论文:Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文:Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition相关的知识,希望对你有一定的参考价值。
参考技术A细粒度的视觉识别具有挑战性,因为它高度依赖于各种语义部分的建模和细粒度的特征学习。基于双线性池的模型已被证明在细粒度识别方面是有效的,而以前的大多数方法忽略了层间部分特征交互和细粒度特征学习是相互关联、相互促进的这一事实。在本文中,我们提出了一个新的模型来解决这些问题。首先,提出了一种跨层的双线性池化方法来捕获层间零件特征关系,与其他基于双线性池化的方法相比,具有更好的性能。其次,我们提出了一个新的层次双线性池架构,整合多个跨层的双线性特征,以增强其表示能力。我们的公式是直观的,有效的,并取得了最先进的结果,在广泛使用的细粒度识别数据集。
细粒度分类中利用局部特征的方法有较大局限性。
因此,使用图像级标签的分类方法。例如,Simon和Rodner[26]提出了一个星座模型,利用卷积神经网络(convolutional neural network, CNN)来寻找神经激活模式的星座。Zhang等人[36]提出了一种自动细粒度图像分类方法,该方法结合了深度卷积滤波器来进行与部件相关的选择和描述。这些模型将CNN作为局部检测器,在细粒度识别方面取得了很大的改进。 与基于部件的方法不同,我们将不同卷积层的激活视为对不同部件属性的响应,而不是显式地对目标部件进行定位,而是利用跨层双线性池来捕获部件属性的层间交互,这被证明对细粒度识别非常有用。
也有研究[3,6,17,12]引入双线性池化框架对对象局部进行建模。虽然已经报告了一些有希望的结果,但进一步的改进还存在以下局限性。 首先,现有的基于双线性池的模型大多只将最后一个卷积层的激活作为图像的表示,不足以描述对象的各个语义部分。其次,忽略了中间的卷积活动,导致细粒度分类的判别信息丢失,而这些信息对于细粒度的视觉识别具有重要意义。
众所周知,CNNs在传播过程中存在信息丢失。 为了最大限度地减少对细粒度识别有用的信息损失,我们提出了一种新的层次双线性池结构来集成多个跨层的双线性特征,以增强其表示能力。为了充分利用中间卷积层的激活,在最终分类之前将所有跨层双线性特征连接起来。 注意,不同卷积层的特征是互补的,它们有助于鉴别特征学习。因此,该网络从层间特征交互和细粒度特征学习的相互增强中获益。我们的贡献总结如下:
1.我们开发了一种简单但有效的跨层双线性池技术,该技术同时支持层间特性交互和以相互增强的方式学习细粒度表示。
2.提出了一种基于跨层双线性池的分层双线性池框架,将多个跨层双线性模块集成在一起,从中间卷积层获取互补信息,从而提高性能。
3.我们对三个具有挑战性的数据集(幼鸟、斯坦福汽车、fgvc飞机)进行了综合实验,结果证明了我们方法的优越性
本文的其余部分组织如下。第二部分是对相关工作的回顾。第3节介绍了提出的方法。第4节提供了实验和结果分析,第5节给出了结论。
在接下来的文章中,我们将从与我们工作相关的两个有趣的角度简要回顾一下之前的工作,包括CNNs中的细粒度特征学习和特征融合。
