第1446期精致化的微前端开发之旅
Posted 前端早读课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第1446期精致化的微前端开发之旅相关的知识,希望对你有一定的参考价值。
前言
挺有意思的概念,不知道落地的有多少呢?今日早读文章由ThoughtWorks@Trotyl Yu分享。
正文从这开始~~
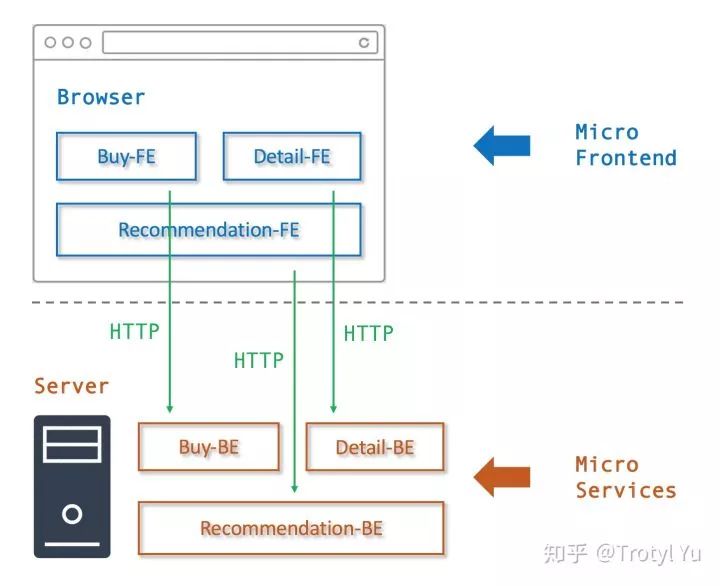
微前端(Micro-Frontend),是将微服务(Micro-Services)理念应用于前端技术后的相关实践,使得一个前端项目能够经由多个团队独立开发以及独立部署。
本文中将会以此为目标,从零构建一套微前端的开发方案的最佳实践,并用于完成 Micro Frontends 网站中的示例应用:
任何地方的最佳实践都是基于主观判断的,不要脱离实际盲从。
微前端开发的目标
微前端实践中,事实上所有的需求都是为「独立开发」以及「独立部署」这两大目标服务的,或者可以认为是两者的具体实现措施或者自然衍生结果。通常我们所说的「微前端特性」包括但不仅限于:
技术无关:各个开发团队都可以自行选择技术栈,不受同一项目中其它团队影响;
代码独立:各个交付产物都可以被独立使用,避免和其它交付产物耦合;
样式隔离:各个交付产物中的样式不会污染到其它组件;
原生支持:各个交付产物都可以自由使用浏览器原生 API,而非要求使用封装后的 API;
为了能够实现微前端的目标,需要对项目整体进行拆分和隔离。
早些时候,我们可能会想到 iframe ,想必对于「为什么不用 iframe」大家都能给出两只手数不过来的理由了。
近些年,另一套 Web 原生的拆分隔离方案逐渐进入人们的视野,那便是 Web Components。不过,这里对 Web Components 一样持否定态度。
为什么 Web Components 不是一个有效方案
为了了解否定 Web Components 的原因,首先简要介绍一下 Web Components 是什么。

Web Components 是由 W3C 维护的技术概念集,目前包含:
Shadow DOM
Custom Elements
html Templates
CSS changes
这四部分技术内容。
曾经还包含过 HTML Imports,但早已被移除,很多相关资料都没有更新。
需要注意的是,虽然 Web Components 包含哪些内容是 W3C 维护的,但是里面的技术本身并不是,Shadow DOM、Custom Elements 和 HTML Templates 都是 HTML Living Standard 和 DOM Living Standard 中的正式内容,由 WHATWG 维护。
因此对于 Web Components 的否定涉及到两个层面:
作为交互中间层的场景下,Shadow DOM、Custom Elements 和 HTML Templates 解决的问题是完全独立的:Shadow DOM 用于辅助样式隔离,Custom Elements 用于简化启动代码,而 HTML Templates 用于内部实现对中间层封装毫无帮助。作为技术选型而言,每个问题的解决方案也是相互正交的,因此 Web Components 这个伪概念在此并不能发挥任何整体价值;
Shadow DOM、Custom Elements 分别都不是相应问题的有效解决方案,以下会详细说明。
至此,我们已经可以完全忘掉 Web Components 这个伪概念,只看具体技术本身。
首先需要注意的是 Shadow DOM 和 Custom Elements 都只有 IE11+ 的 Polyfill 支持,因此需要考虑 IE9 和 IE10 的应用可以直接排除。但即便对于只需要考虑 IE11+ 的应用而言,这两项技术也并非最优解。
Custom Elements 的隐形成本

Custom Elements 用于扩展 HTML Elements 的 Registry,让 HTML Parser 以及能够识别自定义的元素名*,并且还能够自动触发相应的声明周期。
准确的说 Custom Elements 包含 Autonomous custom elements 和 Customized built-in elements 两种类型,由于后者既没有浏览器的统一原生支持(Firefox 宣布了不会支持)也没有可用的 Polyfill,因此本文中默认仅仅指代前者。
