第547期使用Gulp构建网站小白教程
Posted 前端早读课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第547期使用Gulp构建网站小白教程相关的知识,希望对你有一定的参考价值。
前沿
连续看了两天的跨域,估计要吐了。今天除了专访外,再来补充一个现在在前端比较常用的构建工具gulp原理,本文由@墨白推荐,@75team原创授权。
正文从这开始~
行业里有一种批评,说前端太浮躁,总是追逐新技术,感觉 还不熟悉,突然一夜之间满大街都在谈论 了。月影觉得不能怪技术发展太快,技术发展总是带来好处多于坏处,有时候我们确实需要鼓起勇气去“追求”技术潮流,当然理由是为了弄明白为什么有这些技术工具,而无关于什么浮躁之类的事儿。
也许是从业很多年有点累了,月影也对技术有些后知后觉,感觉 gulp 已经火了很久,才终于想起来写这篇文章,也许现在,很多工程师早已又去追求其他的什么类似的构建工具了。不管怎么样,如果你是一位前端工程师,你从来没有想过用构建工具优化网站这种事儿,或者你在工作中所在的团队和平台已经有成熟的工具,工作中不用自己再去琢磨 gulp 。你仍然可以暂时停下来阅读这篇文章,看看 gulp 这样的构建工具如何能帮你更简单地在构建的时候自动优化你的网站,也许你的个人博客也需要优化,也许你换了工作,要和之前熟悉不一样的构建工具,然而基本原理终归是“一招鲜吃遍天”的,不是吗?
什么是 Gulp?
Gulp 的官网title上对这个工具有一个比较准确的定义,叫做:基于流的自动化构建工具。如果你查看它的网页源代码,还会看到在<meta>标签里有一段更详细的描述:
Gulp.js 是一个自动化构建工具,开发者可以使用它在项目开发过程中自动执行常见任务。Gulp.js 是基于 Node.js 构建的,利用 Node.js 流的威力,你可以快速构建项目并减少频繁的 IO 操作。Gulp.js 源文件和你用来定义任务的 Gulp 文件都是通过 javascript(或者 CoffeeScript )源码来实现的。
所以,Gulp 是在项目开发过程中自动执行任务的一个工具,通过它可以方便地在开发时(或者发布前),对目标文件的内容进行I/O操作。
由于 Gulp 是基于流的,所以 Gulp 对于文件内容的操作就像是水槽对于水流,水流流经水槽,水槽将水流塑造成不同的形状。
既然是基于流的,在进一步理解 Gulp 前,我们最好先来理解什么是流。
Stream 流
在计算机系统中文件的大小是变化很大的,有的文件内容非常多非常大,而 Node.js 里文件操作是异步的,如果用一个形象的比喻来形容将一个文件的内容读取出来并写入另一个文件中,可以将它想象成文件内容像是水流,从一个文件“流”入另一个文件。
在node里面,读写文件可以用“流”来描述:

上面的代码除了将 in.txt 文件中的内容输出到 out.txt 之外,不做其他任何事情,相当于复制了一份数据,从语法形式上可以看到,“数据流”从 fs.createReadStream 创建然后经过 pipe 流出,最后到 fs.createWriteStream。
在这输入流到输出流的中间,我们可以对“流”做一些事情:

在上面的代码里,我们通过 Node.js 的 库(这是一个针对“流”的包装库),将输入流一步步转换成输出流,在中间的 pipes 中我们先是将 Buffer 转成 String,然后将它变成大写,最后再 reverse 然后传给输出流。
所以如果 in.txt 的文件内容是 hello world~,那么 out.txt 的文件内容将是: ~DLROWOLLEH。
基于流的 Gulp
月影觉得 Gulp 的文档其实写得挺烂的,点中文文档页面除了让你看、、、之外就没什么了,但实际上真要用 Gulp 的高级功能,这些文档简直就和教人如何画马一样:
既然 Gulp 是基于流的,我们就要理解 Gulp 如何控制和操作流。
然而在这之前,我们还要先看最基础的(还没安装 Gulp 的同学可以照前面那个入门指南安装一下~)