1.为了更好地对细粒度类别的细微差异进行建模,Lin等人[17]提出了一种双线性结构,通过两个独立的CNNs来聚合成对的特征,该结构采用特征向量的外积来产生一个非常高维的二次展开特征。
2.Gao等人利用张量勾画出[23]来近似二阶统计量并降低特征维数。
3.Kong等人对协方差矩阵采用低秩近似,进一步降低了计算复杂度。
4.Yin等人通过迭代地将张量草图压缩应用到特征上来聚合高阶统计量。
5.[22]的工作以双线性卷积神经网络为基线模型,采用集成学习的方法进行加权。
6.在[16]中,提出了矩阵平方根归一化,并证明了它是对现有归一化的补充。
但是,这些方法只考虑了单个卷积层的特征,不足以捕捉对象的各种判别部分,也不足以模拟子类别间的细微差别。我们提出的方法通过将层间特征交互和细粒度特征学习以一种相互增强的方式结合起来,克服了这一局限性,因而更加有效。
【3,7,19,33】研究CNN中不同卷积层的特征图有效性。
作者将每个卷积层作为不用对象部分的属性提取器,并以直观有效的方式对他们直降的交互进行建模。
在本节中,我们建立了一个层次双线性模型来克服上述限制。在提出我们的层次双线性模型之前,我们首先在3.1节中介绍了用于细粒度图像识别的分解双线性池的一般公式。在此基础上,我们在3.2节中提出了一种跨层的双线性池技术,联合学习不同卷积层的激活,捕获信息的跨层交互,从而获得更好的表示能力。最后,我们的层次双线性模型结合多个跨层双线性模块生成更精细的部分描述,以便更好地细粒度识别。
分解双线性池已被应用于视觉问题回答任务,Kim等人[11]提出了使用哈达玛乘积分解双线性池的多模态学习的有效注意机制。本文介绍了用于细粒度图像识别的分解双线性池技术的基本公式。假设一个图像I被CNN过滤了卷积层的输出特征图为X Rh w c,高h,宽w,通道c,我们将X上空间位置的c维描述符表示为X = [x1, x2,···,xc]T。
其中,Wi 为投影矩阵,Zi为双线性模型的输出。我们需要学习W = [W1,W2,···,Wo] ,得到一个o维输出z,根据[24]中的矩阵分解,Eq.(1)中的投影矩阵Wi可以分解成两个单秩向量
where Ui ∈ Rc and Vi ∈ Rc. Thus the output feature z ∈ Ro is given by
其中U Rc d和V Rc d是投影矩阵,P Rd o是类化矩阵,o是哈达玛积,d是决定节理嵌入维数的超参数。
细粒度的子类别往往具有相似的外观,只能通过局部属性的细微差异来区分,例如鸟类的颜色、形状或喙长。双线性池是一种重要的细粒度识别技术。然而,大多数双线性模型只关注于从单个卷积层学习特征,而完全忽略了信息的跨层交互作用。 单个卷积层的激活是不完全的,因为每个对象部分都有多个属性,这些属性对于区分子类别至关重要 。
实际上在大多数情况下,我们需要同时考虑零件特征的多因素来确定给定图像的类别。因此, 为了捕获更细粒度的部分特征,我们开发了一个跨层的双线性池方法,该方法将CNN中的每个卷积层视为部分属性提取器。 然后将不同卷积层的特征通过元素乘的方式进行集成,建立部分属性的层间交互模型。根据公式(3)可以改写为:
3.2节提出的跨层双线性池是直观有效的,在不增加训练参数的情况下,其表示能力优于传统的双线性池模型。这启发我们,利用不同卷积层之间的层间特征相互作用,有利于捕获细粒度亚层之间的鉴别部分属性。因此,我们扩展了跨层的双线性池来集成更多的中间卷积层,进一步增强了特征的表示速度。在这一节, 我们提出一个广义的分层双线性模型,通过层叠多个跨层的双线性池模块来合并更多的卷积层特性。 具体地,我们将跨层的双线性池模块划分为交互阶段和分类阶段,公式如下:
其中P为分类矩阵,U, V, S,…为卷积层特征向量x, y, z的投影矩阵,…分别。HBP框架的总体流程图如图1所示。
在本节中,我们将评估HBP模型在细粒度记录方面的性能。第4.1节首先介绍了HBP的数据集和实现细节。在第4.2节中进行了模型配置研究,以调查每个组件的有效性。与最新方法的比较载于第4.3节。最后,在4.4节中,定性可视化被用来直观地解释我们的模型。
数据集:cub200-2011【30】,StandFordcars【15】,FGVC-Aircraft【21】
实验:使用ImageNet分类数据集预训练的VGG-16基线模型评估HBP,删除最后三个全连接层,也可以应用到Inception和ResNet中,输入图像大小448。我们的数据扩充遵循常用的做法,即训练时采用随机抽样(从512 S中裁剪448 448,其中S为最大的图像边)和水平翻转,推理时只进行中心裁剪。我们先通过logistic回归对分类器进行训练,然后使用批量为16,动量为0.9,权值衰减为5 10 4,学习率为10 3的随机梯度下降法对整个网络进行微调,并定期进行0.5的退火。
跨层双线性池(CBP)有一个用户定义的投影维d。为了研究d的影响并验证所提框架的有效性,我们在cub200 -2011[30]数据集上进行了大量的实验,结果如图2所示。注意,我们利用FBP中的relu5 3、CBP中的relu5 2和relu5 3、HBP中的relu5 1、relu5 2和relu5 3得到了图2中的结果,我们还提供了以下图层选择的定量实验。在VGG-16[27]中,我们主要关注relu5 1、relu5 2和relu5 3,因为它们比较浅的层包含更多的部分语义信息。在图2中,我们将CBP的性能与一般分解的双线性池模型(即FBP)进行了比较。在此基础上,我们进一步探索了多层结合的HBP方法。最后,我们分析了超参数d的影响因素。从图2中我们可以得出以下重要结论:
首先,在相同的d下,我们的CBP明显优于FBP,这说明特征的层间相互作用可以增强识别能力。
其次,HBP进一步优于CBP,证明了中间卷积层激活对细粒度识别的有效性。这可以通过CNNs在传播过程中存在信息丢失来解释,因此在中间卷积层中可能丢失对细粒度识别至关重要的鉴别特征。与CBP相比,我们的HBP将更多的中间卷积层的特征相互作用考虑在内,因此具有更强的鲁棒性,因为HBP表现出了最好的性能。在接下来的实验中,HBP被用来与其他最先进的方法进行比较。
第三,当d从512到8192变化时,增加d可以提高所有模型的精度,HBP被d = 8192饱和。因此,d = 8192
然后,我们在cub200 -2011[30]数据集上提供定量实验来分析层的影响因素。表2的精度是在相同的嵌入维数下得到的(d = 8192)。我们考虑了CBP和HBP的不同层的组合。结果表明,该框架的性能增益主要来自层间交互和多层组合。由于HBP-3已经表现出了最好的性能,因此我们在4.3节的所有实验中都使用了relu5 1、relu5 2和relu5 3。