有了 Custom Elements 之后,启动代码就是 HTML 本身(或者相应的 DOM API 调用):
<book-card title="Custom Elements" author="Web" price="42"></book-card>以及:
const bookCard = document.createElement('book-card')
bookCard.setAttribute('title', 'Custom Elements')
bookCard.setAttribute('author', 'Web')
bookCard.setAttribute('price', '42')虽然看似和一般的 HTML 模版代码无异,但事实上 Custom Elements 和框架模版中明显不同之处的是:没有 Scoping 和 Validation。
如果元素名出现偏差或者被依赖组件未被引入运行时,那么就只会得到一个 HTMLUnknownElement,并不会出现任何错误,从而让用户得到不预期的结果。
另外从 DOM 操作也能看出一个主要问题所在:DOM API 不支持批量更新。
对于原生的 DOM 操作而言,这样当然不会引发什么问题。不过在当前应用中,Custom Elements 的职责是生命周期代理,处理方式就是在 attributeChangedCallback 生命周期中通知其它框架进行更新操作。类似于:
class BookCard extends HTMLElement {
attributeChangedCallback(name: string, oldValue: string, newValue: string) {
someOtherFramework.update({ [name]: newValue })
}
}而因为没有批量更新,上述修改 title、author 和 price 的场景中,触发了整整三次数据更新操作,而对于(绝大多数)视图同步框架而言,数据更新会有固定的额外成本(即使没有任何视图修改),不仅引起不必要的性能浪费同时还可能进入不预期的中间状态。
当然存在一些 Workaround,例如在封装层统一等待 nextTick,或者使用接受对象的 DOM 属性来进行更新操作,但是不论对于可维护性还是易用性而言仍然会造成可观的影响。
Shadow DOM 对服务端渲染的高度破坏
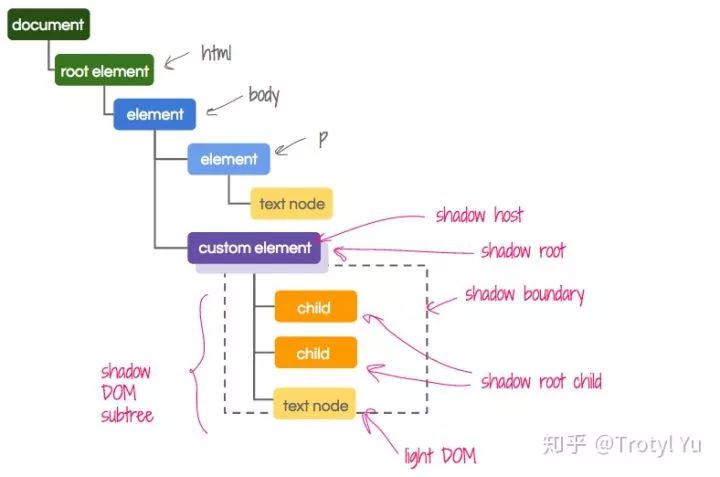
Shadow DOM V0 中引入了 Content Projection 的机制,通过 <content> 元素实现。之后的 V1 版本中改为 <slot> 元素。
我们知道,服务端渲染能够直接产出静态 HTML 被浏览器解析,不过 <slot> 的出现让正确的服务端渲染变得不可能。
假设一个组件具备如下的 Shadow DOM:
<div class="foo">
<h4>Foo</h4>
<slot></slot>
</div>被如下代码使用:
<element-details>
<p>Bar</p>
</element-details>那么实际渲染结果为:
<element-details>
<div class="foo">
<h4>Foo</h4>
<p>Bar</p>
</div>
</element-details>问题在于,如果我们真的在服务端渲染出该结果,再从浏览器端启动,那么服务端的渲染结果就会被视为原始内容,再次进行投影:
<element-details>
<div class="foo">
<h4>Foo</h4>
<div class="foo">
<h4>Foo</h4>
<p>Bar</p>
</div>
</div>
</element-details>之所以 Web 框架中不会出现该问题*,是能够对投影过程进行控制(使用额外的特殊属性进行标注),而在原生实现中并没有相应的控制权,无法区分原始内容,从而导致不正确的多重渲染。
更真实的原因是大部分 Web 框架压根就不支持从外部 HTML 抽取子内容节点,只能在框架内部使用。
所以如果要使用 Shadow DOM,必须让所有开发人员签名承诺绝不使用 <slot> 元素。即便如此,也还有其它方面的问题,例如 style。
与一般的 Web 开发理念不同的是,Shadow DOM 中使用内嵌的 style 元素是推荐的开发方式(除此之外只有 Inline Style 有效),并且仅对 Shadow Root 有效。