我们可以看到 Gulp 是基于任务的,gulp.task 可以定义一个任务,这样的话,我们在命令行下就可以通过 gulp 任务名 的方式来执行命令了:
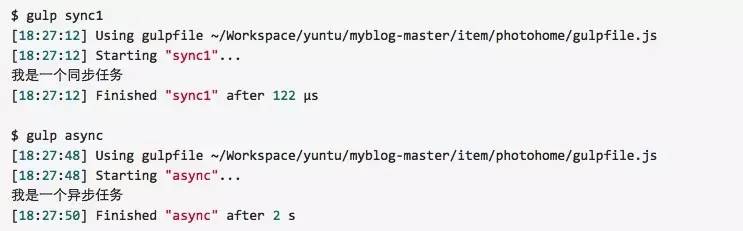
Gulp 的任务可以是同步和异步,在异步任务中确定任务完成,可以通过调用函数参数 done 来实现。
Gulp 也允许我们将任务组合起来执行:

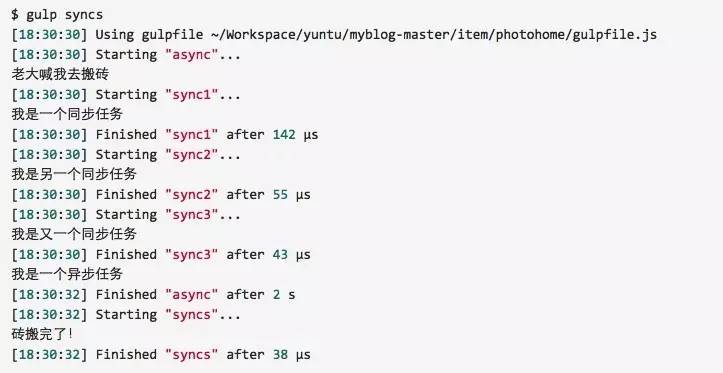
我们看到说 gulp.task 可以有依赖,只要第二个参数传一个数组,中间加上依赖的任务就行了,而数组里面的这些任务是并行处理的,不会一个执行完才执行另一个(同步任务的输出比异步任务的结束早)。
以上是 Gulp 基本的任务模型。对于每个 task,Gulp 通常用来操作文件输入和输出流,因此Gulp 封装了批量操作文件流的 api:

上面的命令表示将当前目录下所有的.html 文件匹配出来,依次输出到目标文件夹 ./dist 中去。
我们还可以用更高级的通配符:

这样处理的 html 文件不仅仅匹配当前目录下的,还包括所有子目录里。关于输入这块,具体的用法还有很多,遵循的规范是glob模式,可以参考
处理文件的内容
与上面说的 FileSystem 文件流类似,如果我们不做什么别的事情,那么我们就只是将文件从源src,拷贝到了目的地 dest,其他的啥也没做,那么显然,我们可以做那么一些事情,在这里,我们尝试处理一下 index.html:
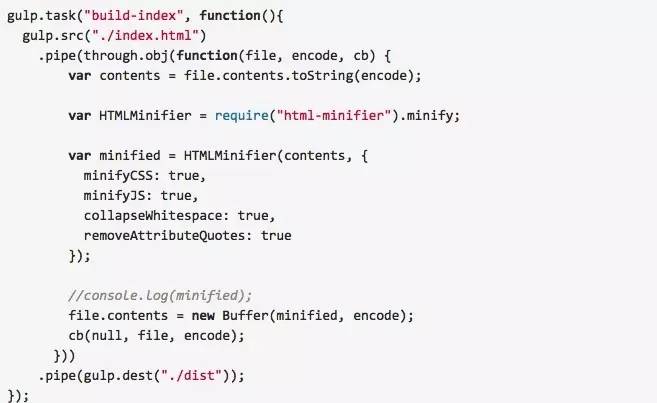
gulp.src 的输入流和 fileReadStream 会有一点点不一样,它的第一个参数不是一个 Buffer,而是一个包含文件信息和文件内容的对象,第二个参数是文件的编码,因此我们可以通过