我们也比较了我们的跨层集成与基于超列[3]的有限元融合。为了进行公平的比较,我们将超列重新实现为relu5 3和relu5 2的特征连接,然后在相同的实验设置下进行分解双线性池(记作HyperBP)。从表3可以看出,我们的CBP得到的结果略好于拥有近1/2 pa- rameter的HyperBP,这再次表明我们的集成框架在捕获层间特征关系方面更有效。这并不奇怪,因为我们的CBP在某种程度上与人类的感知是一致的。与HyperBP算法相反,当对更多的卷积层激活[3]进行积分时,得到的结果更差,我们的HBP算法能够捕获中间卷积层中的互补信息,在识别精度上有明显的提高。
结果cub- 200 - 2011。CUB数据集提供了边界框和鸟类部分的地面真相注释。我们使用的唯一监督信息是图像级类标签。cub200 -2011的分类精度如表4所示。表按行分为三部分:第一部分总结了基于注释的方法(使用对象包围框或部分注释);第二种是无监督的基于零件的方法;最后给出了基于池的方法的结果。
从表4的结果中,我们可以看到PN-CNN[2]使用了人类定义的边界框和地面真实部分的强大超视觉。SPDA- CNN[35]使用ground truth parts, B-CNN[17]使用具有非常高维特征表示(250K维)的边界框。与PN- CNN[2]、SPDA-CNN[35]和B-CNN[17]相比,即使不考虑bbox和部分干扰,所提出的HBP(relu5 3 + relu5 2 + relu5 1)也能取得较好的效果,证明了我们模型的有效性。与STN[9],使用更强的初始网络作为基准模型,得到一个相对ac -助理牧师的身份获得3.6%的家庭血压(relu5 3 + relu5 2 + relu5 1)。我们甚至超越RA-CNN[5]和MA-CNN[37],最近提议最先进的无监督部分原因的方法,相对精度,分别为2.1%和0.7%。与基于pool的B-CNN[17]、CBP[6]、LRBP[12]基线相比,我们主要受益的是较好的结果特征的层间交互和多层的集成。我们还超过了BoostCNN[22],它可以增强在多个尺度上训练的多个双线性网络。虽然HIHCA[3]提出了类似于用于细粒度识别的特征交互模型的思想,但是由于层间特征交互和鉴别特征学习的相互增强框架,我们的模型可以达到更高的精度。注意,HBP(relu5 3+relu5 2+relu5 1)表现优于CBP(relu5 3+relu5 2)和FBP(relu5 3),说明我们的模型能够捕捉到各层之间的互补信息。
斯坦福汽车的结果。Stanford Cars的分类精度如表5所示。不同的汽车零部件是有区别的、互补的,因此在这里,客体和零部件的国产化可能起着重要的作用。虽然我们的HBP没有显式的零件检测,但是在目前最先进的检测方法中,我们的检测结果是最好的。基于层间特征交互学习,我们甚至比PA-CNN[13]提高了1.2%的相对精度,这是使用人工定义的边界框。与无监督的基于零件的方法相比,我们可以观察到明显的改善。我们的HBP也优于基于池的方法BoostCNN[22]和KP[4]。