而一旦将 style 渲染为子节点,那将会对页面样式产生极大的破坏:
<element-details>
<style>
p { background-color: red }
</style>
<p>Foo</p>
</element-details>
<p>Bar</p>所以除了 slot 元素之外,style 元素也别用了,老老实实全部写成 Inline Style 吧。不过问题来了,使用 Shadow DOM 的核心目的就是样式隔离,不能受益于此的话为什么还要用 Shadow DOM 呢?
交付产物的设定
所谓的「微前端」理念下,交付产物大体可以分为几个不同的级别:
独立部署的网站:开发团队的构建产物为独立网站并自行完成网站的部署,通常对应的集成方式为在多个长得很像的网站之间跳转或者 iframe 标签引入外部页面;
网站内容:开发团队的构建产物为独立网站但通过压缩包上传并部署到统一位置,通常对应的集成方式为服务器端的反向代理;
页面脚本:开发团队的构建产物为 javascript 代码文件*并被站点引入到站点中;
目前存在一个 HTML Modules 提案,虽然发布的内容是 HTML 文件但是引入方式是 ES Module,这里也视为发布 JavaScript 代码的方式。
而后在发布 JavaScript 代码的大方向之下,大体又可以分为两个类别:
发布组件:启动位置和时机完全由父级内容控制,支持多实例,例如 Custom Elements;
发布局部应用:启动过程由自身配置,只能单实例,例如 single-spa;
可以简单的类比为,前者发布的是「类」,后者发布的是「实例」。这里我们选择前者,所有发布的内容都是可以重用的组件,由父组件决定何时及何处使用。
由于之前已经排除了 Custom Elements 的选项,当然也就需要定义新的接口来满足组件化的需求,同时避免 Custom Elements 中的缺陷。
组件化设计

由于目标仅仅是实现生命周期代理,自身并不需要视图管理的支持,所以一切现有的框架都过重,而且不可控的风险极高。为此需要自行定义一套 API,选择的方案有很多,例如一个很简介有效的设计就是 Svelte 的 get/set API:
// Set state
component.set({ value: 42 })
// Get state
const { value } = component.get()通过统一的状态更新 API,能够有效解决批量更新的问题:
component.set({
title: 'Svelte-style',
author: 'Svelte',
price: 42,
})至于事件通信 API 和生命周期 API 就可以更为随意了。
之后,还需要考虑组件与组件之间如果建立依赖关系。Custom Elements 方案中存在的一个显著问题就是「组件使用」与「依赖建立」的脱节,单反面依靠外部环境一次性引入所有内容。
要建立 JavaScript 文件之间的依赖关系,最为直观的方式就是 ES Module,类似于:
import { render, Component } from '@domain/mf-helpers'
import { MyComp1 } from '@domain/lib1'
class MyComp2 extends Component {
someMethod() {
render(MyComp1, myElement)
}
}此外还可以靠 Dynamic Imports(Stage 3 Proposal)处理动态内容的依赖:
import { render, Component } from '@domain/mf-helpers'
class MyComp2 extends Component {
async someMethod() {
const { MyComp1 } = await import('@domain/lib1')
render(MyComp1, myElement)
}
}基于 ES Module 建立的引用关系,可以让组件的可用性变得绝对可靠。如果被依赖模块加载失败,那么当前模块也不会被执行,从而进入到统一的错误处理页面。当然,在 Dynamic Import 的方式下,调用者可以自行定义局部错误处理,提供 Fallback 支持*。
除非有明确的应用边界(例如小程序级别的独立子程序),否则 Fallback 行为并不靠谱,对于整体应用而言依赖不可用的情况下应该立即报错,而非尽最大努力运行。
