sql两张表(主表和字典表)关联查询,字典项翻译问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql两张表(主表和字典表)关联查询,字典项翻译问题相关的知识,希望对你有一定的参考价值。
现在有两张表 jbxxb和department表 ,其中jbxxb的有单位代码字段dw(类似01110000)。另一张是单位代码的字典,有code和name,name就是代码对应的中文名字,比如山东青岛2分店,code对应的是jbxxb中的dw。我如何查询出来时让code后紧跟着他的中文名字呢,这样结果更直观。我试着用select t.dw,t1.name from jbxxb t,department t1 where t.dw=t1.code.
但是这样有很多重复项,这个我就搞不懂了。。。。也想过用distinct。但是我就是搞不懂为什么有那么多的重复项,怎么让他们不重复?一对一的。
更特殊的是,这一个表中分别有下发单位和接受单位,同时翻译,怎么操作呢
谢谢啦!!!!!!
left join department t1 on t.dw=t1.code 参考技术B 重复项的原因是不是因为jbxxb中某些记录的dw本来就是一样的,这样查询出来就会有多条一样的记录了。本回答被提问者采纳
Sharding-Jdbc概念与使用技巧
1. Sharding-Jdbc概念与使用技巧
此讲解版本为
4.0.0-RC1,目前最新的版本 2019年5月21日发布
1.1. 绑定表
- 指分片规则一致的主表和子表。例如:
t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);- 在不配置绑定表关系时,假设分片键
order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);- 在配置绑定表关系后,路由的SQL应该为2条:、
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);- 其中
t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
1.2. 分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
1.3. 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
- 标准分片策略
- 复合分片策略
- 行表达式分片策略
对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->u_id % 8 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
- Hint分片策略
- 不分片策略
1.4. SQL Hint
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
1.5. SQL支持与不支持
- 看这里
1.6. 行表达式
- $begin..end表示范围区间
- $[unit1, unit2, unit_x]表示枚举值
- 行表达式中如果出现连续多个$ expression 或$-> expression 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
$['online', 'offline']_table$1..3最终解析为
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table31.7. 强制分片路由
通过解析SQL语句提取分片键列与值并进行分片是ShardingSphere对SQL零侵入的实现方式。若SQL语句中没有分片条件,则无法进行分片,需要全路由。
在一些应用场景中,分片条件并不存在于SQL,而存在于外部业务逻辑。因此需要提供一种通过外部指定分片结果的方式,在ShardingSphere中叫做Hint。
ShardingSphere使用ThreadLocal管理分片键值。可以通过编程的方式向HintManager中添加分片条件,该分片条件仅在当前线程内生效。
指定了强制分片路由的SQL将会无视原有的分片逻辑,直接路由至指定的真实数据节点。
1.8. 读写分离
- 同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。
1.9. 编排治理
- 提供注册中心、配置动态化、数据库熔断禁用、调用链路等治理能力。
1.10. 注意事项
- 分页偏移量过大会使数据库获取数据性能低下,原因看这里
1.11. 自定义扩展接口
1.11.1. 分库分表为例

- 进入入口函数,通过springboot配置的入口核心就是右边的
dataSource方法,它会把shardingProperties配置进去,而shardingProperties的来源就是application.propertes中的配置属性 - 通过自定义算法进行配置如下
####################################
# 分库分表配置
####################################
#actual-data-nodes:真实数据节点,由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$0..1.t_order_$0..1