结果FGVC-Aircraft。由于细微的差异,不同的飞机模型很难被识别,例如,可以通过计算模型中的窗口数来区分它们。表6总结了fgvc飞机的分类精度。尽管如此,我们的模型仍然达到了最高水平所有方法中分类精度最高。与基于注释的MDTP[32]方法、基于部分学习的MA-CNN[37]方法和基于池的BoostCNN[22]方法相比,我们可以观察到稳定的改进,这突出了所提出的HBP模型的有效性和鲁棒性。
为了更好地理解我们的模型,我们在不同的数据集上可视化微调网络中不同层的模型响应。我们通过计算特征激活的平均幅度来得到激活图通道。在图3中,我们从三个不同的数据集中随机选取了一些图像,并将其可视化。
所有的可视化结果都表明,所提出的模型能够识别杂乱的背景,并倾向于在高度特定的场景中强烈地激活。项目1、项目2、项目3中突出的激活区域与幼仔头部、翅膀、胸部等语义部分密切相关;汽车前保险杠、车轮和车灯;飞机座舱、尾翼稳定装置和发动机。这些部分是区分类别的关键。更重要的是,我们的模型与人类感知高度一致,在感知场景或物体时解决细节问题。从图3可以看出,反褶积层(relu5 1, relu5 2, relu5 3)提供了目标对象的粗略定位。在此基础上,投影层(project5 1、project5 2、project5 3)进一步确定物体的本质部分,通过连续的交互和不同部分特征的整合来区分其类别。过程符合人类感知的而且性质[20]受完形格言:整个前部分,它还提供了一个直观的解释为什么我们的框架模型的分类不明确的部分检测和地方差异。
本文提出了一种分层的双线性池化方法,将层间交互和鉴别特征学习相结合,实现了多层特征的细粒度融合。提出的网络不需要边界框/部件注释,可以端到端的训练。在鸟类、汽车和飞机上的大量实验证明了我们的框架的有效性。未来,我们将在两个方向展开拓展研究。,如何有效地融合更多的层特性来获得多尺度的零件表示,以及如何合并有效的零件本地化方法来学习更好的细粒度表示。
论文阅读笔记:Hire-MLP Vision MLP via Hierarchical Rearrangement
论文阅读笔记(五):Hire-MLP: Vision MLP via Hierarchical Rearrangement
摘要
先前的MLPs网络接受flattened 图像patches作为输入,使得他们对于不同的输入大小缺乏灵活性,并且难以捕捉空间信息,本问Hire-MLP通过层次化重排构建视觉MLP架构,包含两个层次的重排。其中,区域内重排是为了捕获空间区域内的局部信息,跨区域重排是为了实现不同区域之间的信息通信,并通过沿空间方向循环移动所有标记来捕获全局上下文。大量的实验证明了Hire-MLP作为多种视觉任务的通用骨干的有效性。特别是,Hire-MLP在图像分类、目标检测和语义分割任务上取得了具有竞争力的结果,例如,在ImageNet上的top1精度为83.8%,在COCO val2017上的框AP和掩模AP分别为51.7%和44.8%,在ADE20K上的mIoU为49.9%,超越了之前基于变压器和基于mlp的模型,在精度和吞吐量方面有更好的交换
引入
- 动机
- 由于transformer的自注意模块所带来的沉重的计算负担,使得模型无法更好地兼顾准确性和延迟。
