行了模型准确性验证,具体如下:
通过互联网渠道获取,已知**小区房屋总数2500户,基站信息覆盖齐全,东莞移动市场份额y%,小区入住率87%。
利用小区的谷歌地球经纬度,获取位置在小区周围400米的宏基站驻留用户1万多,交往记录50万左右,进行异常值处理,剩余近8千目标用户。通过模型算法切割成2000左右个聚类群,最后选取了50个家庭(127个)的种子用户号码用于识别模型计算。
4.3 算法效果验证
通过识别模型计算,共识别出2283个家庭成员群,其中种子家庭数50个,成功识别42个,识别率到84%,具体数据如表3所示。
表3 家庭成员识别模型验证结果
①发现因部分家庭成员出差或者学生等原因,不能满足社区基站驻留时长要求导致的,存在少数家庭群体未覆盖齐整的情况。
②有部分用户家庭群体里有一些联系紧密的朋友,也同住一个小区,没有成功分离。
③同时算法理论(CH最佳)大于预先设置的最大值,
说明部分群体应该切割得更碎。
但从数据上看,识别结果符合基本情况,该模型是满足家庭成员识别准确性要求的。
当前在生产过程中,模型算法在处理目标用户达到万级以上的分割任务时,即使目标用户的相似矩阵经过稀疏处理后,运算时间复杂度依旧很高,尤其是要分割成任务几千个群体的时候,性能问题以及以上造成误差的问题需要通过运营商内部网络技术的提高来进行后续优化:
整体的解决思路是,可降低目标用户的体量或者减少所要切割的群体数量。按照目前运营商的技术及数据能力上,可以将从覆盖社区的宏基站下沉到仅能覆盖楼栋的室分基站上去,将目标用户群体从社区的几万,先分成几十上百个楼栋的小目标群体,每个小目标用户数量级以百级,所需要再进行切割的聚类数是几十个,这样就大大减少了模型的计算时间成本,也能将社区周边的商铺、快递外卖等低接触人员、偶尔串门的朋友剔除出室分基站目标群,一定程度上提高模型的异常数据占比。且不需要一线渠道经理提供社区资料,一切在后台便能处理。
实践是检验真理的唯一标准,经典的算法思想犹如巨人,本文站在巨人的肩膀上考究如何将算法和实践相结合,解决实际生产问题,现阶段已能解决了初步的业务问题。
但业务是在不断发展的,模型也需要根据实际的生产要求进行优化,希望以上的模型研究过程碰到的问题能给予该领域研究人士一些参考,便是本文最大的收获。
[1]蔡晓研, 戴冠中, 杨黎斌. 基于谱聚类的复杂网络社团发现算法[J]. 西北工业大学自动化学院, 2009.
[2]刘建平. 谱聚类原理总结[EB/OL]. http://www.cnblogs.com/pinard/p/6221564.html, 2017.
[3]谱聚类算法[EB/OL].
https://baike.baidu.com/item/%E8%B0%B1%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95.
[4] 聚类算法实现与分析[EB/OL]. https://blog.csdn.net/liuheng0111/article/details/52349006.
袁鸢:高级工程师,部门副总经理,硕士研究生,中国移动通信集团广东有限公司东莞分公司,主要研究方向为客户运营及数据分析。
李成奇:高级工程师,业务主任,硕士研究生,中国移动通信集团广东有限公司东莞分公司,主要研究方向为业务支撑和经营分析。
付文豪:
中级工程师,硕士研究生,中国移动通信集团广东有限公司东莞分公司,主要研究方向为客户运营及数据分析。
以上是关于基于聚类算法的家庭成员关系识别研究的主要内容,如果未能解决你的问题,请参考以下文章
综述聚类算法海洋应用国内国外的现状
基于聚类算法的供水管网爆管识别技术
黄钢,瞿伟斌等: 基于改进密度聚类算法的交通事故地点聚类研究
集成聚类系列:基础聚类算法简介
第二节:聚类研究方法进展
图像识别基于k-means聚类的手势识别matlab 源码