C++ 这句话中的“*”代表啥意思?如何理解这句话
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++ 这句话中的“*”代表啥意思?如何理解这句话相关的知识,希望对你有一定的参考价值。
//Date 是一个类,在这里就不拿出来了。
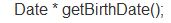
此函数 函数名是getBirthDate ,形参列表是空(void) 参考技术A 这句话是声明一个函数,
函数名getBirthDate,返回值Date*,参数列表void
Date*就是Date类对象的指针啊 参考技术B 指针。C++的一个类型 指针类型 参考技术C 代表指针,对象的指针
20210611 word2vec 理论介绍
一、我们如何理解文本

首先分词,通过对一个一个词的理解,在通过一些句法规则或者语法理解这句话;句法规则或者语法可以通过网络框架进行建模,构造一个语言模型;知道每个词的意思后,通过语言模型理解这句话的意思;最基础的任务是,如何理解词意?最简单的理解方式是,给每个词一个唯一的索引,进行一一映射;有了映射后,可以拿这些映射代表这些词,使用这些映射进行统计学的理解分析,也可以对词意进行理解
二、one-hot 表示
1. 语料
我们都生活在阴沟里,但仍有人仰望星空。
每个圣人都有过去,每个罪人都有未来。
one-hot 就是把索引展开,用 0 1 的方式表示;对文本进行表示时,首先需要语料库,拿到语料后,首先对语料进行分词
2. 分词
[我们, 都, 生活, 在, 阴沟, 里, 但, 仍有, 人, 仰望, 星空]
[每个, 圣人, 都有, 过去, 每个, 罪人, 都有, 未来]
分词后,对每个词进行一一映射关系;并且要把重复的词进行去重,对去重后的每一个词进行索引的编码

最简单的 0 1 表示,下表 就是对应位置的索引

one-hot 的表现形式,其实就是二进制的表现形式;这个映射表可以称之为词袋;one-hot 的长度就是词袋的长度,有了对每个词的表示后,如何理解句子呢?一般会用词袋模型表达对句子的理解
三、词袋模型 (Bag of Words)

每个词都可以用 one-hot 的表现形式表示;这句话的表现形式,用count 统计,纵向相加;得出来的结果就是词袋模型,词袋模型的长度和词典的长度是同长的,如果这个词出现了,这个词所对应的索引的下标就不是0,因为表示的是次数,词袋模型可以统计当前话里面出现了多少词以及词出现的词数;但是缺点是会忽略词的顺序关系,也无法表现出每个词的重要程度,当然这只是一种基础的文本表示,可以用模型来关注;为了解决词袋模型 维度过高 和 无法表达词语的语义信息 这 2 个缺点,引入 word2vec
四、word2vec
了解一个词,通过周边环境了解一个词,也就是通过上下文了解;很像中学时,完形填空英语题
1 NNLM

NNLM 是使用神经网络搭建的网络模型,这也是word2vec的基础;输入是一个词的前 n 个词(当然不是词本身,而是序号的表示),输出是当前词;将 one-hot表示映射到固定大小的矩阵空间来表示一个词;通过词的拼接或者相加等方式获得一个总向量;总向量通过 DNN 神经网络,也就是多层感知机;输出层是 Softmax,Softmax用于实现多分类,类似于 sigmoid,sigmoid 是做二分类,输出值是 0 和 1 之间;而 Softmax 是用来实现多分类的,最后也会输出一串概率值,只是这些概率值的和相加为 1;假设有 5000 个单词,Softmax会对结果进行 5000 分类,最后会判断是属于 哪个类别,这是输出 NNLM 当时无法支持这种体量的计算,尤其是Softmax分类,计算的复杂度较高,所以当时虽然有了这样比较好的理论,但是业内没有起到比较好的效果
2 word2vec——基础架构
有了前面的使用深度神经网络实现 NLP 的基础后,后边就有了 word2vec;word2vec 的目的是获取一个词的稀疏的词向量表示;word2vec是在2014年开源的一个工具包;架构和 NNLM 是比较像的,只是 NNLM 是输入前 n-1 个词,预测第 n 个词;而 word2vec 是输入周边词,预测中心词;或者输入中心词,预测周边词