- MLP-Mixer通过应用于每个图像补丁的mlp提取每个位置的信息,并通过应用于多个图像补丁的mlp捕获远程信息。但有两个棘手的缺陷阻止该模型成为视觉任务的更一般的骨干:
- patch的数量随着输入大小的变化而变化,使得其不能直接使用预训练并在其他分辨率上直接微调,这使得MLP-Mixer无法被转移到检测和分割等下游视觉任务中。
- MLP-Mixer很少研究局部信息,这在cnn和基于变压器的架构中都被证明是一个有用的归纳偏置
- 主要贡献
结论
本文提出了一种基于mlp架构的新变体,通过分层重新排列token来聚合局部和全局空间信息。输入特征首先沿着高度/宽度方向被分割成多个区域。通过内部区域重排操作,使每个区域的不同token能够充分通信,将不同token的通道混合,提取局部信息。然后通过token移位来重新排列来自不同区域的token。这种跨区域重排操作不仅交换了区域之间的信息,而且保持了相对位置。Hire-MLP基于上述操作构建,并在各种视觉任务中取得了显著的性能改进。
网络结构
Hierarchical Rearrangement Module
由于全连通层的尺寸是固定的,因此在对象检测、语义分割等密集的预测任务中,它不兼容长度可变的序列。此外,每个token混合操作都捕获和聚合全局信息,而一些关键的局部信息可能会被忽略。hIre模块的内部区域重排操作可以捕获预定义区域内tokoen的局部信息,而跨区域重排的操作可以捕获全局信息。由于提出的区域划分,在不同大小的输入条件下,每个区域的大小保持不变。因此,我们的hire模块可以自然地处理可变长度的序列,并具有相对于输入大小的线性计算复杂度。

- Region Partition
首先将输入特征划分为多个区域,该特征可以沿着宽度和高度方向进行分割。
-
Inner-region Rearrangement
给定一个输入特征\\(X_i \\in R^h \\times W \\times C\\),它是沿着高度方向的第i个区域,我们将\\(X_i\\)中的所有token沿通道维数进行concat,得到形状为\\(W \\times hC\\)的重排特征\\(X_i^c\\),随后被输入到一个MLP模块中用于融合最后一个维度的信息,得到输出特征\\(X_i^o\\),这里的MLP模块是由两个带有瓶颈的线性投影实现的(投影的“瓶颈”是指压缩到的低维空间的维度远远小于输入数据的维度,这样可以强制模型学习输入数据的主要特征,而忽略一些次要特征,从而提高模型的泛化能力)最后,将输出特征\\(X_i^o\\)恢复到下一个模块的原始形状,即沿着最后一个维度将其分解为多个令牌,得到特征\\(X_i^\'\\in R^h\\times W \\times C\\)
-
Cross-region Rearrangement
跨区域重排是通过在给定步长s的特定方向上递归地移动所有标记来实现的,如图2(c) (s = 1沿高度方向)和图2(d) (s = 1沿宽度方向)所示。移位后,被区域分割的局部区域中包含的令牌会发生变化。这个操作可以通过Pytorch/Tensorflow中的“圆形填充”轻松完成。为了获得全局接收域,每两个块在内部区域重排操作之前插入跨区域重排操作。在进行内部区域恢复操作后,对移位的标记进行位置恢复,以保持不同标记之间的相对位置。而这种恢复可以进一步提高我们的HireMLP的准确性。我们提出的跨区域重排保留了不同标记之间的相对位置。我们认为,相对位置是实现高表现能力的关键。