# 自定义分库分表算法
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.algorithmClassName=com.xxx.shardingjdbc .cusalgo.algorithm.DbShardingAlgorithm
## 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.algorithmClassName=com.xxx .shardingjdbc.cusalgo.algorithm.TableShardingAlgorithm- 找到配合对应的类如下
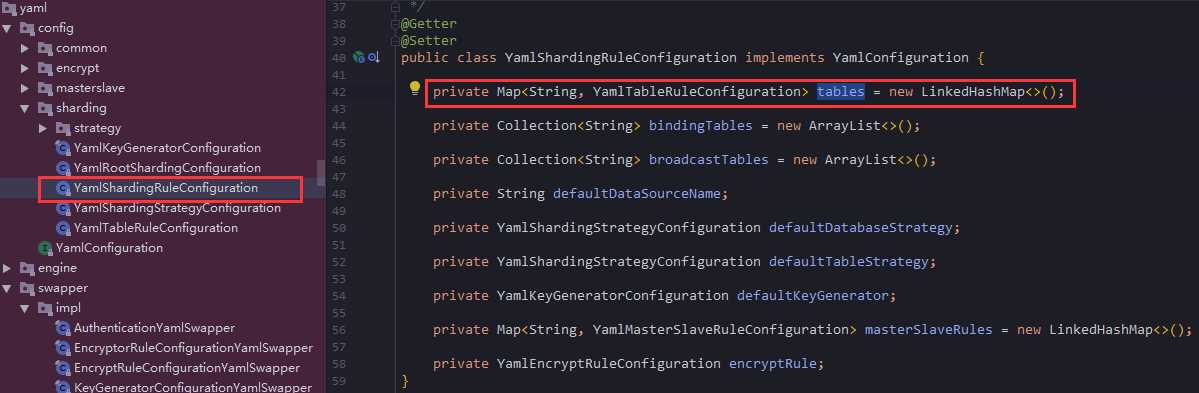
你可以看到除了tables,你还可以配置很多其他属性,
bindingTables,broadcastTables等等,看名字也知道是绑定表和广播表,绑定表我第一章就讲到了,广播表理解也很简单,默认你不分库的就是广播表,也就是数据在所有分库分表的节点都保存一份这里着重讲自定义配置类,上面配置文件配置了
DbShardingAlgorithm这个类就是自定义类,它实现了ComplexKeysShardingAlgorithm
public class DbShardingAlgorithm implements ComplexKeysShardingAlgorithm
private static Logger logger = LoggerFactory.getLogger(DbShardingAlgorithm.class);
// 取模因子
public static final Integer MODE_FACTOR = 1331;
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, Collection<ShardingValue> shardingValues)
List<String> shardingResults = new ArrayList<>();
Long shardingIndex = getIndex(shardingValues) % availableTargetNames.size();
// loop and match datasource
for (String name : availableTargetNames)
// get logic datasource index suffix
String nameSuffix = name.substring(2);
if (nameSuffix.equals(shardingIndex.toString()))
shardingResults.add(name);
break;
logger.info("DataSource sharding index : ", shardingIndex);
return shardingResults;
/**
* get datasource sharding index <p>
* sharding algorithm : shardingIndex = (orderId + userId.hashCode()) % db.size
* @param shardingValues
* @return
*/
private long getIndex(Collection<ShardingValue> shardingValues)
long shardingIndex = 0L;
ListShardingValue<Long> listShardingValue;
List<Long> shardingValue;
for (ShardingValue sVal : shardingValues)
listShardingValue = (ListShardingValue<Long>) sVal;
if ("order_id".equals(listShardingValue.getColumnName()))
shardingValue = (List<Long>) listShardingValue.getValues();
shardingIndex += Math.abs(shardingValue.get(0)) % MODE_FACTOR;
else if ("user_id".equals(listShardingValue.getColumnName()))
shardingValue = (List<Long>) listShardingValue.getValues();
// 这里 % 1313 仅仅只是防止溢出
shardingIndex += Math.abs(shardingValue.get(0).hashCode()) % MODE_FACTOR;
return shardingIndex;
继续追踪进入
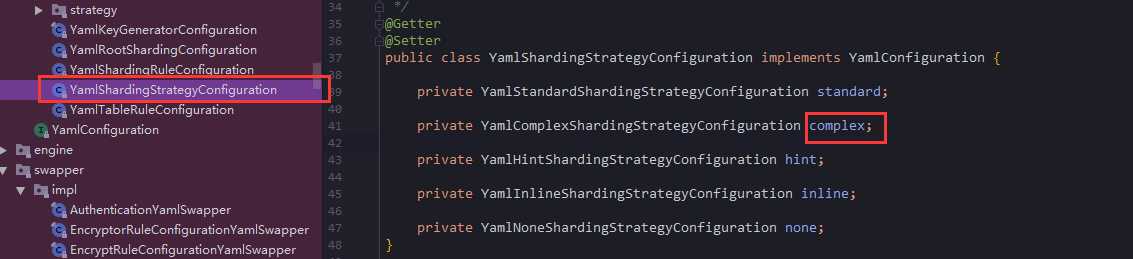
可以发现它总共实现了5个接口配置,上面的ComplexKeysShardingAlgorithm就来自complex的配置

- 至于该实现哪些接口,看下图
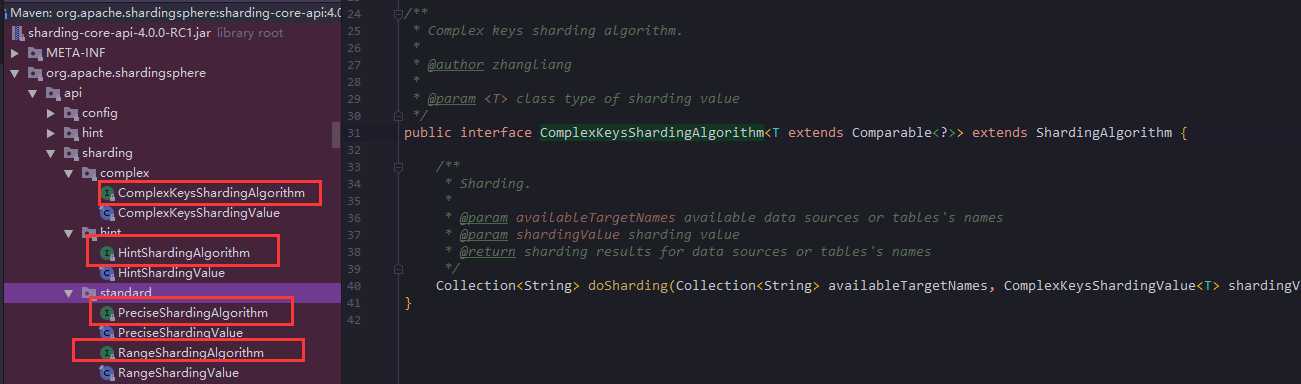
- 上述四个接口,就是我们用户可以自定义实现的接口了,写好实现类把全类名配置上去就可以用了
想要全面了解Sharding-jdbc和它相关组件的,移步这里
以上是关于sql两张表(主表和字典表)关联查询,字典项翻译问题的主要内容,如果未能解决你的问题,请参考以下文章