聚类算法(算法小结与案例分析)
Posted 数学 算法 生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法(算法小结与案例分析)相关的知识,希望对你有一定的参考价值。
1.要指定聚类类别数的算法有K-means和谱聚类;无需指定的有BIRCH和DBSCAN
2.K-means是基于质心,谱聚类基于无向图,BIRCH基于层次,DBSCAN基于密度
3.无法很好处理非凸数据集的聚类算法有K-means和BIRCH
4.能够检测异常点的聚类算法是BIRCH和DBSCAN
5.谱聚类能够很好处理稀疏数据集
聚类算法是一种无监督式学习算法,其目的是把同属一个类别的物体聚合在一起,聚合在一起的样本称为簇,算法的核心就是如何定义簇,通常采取相似性度量。
我们重点介绍了五种聚类算法:基于质心的K-means算法,基于概率分布的GMM算法,基于密度的DBSCAN算法,基于无向图的谱聚类,以及基于层次聚类的BIRCH算法,其中K-means可以看成GMM的特殊情形。
这一篇我们对这几个聚类算法做一下总结(sklearn包介绍)以及分享一些实操案例。
往期文章:
算法小结
先给出各自的优缺点
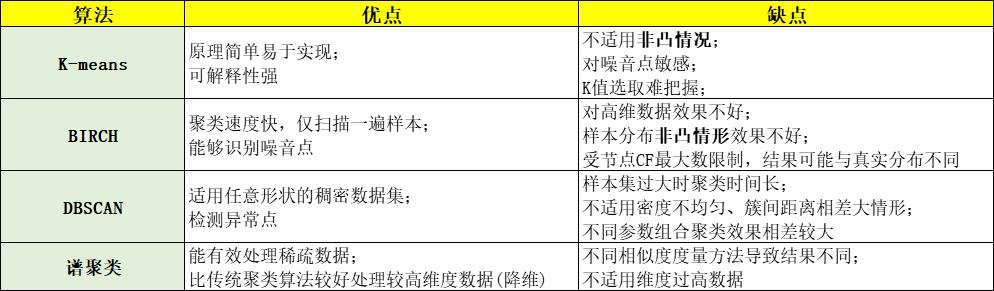
要指定聚类类别数的算法:K-means、谱聚类;不用指定聚类类别数的算法:BIRCH、DBSCAN
K-means算法
算法流程:

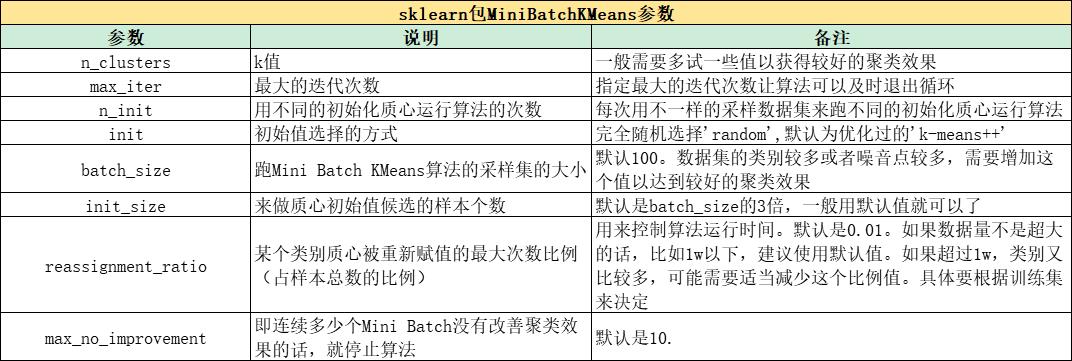
sklearn包:
from sklearn.cluster import KMeans
from sklearn.cluster import MiniBatchKMeans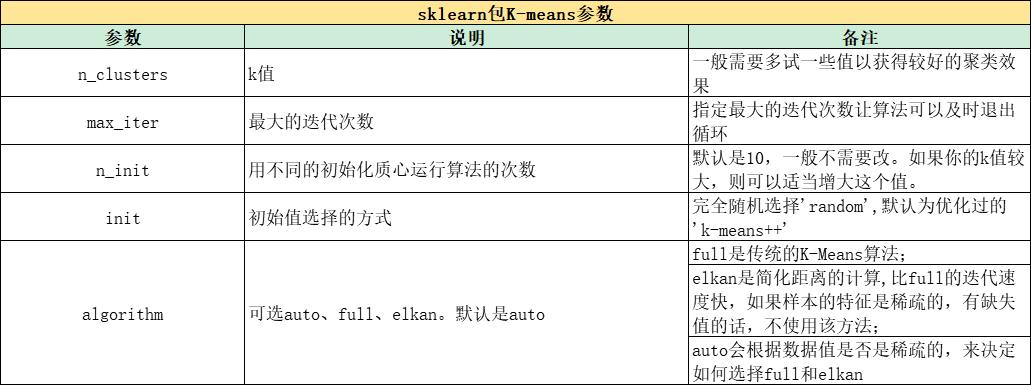
谱聚类
算法流程:

sklearn包:
from sklearn.cluster import SpectralClustering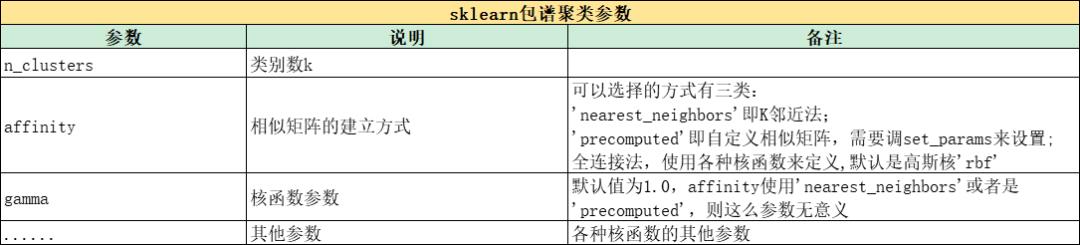
BIRCH算法
算法流程:
1) 将所有的样本依次读入,建立一颗聚类特征树CF Tree
2)(可选)将第一步建立的CF Tree进行筛选,去除一些异常CF节点,这些节点一般里面的样本点很少。对于一些超球体距离非常近的元组进行合并
3)(可选)利用其它的一些聚类算法对所有的CF元组进行聚类,得到一颗比较好的CF Tree.这一步的主要目的是消除由于样本读入顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂
4)(可选)利用第三步生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类。这样进一步减少了由于CF Tree的一些限制导致的聚类不合理的情况
sklearn包:
from sklearn.cluster import Birch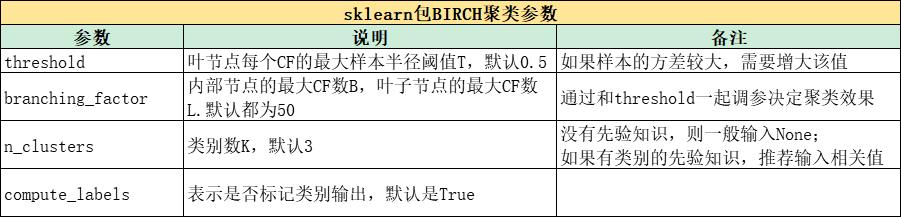
DBSCAN算法
算法流程:

sklearn包:
from sklearn.cluster import DBSCAN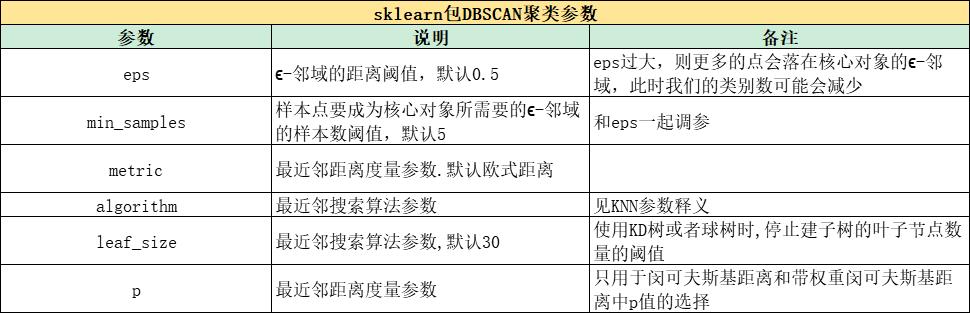

案例分析
我们用python来实现一些简单的案例。
先来看K-means算法:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from scipy.stats import multivariate_normal
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()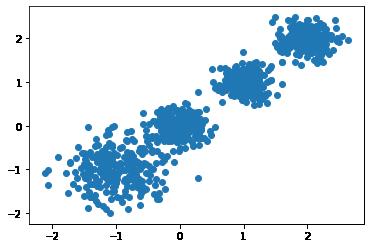
我们聚成四类看看效果
y_pred = KMeans(n_clusters=4, random_state=0).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
print('Calinski-Harabasz分数为:',metrics.calinski_harabasz_score(X, y_pred))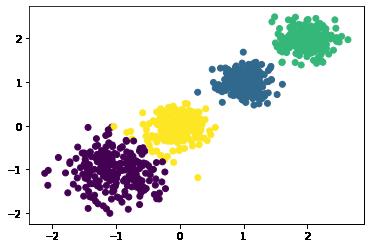
感觉还不错。
接着看一下层次聚类的BIRCH算法:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.3, 0.4, 0.3],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()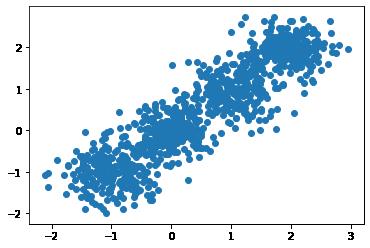
样本分布比较密集,不输入聚类类别,看看结果:
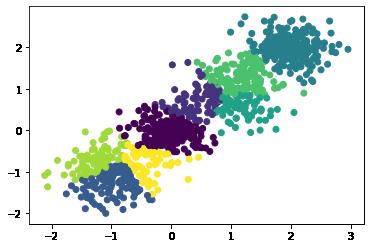
左下角好像没那么理想,限制到4个类别:
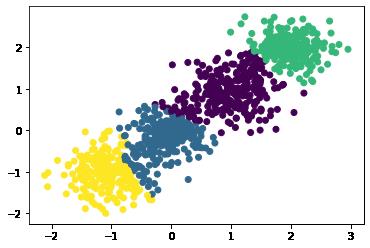
效果好了很多。
第三个看看DBSCN算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X1, y1=datasets.make_circles(n_samples=5000, factor=.6,
noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]],
random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()理想上应该是三类,我们设置参数看看效果
y_pred = DBSCAN(eps = 0.1).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()效果确实不错呢!
参考资料:
https://mp.weixin.qq.com/s/1SOQZ3fsiYtT4emt4jvMxQ
以上是关于聚类算法(算法小结与案例分析)的主要内容,如果未能解决你的问题,请参考以下文章