将文件内容转成字符串。之后,我们使用 对文件的HTML内容和内联的样式、脚本进行压缩,这样就简单完成了首页 index.html 的优化!
进一步优化
前面只完成了优化的第一步,我们还没考虑外链资源该怎么处理呢,外链资源包括 js、 css 和图片。在处理之前,我们来约定一些规范:
页面 js 存放在 ./static/js 下,公共的库放在 ./static/js/lib 下,公共库只压缩不合并,页面 js 压缩并合并。
页面 css 存放在 ./static/css 下,公共的css放在./static/css/common 下,公共 css 只压缩不合并,页面 css 压缩并合并。
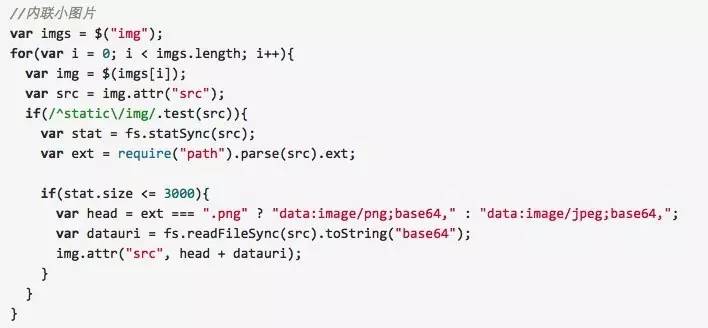
图片资源中小于3kb的图片以 base64 方式内联,图片放在 ./static/img 下。
压缩 js

压缩 js lib

压缩 css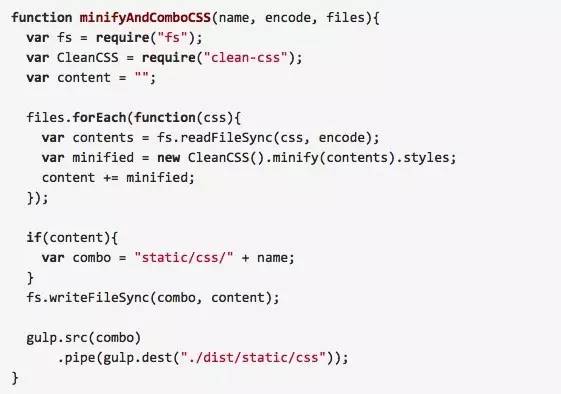
压缩公共 css

处理图片
压缩 HTML

然后,在处理 index.html 的时候,我们可以使用 来解析文件,将要处理的外链从文档中提取出来。
提取 js 和 css 外链处理
总结
我们用 Gulp 创建了一个非常简单的构建脚本,它可以压缩合并我们项目的 js 和 css 并处理小图片,我们还可以给它进一步增加其他功能,例如给压缩的文件添加版本号,或者根据内容计算签名以实现更新后不被缓存,我们还可以用 CDN 服务的 sdk 将资源发布到 CDN 并替换原始链接,同时,我们可以不用每次发布所有的文件,我们可以在开发的时候用 gulp.watch 来监控文件的修改,以实现增量的编译发布。
总之,我们可以用 gulp 来做许多有用的事情,来完善我们的构建脚本,而这一切都因为 gulp 基于流的构建以及 NPM 丰富的库变得非常简单。最后的最后,由于我们从头使用 through2 来处理任务,所以我们在具体实现功能的时候还是略微繁琐,事实上 gulp 提供了不少有用的,这些插件直接返回 stream 对象,可以让构建过程变得更简单,具体的可以多研究官方的文档。
后语
关于作者月影,你可能还可以看看早读君对他的专访:
关于本文
原文链接:http://blog.h5jun.com/post/gulp-build.html
以上是关于第547期使用Gulp构建网站小白教程的主要内容,如果未能解决你的问题,请参考以下文章