-
Hire Module
考虑尺寸为H×W×C的输入特征X,空间信息通信在两个分支中进行,即沿着高度方向和宽度方向。受ResNet和ViP中残差连接的启发,还增加了一个没有空间通信的额外分支,其中只有一个完全连接的层被用来沿着通道维度编码信息。将输入X发送到上述三个分支,分别得到特征\\(X_W^\'\\), \\(X_H^\'\\), \\(X_C^\'\\)。将这些特征相加得到输出特征\\(X^\'\\),即\\(X^\'\\)= \\(X_W^\'\\),+\\(X_H^\'\\)+\\(X_C^\'\\)
-
复杂度分析
在Hire Module中,全连接层层占用了主要的内存和计算开销。考虑图1中的高度方向分支,给定一个输入特征\\(X \\in R^h \\times W \\times C\\),,我们首先将其分割成形状为h×W×C的H/h区域。内部区域重排后的特征形状为H/h×W×hC。我们经验地将瓶颈中的通道维数设置为C/2,因此该支路占用hC × c/2 × 2 = hC^2参数和H H ×W × hC × c^2 × 2 = HWC^2 FLOPs。
-
总体架构
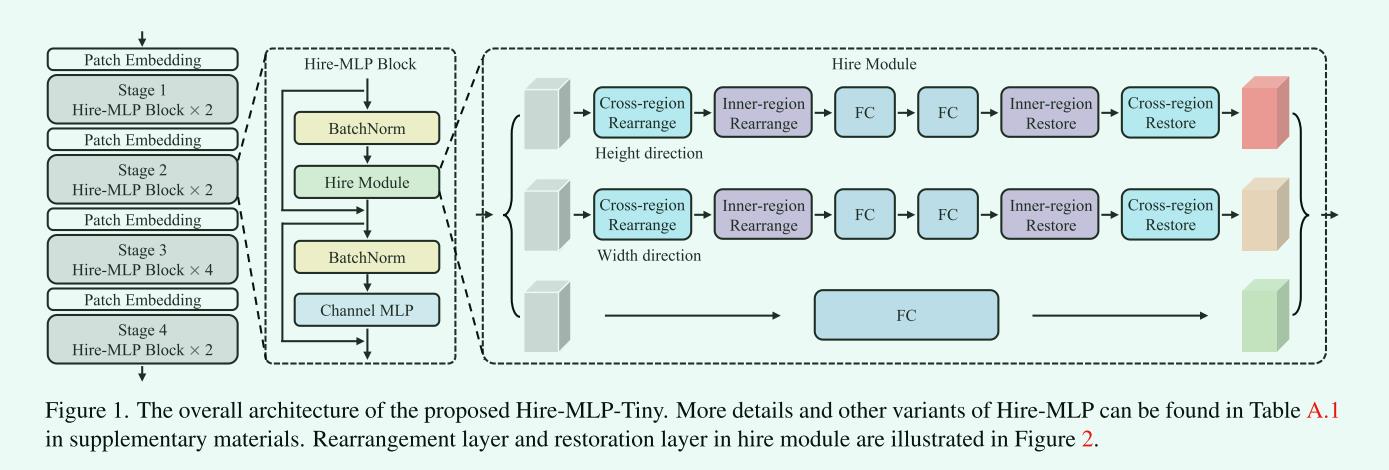
它首先通过patch嵌入层将输入图像分割为patch (token)。然后两个Hire-MLP块被称应用于上面的tokens。随着网络深度的增加,token数量减少,同时输出通道增加一倍。特别是整个体系结构包含四个阶段,特征分辨率从h/4 × w/4降低到h/32 × w/32,输出维数相应增加。金字塔结构将空间特征聚集起来提取语义信息。
实验
- ImageNet上的图像分类
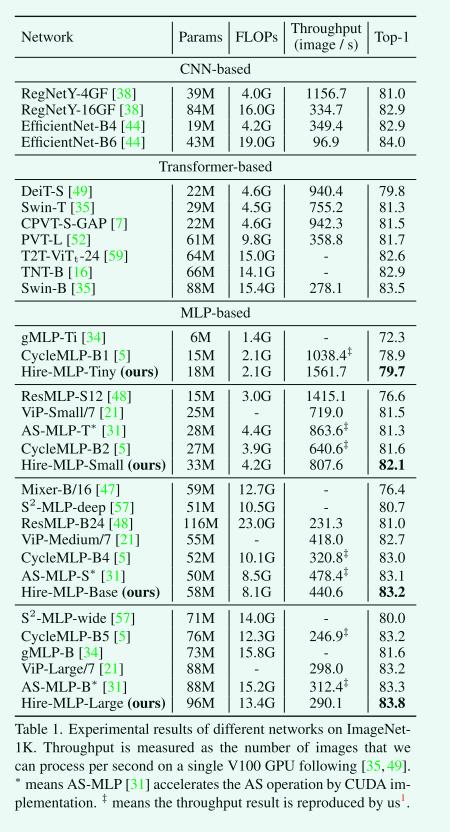
所提出的Hire-MLP模型在图像分类任务中表现优秀,与基于CNN、Transformer和MLP的模型相比具有最先进的性能。Hire-MLP-Small模型仅使用4.2G FLOPs就实现了82.1%的top-1精度,优于所有现有的基于MLP的模型。将模型扩展到8.1G和13.1G时,top-1准确率分别达到83.2%和83.8%。 Hire模块可以更好地捕获本地和全局信息,这比基于CNN的模型获得了更好的结果,并且比基于Transformer的模型具有更快的推理速度。然而,我们的模型与最先进的EfficientNet-B6之间仍然存在一定差距。MLP-based体系结构具有简单性和更快的推理速度等独特优点,并且未来可以进一步增强模型。
-
消融实验
Hire-MLP中的核心组件是hierarchical rearrangement模块,我们对区域划分中每个区域的token数量、跨区域的移动区域数量和不同的重排方式、内区域重排的填充模式以及租用模块中的FC层数进行了消融研究。
-
区域分区中每个区域的token数
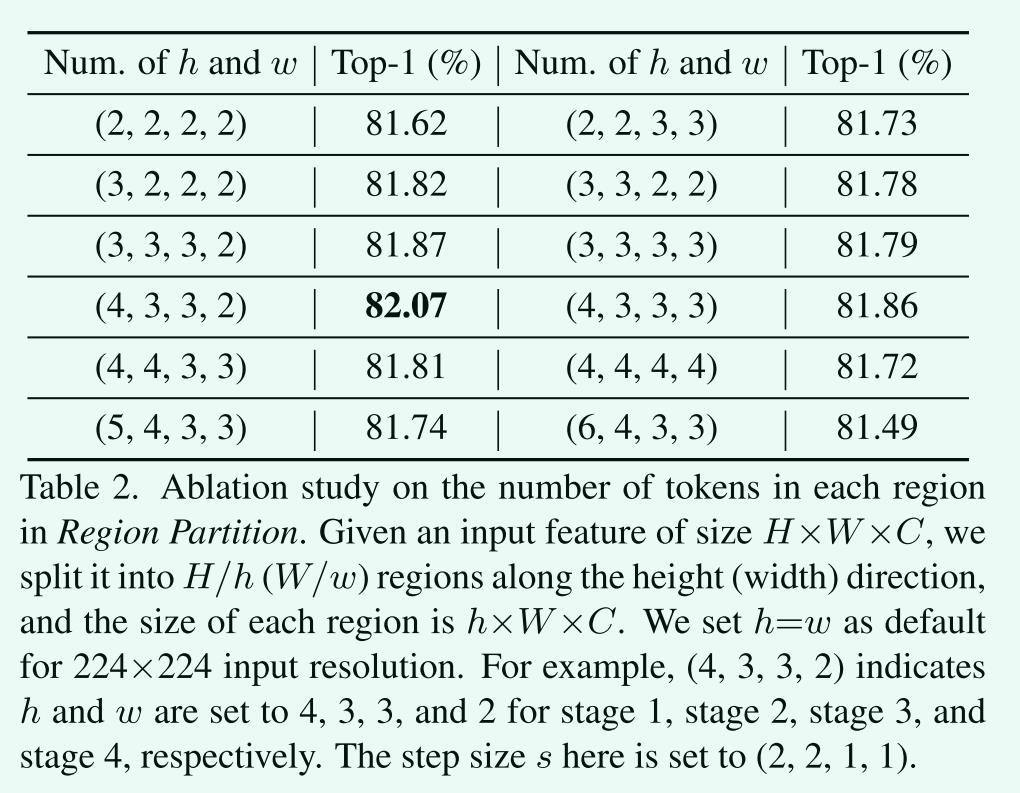
