机器学习-kmeans/kmedoids/spectralcluster聚类算法
Posted 二层楼实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-kmeans/kmedoids/spectralcluster聚类算法相关的知识,希望对你有一定的参考价值。
n=20;a=1.4;x1=[12+rand(n,1)/a,12+randn(n,1)/a,12+randn(n,1)/a];x2=[5+randn(n,1)/a,24+rand(n,1)/a,4+randn(n,1)/a];x3=[24+randn(n,1)/a,26+randn(n,1)/a,26+randn(n,1)/a];x4=[31+randn(n,1)/a,36+randn(n,1)/a,33+rand(n,1)/a];dat=[x1;x2;x3;x4];
假设有80个样本,每个样本有3个特征。
原始数据分布如下:
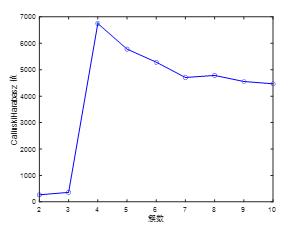
对聚类簇数量的评估,分为4类最优。
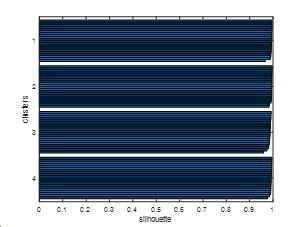
分为4类的轮廓图如下,轮廓值较大且均匀,聚类质量较好。
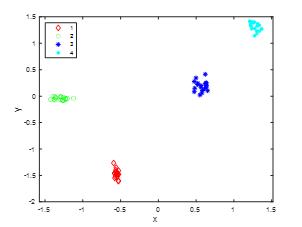
聚类结果如下:
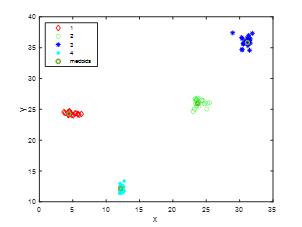
如下是kmedoids聚类结果及其中心点。
如下是spectralcluster聚类结果及相似度图。
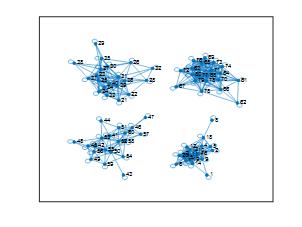
实际工程应用中,需根据问题及数据特征选择合适的聚类算法。
[历史文章]
以上是关于机器学习-kmeans/kmedoids/spectralcluster聚类算法的主要内容,如果未能解决你的问题,请参考以下文章