这样在源码层面上极大保证了可读性和可维护性,有效提升了开发效率。
当然,我们知道实际应用中并不会在生产环境直接使用浏览器的模块支持,而是预先进行打包构建。为了保持独立部署的目标,需要在构建过程中排除其它组件的依赖,并将依赖的确定过程延期到运行时的处理。
而至于样式隔离,直接交由各个团队自行处理即可,主流框架基本都提供了组件样式解决方案。此外,靠约定前缀并不能避免样式冲突,虽然不会污染父组件,但仍然能够对子组件产生污染。(除非只使用父子选择器不用后代选择器)
一般在整个应用中,只有某一级特定组件才会使用路由(每个组件用不用得到自己心里有数),因此组件设计中将当前的 basePath 和 navigationFn 经由 Context 层层传递,如果有某个组件需要实现子路由,自行封装并暴露到下级即可。
构建与部署策略
之前已经提到,为了保证开发效率,源码中仅仅使用 ES Module 来引入外部组件,不过并不打包到当前组件中,而是推迟到运行时决定。
这里可能会产生的疑问是,组件是否需要发布到 Registry?
答案是需要,为了实现两个目标:
Library as a Constraint:模块导出、类型签名能够静态确定;
Registry as a CDN:不同版本同时处于可访问状态;
技术层面上仍然是不需要的,只需要发布后的 URL 即可。
这里的 Registry 并不一定是 NPM Registry,任何能够稳定追溯的机制均可,例如 Git Tags。
虽然构建工具层面不要求安装依赖,但是作为依赖安装能够有效提升开发体验,例如编辑器的代码提示,同时版本发布应当符合语义化版本号的要求(并能够进行运行时验证)。
同样,虽然运行时需要的只有组件发布的 URL,然而通过 Registry 发布能够获得诸多优势:
全版本实时可用:发布新版本并不会替换掉原有版本,所有版本同时处于可用状态,能够通过在 URL 中指明版本进行访问,例如 @angular/core@6.0.4/bundles/core.umd.js,以至于在切换版本(更新或者回退)时,并不需要重新部署相应代码,而仅仅修改版本配置文件即可;"">https://unpkg.com/@angular/core@6.0.4/bundles/core.umd.js,以至于在切换版本(更新或者回退)时,并不需要重新部署相应代码,而仅仅修改版本配置文件即可;
Alias 自动更新:为了方便自动同步,测试环境中可以并不使用具体版本号,而使用 Alias,例如在 Staging 环境中使用 @stable,就能无需配置自动同步最新版本,快速验证兼容性问题。
除此之外,需要引入运行时的依赖管理方案。
ES Module 虽然在所有主流浏览器中都已经得到支持,但是大部分应用仍然需要照顾部分老旧版本,同时 ES Module 的模块引入过程无法拦截,因此无法使用原生实现。
当前的主流模块格式中,能够用于浏览器运行时的只有 AMD 和 System.register 两种,相比之下后者要强大的多,几乎提供了 ES Module 的语义的完整支持(例如循环依赖和顶层异步等待)。同时,后者也有 SystemJS 这样的优秀工具,自带扩展支持,从而无需从零开始自行实现。
例如对于 ES Module 的代码:
import { render, Component } from '@domain/mf-helpers'
import { MyComp1 } from '@domain/lib1'
export class MyComp2 extends Component {
someMethod() {
render(MyComp1, myElement)
}
}打包为 System.registry 格式后输出为:
System.register('@domain/lib2', ['@domain/mf-helpers', '@domain/lib1'], function (exports, module) {
'use strict';
var render, Component, MyComp1;
return {
setters: [
function (module) { render = module.render; Component = module.Component; },
function (module) { MyComp1 = module.MyComp1; }
],
execute: function () {
class MyComp2 extends Component {