区域大小越小,意味着通过内部区域重排操作混合的相邻token越少,更注重局部信息。我们的经验发现,在较低的层次上,需要更大的区域大小来处理带有更多token的特征图,并获得更大的接受域。当区域大小进一步增大时,性能会略有下降。我们推测随着区域大小的增加,瓶颈结构中可能存在一些信息丢失。
-
跨区域重排中移位token的步长s。

token不移位时,即s =(0,0,0,0),不同区域之间不存在通信(不存在跨区域重排操作)。显然,全局信息的缺乏导致表现下降。
-
不同填充方法的影响

-
Hire模块中不同组件的影响。
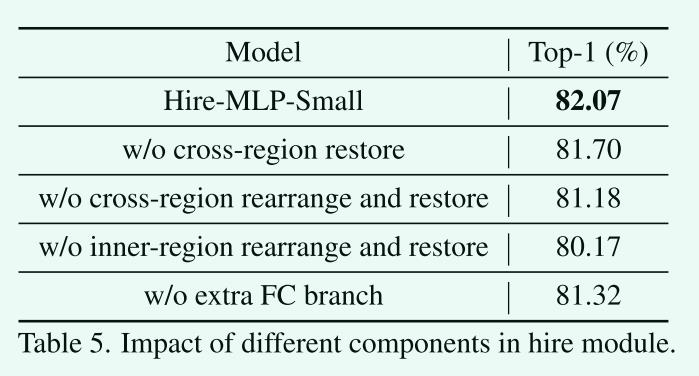
我们可以发现,区域内部的重排是捕获局部信息的最重要的组成部分。跨区域恢复操作可使top-1精度提高0.3%。如果我们放弃跨区域的重排(包括恢复),模型将无法跨区域交换信息,性能将下降到81.18%。去掉图1中的第三个分支将会使前1位的准确率降低0.7%。
-
不同的跨区域信息交流策略

与传统的ShuffleNet方法相比,该方法具有更好的效果,说明该方法可以为模型保留更多的相对位置信息。
-
Hire 模块FC层数
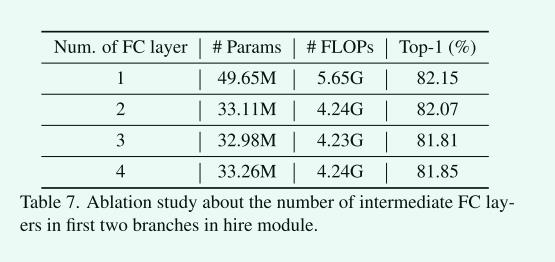
Hire模块中MLP的瓶颈设计有助于消除通道数增加带来的FLOPs的增加。虽然使用一个FC层可以获得最好的性能,但参数和FLOPs都比其他FC层大。具有两个FC层的瓶颈可以在准确性和计算成本之间获得更好的权衡。此外,增加更多的FC层并不能带来更多的好处,说明这种改进来自于我们的分层重排操作,而不是增加FC层的数量。
-
-
COCO数据集上的目标检测和实例分割
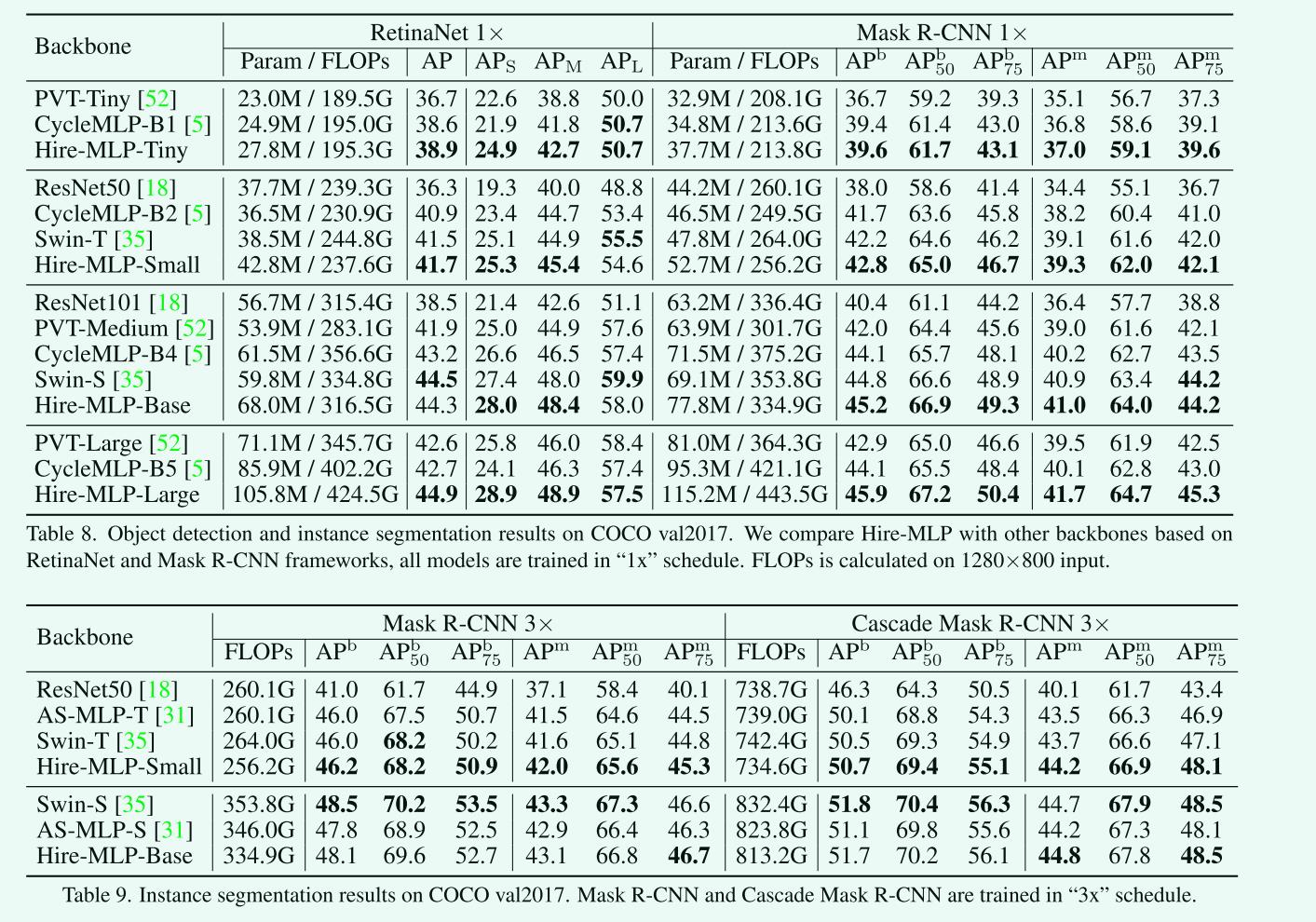
-
ADE20K数据集上的语义分割
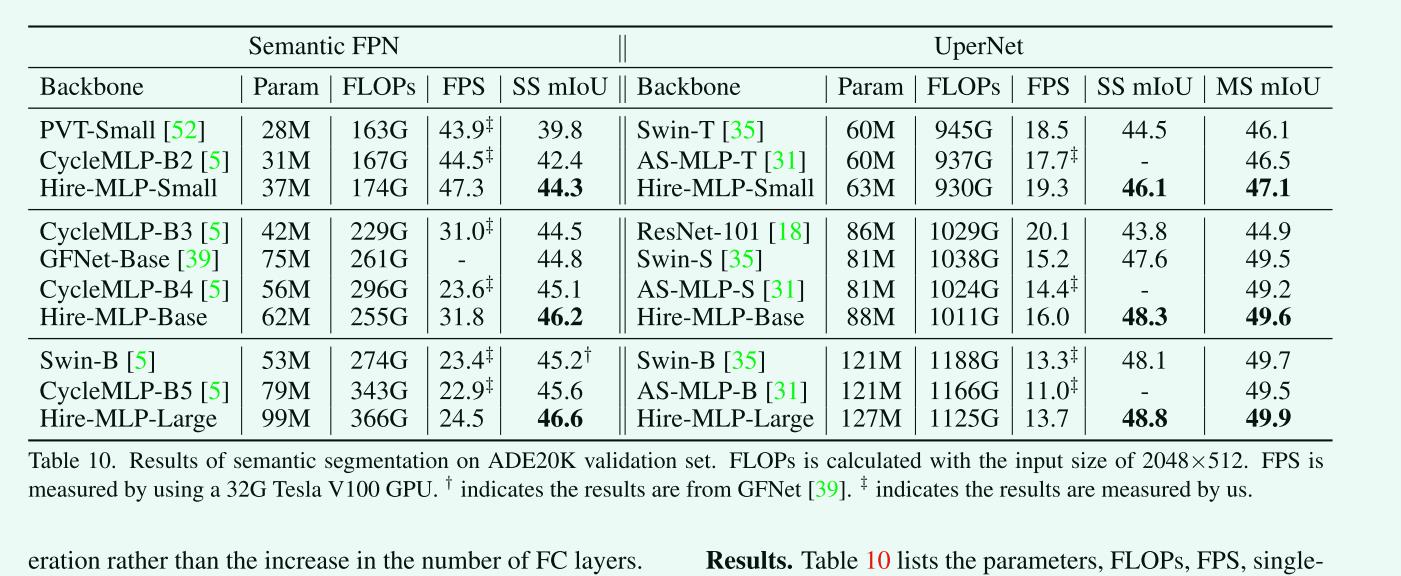
以上是关于论文:Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition的主要内容,如果未能解决你的问题,请参考以下文章
论文代码解读 Hierarchical Reinforcement Learning for Scarce Medical Resource Allocation
论文笔记 Hierarchical Reinforcement Learning for Scarce Medical Resource Allocation
[论文阅读笔记] HARP Hierarchical Representation Learning for Networks
论文笔记之: Hierarchical Convolutional Features for Visual Tracking
论文阅读-Hierarchical Cross-Modal Talking Face Generation with Dynamic Pixel-Wise Loss
论文阅读Learning Effective Road Network Representation with Hierarchical Graph Neural Networks