以 Skip-gram 为例

虽然是在训练语言模型,但是想要的是每一个词的向量表示
3 word2vec——实现过程

窗口是3,就是 Skip-gram 的output 是 3 个,中心词前面取 3 个,后面 取 3 个;假设 女王 是中心词,前面只有 英国,中心词后取 3 个,就是 和 瑞典 国王;这就变成了 模型的 输入 与 输出;输入 女王,或者 是 女王的 one-hot 表现形式,输出是 女王的周边词;输入女王后,中间的 layers 是DNN的运算,有了DNN的运算后,会输出一个结果,词袋有多大,这个输出结果就有多大;然后通过 softmax 拿出词袋中所有词的预测输出,假设通过 softmax 后,都变成概率值,对应标签的概率是最高的;标签和 预测输出做交叉熵,然后会得到一个 loss 值,通过 loss 值计算梯度,然后通过梯度下降改变权重值,我们的本质不是训练一个好的语言模型,本质是取模型固定的向量表示,固定的向量表示在哪里呢?

输入是 one-hot 表现形式,假设词袋中有10000个词,一万个词x(10000,300),10000行,300列,300代表固定长度;认为得到的 300 就是当前词的 word2vec 值,然后计算周边词的概率,所以用300x(300,10000),映射到 10000 维,然后套一个 softmax,相当于计算概率,这也是一个前向过程;输入一个词,进行线性的矩阵运算,得到一个 300 维,对 300 维再次进行矩阵运算,得到一个 10000 维,然后10000维套一个softmax 得到预测输出,这里是线性的,只有结果端进行分类时,才套一个 softmax; 300是当前词的 word2vec 值;现在把矩阵运算的细节再次细化;左侧下面的 [10000,300]权重 就是要训练的 word2vec 值]

中间的(10000,300)矩阵就是当前所有词的word2vec的矩阵集合

然后通过得到的这个值,乘以(300,10000)矩阵,可以理解为这个词去寻找周边关系了,找到周边关系后,通过softmax 变成概率值

这个矩阵,就是所有词,比如 10000 个词的 word2vec 的矩阵集合;位置(0,300) “我们”映射是 0,下面那一行的权重,就是“我们”的 word2vec 值,“天气”下标是 9,下面的 word2vec 值 就是“天气”的 word2vec 值
4 但是存在一个问题

计算softmax的地方和NNLM遇到的问题是一样的;计算 softmax 的前向过程的计算复杂度很高;计算反向过程修改权重时的计算复杂度也非常高,非常耗时,而且浪费算力;在2003年时,这种运算方式很不现实,现在虽然能够 训练了,但是由于 word2vec 在计算语言模型的过程中,是一种无监督的计算,输入一个词的周边词,然后 预测当前词,或者输入当前词预测周边词;海量的运算复杂度很高
word2vec的第二篇论文,如何训练,主要贡献是 分层次 softmax 和 负采样

修改了 softmax 的公式,将计算概率的过程用树模型代替;这样计算复杂度会大大降低

softmax 每次计算,只有 一个词是周边词,其他词都是 0;因为只有一个 1 ,那么是否 可以转化成 二分类 负采样 问题?只有某几个词是对的,只把对的拿出来,然后采样几个错的,进行几个二分类;把 n 分类的过程,转变成 几个 二分类的过程;具体做法其实是在 loss 里做了更改;前向过程,计算一个语言模型,取出中间的结果/矩阵作为 word2vec 的值,语言模型的计算过程中 softmax 不是很好计算,使用特殊的训练方法使它可以快捷训练,这样就可以计算出 word2vec 的值了
5 效果示例
每个 word2vec 值是一个稠密矩阵,假定 word2vec 的值是 300,就会输出 300 个数值 代表这个词;300数值的每个下标,都可能代表一种特征;比如 下标 0 代表 皇族气质 等等;国王-男子气概+女子气质 = 女王;向量空间是 可以这样计算的

6 优缺点
优点:1. 低维;
2. 可以表达词语的语义信息
缺点:1. 语义角度来看,无法解决单词的歧义问题,比如:小米,在不同场景有不同意思
2. OOV问题;未登录词问题,训练的词中如果没有这个词,是一定没有办法拿出这个词的 word2vec 值的
以上是关于C++ 这句话中的“*”代表啥意思?如何理解这句话的主要内容,如果未能解决你的问题,请参考以下文章