someMethod() {
render(MyComp1, myElement);
}
}
exports('MyComp2', MyComp2);
}
};
});这里虽然没有其它外部依赖,但需要注意的是,@domain 之外的其它组件内部依赖并没有实时更新的要求,可以直接打包到文件中。
为了进行版本验证,需要对输出内容进行部分扩展:
System.pkgInfo({
name: '@domain/lib2',
version: '1.0.1',
dependencies: {
'@domain/mf-helpers': { version: '^1.0.0' },
'@domain/lib1': { version: '^1.2.3' },
}
});
System.register(/* ... */);从而能够验证 lib1 和 lib2 是否匹配版本要求(还可以有其它后续扩展用途)。
虽然这里将 mf-helpers 作为外部依赖,但是完全应当允许内联,因此其内部实现必须完全 Structural,从而避免副本间冲突*。
准确的说并没有避免,只是通知相关人员去解决。
所以运行时需要扩展 System.register() 和 System.instantiate() 两个钩子,并增加 System.pkgInfo() 的实现。
依赖库的复用
虽然微前端的目标是代码隔离,但是仍然可以允许开发人员主动声明的可复用内容。
在当前的发布方式下,对可复用依赖和不可复用依赖进行差异化处理十分简单:不可复用依赖打包到组件内部,可复用依赖保留模块声明。不过仍然存在的问题是,如何实现可复用依赖的复用?
为了能够进行依赖复用,需要能够对依赖进行独立打包并记录其 URL:
System.pkgInfo({
name: '@domain/lib3',
version: '1.0.1',
dependencies: {
'some-lib': { version: '^1.0.0', path: './some-lib.js' },
}
});于是当 lib3 被运行时加载时,会判断当前环境中是否已经存在兼容 ^1.0.0 版本的 some-lib 包,如果不存在,则请求对应的 URL 获取。
不过应当注意,同一依赖的单副本与多副本差异可以会影响运行结果,声明可复用的依赖时需要确保其遵循语义化版本号并且没有内部状态,同时也希望自身没有其它外部依赖。当然现实中也很容易找到可复用依赖的典型,比如常用的工具库:lodash 或者 moment。
在线示例
这里重写了 https://micro-frontends.org/ 中的三团队项目,分别由 Angular、React、Vue 实现,完美对应颜色关系。
trotyl/mif-demo-angular
trotyl/mif-demo-react
trotyl/mif-demo-vue
基础设施位于:
trotyl/mif-core
trotyl/mif-runtime
由于文章是关于 Micro-Frontend 的讨论,因此示例代码中广泛使用 mif 作为前缀。
示例中以最外层 Red 团队组件作为根组件启动:
const { render, ROOT_CONTEXT } = mif.core
System.import('https://trotyl.github.io/mif-demo-angular/demo-angular.mif.js')
.then(m => m.RedApp)
.then(RedApp => render(RedApp, { context: ROOT_CONTEXT }, document.body))可以看出,文章分别从三个不同的 GitHub Repo 中加载了组件脚本,共同构成了这个完整但前端应用:
同时,虽然三个组件中都使用了 moment 作为依赖,但由于设置了允许复用,在整个应用中仅仅被加载一次,之后被所有组件所共用。
示例中使用的临时支持库仍然存在很多问题,并不建议直接在真实的微前端项目使用。
写在最后
微前端是一个巨大的话题,本文由于时间关系,并没有涉及到所有可能的方面。在目前的很多团队中,微前端实践往往意味着巨大的牺牲,例如仅仅为了优化所谓的部署时间,就不顾一切的放弃应用性能、代码质量、开发体验等等。而本文的目标则是探索一条尽可能保留当前前端生态的优秀实践,又能够满足微前端开发理念的精致化方案。
最后,为你推荐
以上是关于第1446期精致化的微前端开发之旅的主要内容,如果未能解决你的问题,请参考以下文章