聚类算法(相似度与性能度量)
Posted 数学 算法 生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法(相似度与性能度量)相关的知识,希望对你有一定的参考价值。
1.相似度度量的方法有距离计算、余弦度计算和核函数计算
2.聚类算法性能度量分为外部指标和内部指标
3.外部指标大多存在一个问题:需要知道真实数据的标记类信息(类似监督学习)
4.内部指标主要有三个:轮廓系数、Caliniski-Harabaz指数和DB指数
5.轮廓系数处于[-1,1]的范围内,-1表示错误的聚类,1表示高密度的聚类
6.Caliniski-Harabaz指数同一簇类的数据集尽可能密集,不同簇类的数据集尽可能远离
7.DB指数的下限为0,DB指数越小,聚类性能越好
我们知道,聚类算法的核心就是如何定义簇,通常采取相似性度量,本文我们就对相似性以及和聚类结果好坏的评判依据做个介绍。话不多说,进入正题。
相似度计算方式
评价样本间相似度常用的方法是距离计算、余弦相似度计算和核函数计算,若样本间的距离越小,则相似度越高;若样本间的核函数值越大,则相似度越高。
在一文中,我们对核函数做个深入的介绍,以及给出了常用核函数的python实现,这里就不再赘述,直接介绍距离和余弦相似度。
距离计算最常用方法的是闵可夫斯基距离(Minkowski distance)
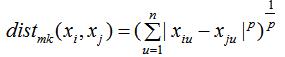
p=1时,闵可夫斯基距离即曼哈顿距离(Manhattan distance);
p=2时,闵可夫斯基距离即欧氏距离(Euclidean distance)
余弦相似度就是向量夹角的余弦值:
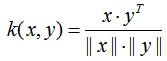
用python可以实现:
from sklearn.metrics import pairwise_distances
from sklearn.metrics.pairwise import pairwise_kernels
X = np.array([[2, 3]])
Y = np.array([[0, 1]])
pairwise_distances(X, Y, metric='euclidean')
pairwise_distances(X, Y, metric='manhattan')
pairwise_distances(X, Y, metric='cosine') #这里计算出来的是(1-向量夹角余弦值)
from sklearn.metrics.pairwise import cosine_similarity #计算矩阵X两两样本的余弦相似度
X = pd.DataFrame([[1,1,0,1,0],[1,0,1,0,0],[0,1,0,0,1],[0,0,1,1,1]],columns=['a','b','c','d','e'])
print(cosine_similarity(X))
性能度量
聚类性能度量根据训练数据是否包含标记数据分为两类,一类是将聚类结果与标记数据进行比较,称为外部指标;另一类是直接分析聚类结果,称为内部指标。
外部指标大多存在一个问题,就是需要知道真实数据的标记类信息,因此在实践中很难得到应用(类似监督学习)。实践过程中也常常用内部指标衡量,因此我们着重介绍内部指标。
外部指标
先介绍一点预备知识.
设样本集 Sn={x1,x2,.....,xn},样本集合的真实类别 U={u1,u2,...,ur},样本集合的聚类结果 V={v1, v2,...,vc}
我们定义:
a:在U中为同一类且在V中也为同一类的数据点对数(TP)
b:在U中为同一类且在V中不是同一类的数据点对数(FN)
c:在U中不是同一类且在V中为同一类的数据点对数(FP)
d:在U中不是同一类且在V中也不是同一类的数据点对数(TN)
举个例子:
若真实簇向量[0,0,0,1,1,1],预测簇向量[0,0,1,1,2,2],则a = 2,d = 1
1.RI(兰德系数)
RI是衡量两个簇类的相似度,假设样本个数是n,定义:

RI系数的缺点是随着聚类数的增加,随机分配簇类向量的RI也逐渐增加,这是不符合理论的,随机分配簇类标记向量的RI应为0
2.ARI(调整兰德系数)
ARI解决了RI不能很好的描述随机分配簇类标记向量的相似度问题,ARI的定义:
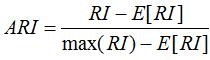
其中E表示期望,max表示取最大值。
3.Fowlkes-Mallows分数
Fowlkes-Mallows指数(FMI)是成对准确率和召回率的几何平均值:
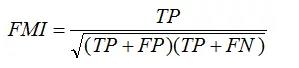
附一下sklearn包调用方式
from sklearn import metrics
labels_true =[0,0,0,1,1,1]
labels_pred =[0,0,1,1,2,2]
ARI = metrics.adjusted_rand_score(labels_true, labels_pred)
FM = metrics.fowlkes_mallows_score(labels_true,labels_pred)除此之外,还有AMI(调整的互信息指数),同质性,完整性和V-measure都是衡量外部指标的。
内部指标
1.轮廓系数
每个样本有对应的轮廓系数,轮廓系数由两个得分组成:
a:样本与同一簇类中的其他样本点的平均距离
b:样本与距离最近簇类中所有样本点的平均距离
每个样本的轮廓系数定义为:
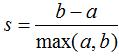
注:一组数据集的轮廓系数等于该数据集中每一个样本轮廓系数的平均值。
该评价指标具备特点:
轮廓系数处于[-1,1]的范围内,-1表示错误的聚类,1表示高密度的聚类,0附近表示重叠的聚类
当簇密度较高且分离较大时,聚类的轮廓系数亦越大
凸簇的轮廓系数比其他类型的簇高
2.Caliniski-Harabaz指数
评价聚类模型好的标准:同一簇类的数据集尽可能密集,不同簇类的数据集尽可能远离。
定义簇类散度矩阵:
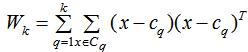
簇间散度矩阵:
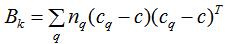
其中Cq为簇类q的样本集,cq为簇类q的中心,nq为簇类q的样本数,c为所有数据集的中心。
根据协方差的相关概念,我们用簇类散度矩阵的迹表示同一簇类的密集程度,迹越小,同一簇类的数据集越密集(方差越小);簇间散度矩阵的迹表示不同簇间的远离程度,迹越大,不同簇间的远离程度越大(方差越大)。
结合评价聚类模型的标准,定义Calinski-Harabaz指数:
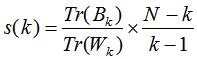
其中N为数据集样本数,k为簇类个数.
该评价指标具备特点:
当簇类密集且簇间分离较好时,Caliniski-Harabaz分数越高,聚类性能越好
计算速度快
凸簇的Caliniski-Harabaz指数比其他类型的簇高
3.DB指数(Davies-Bouldin Index)
我们用簇类C的平均距离表示该簇类的密集程度:
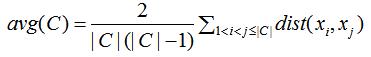
其中|C|表示簇类C的个数,dist(·,·)计算两个样本之间的距离。
不同簇类中心的距离表示不同簇类的远离程度:
其中ui,uj分别为簇类Ci和Cj的中心。
结合聚类模型评价标准,定义DB指数:
DB指数的下限为0,DB指数越小,聚类性能越好
该评价指标具备特点:
DB指数的计算比轮廓系数简单
DB指数的计算只需要知道数据集的数量和特征
凸簇的DB指数比其他类型的簇高
簇类中心的距离度量限制在欧式空间
附一下python实现方式:
from sklearn import metrics
metrics.silhouette_score()
metrics.davies_bouldin_score()
metrics.calinski_harabasz_score()参考资料:
https://mp.weixin.qq.com/s/cvr0kpI9kD18F09wULnmjA
以上是关于聚类算法(相似度与性能度量)的主要内容,如果未能解决你的问题,请参考以下文章