实例演绎Unix/Linux的"一切皆文件"思想
Posted Linux阅码场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实例演绎Unix/Linux的"一切皆文件"思想相关的知识,希望对你有一定的参考价值。
大家习惯了使用socket来编写网络程序,socket是网络编程事实上的标准。
我们知道,在Unix/Linux系统中“一切皆文件”,socket也被认为是一种文件,socket被表示成文件描述符。
但socket的行为并不很像文件。比如:
无法用 “open一个路径” 的方式打开一个socket,必须用socket系统调用来创建。
文件系统的close可以关闭socket描述符,但优雅关闭TCP socket却需要shutdown。
标准文件系统没有诸如bind,connect,accept,recvfrom等操作。
socket编程繁琐易错,与标准文件操作open/read/write/close等迥异。
如果能像对待标准文件那样对待socket,用read/write读写它,该有多好。本文就来实现这么一个机制来实现UDP socket的数据收发,非常简单,大概160行代码。
在给出代码之前,我们得先理解什么是“一切皆文件”。这一切还要从最开始说起。
“一切皆文件”之始
在Unix原始论文《The UNIX TimeSharing System》中,里奇和汤普森就提出了“一切皆文件”的朴素思想。
“Unix将普通文件和设备通过目录统一在了一个递归的树形结构中。形成了一个统一的命名空间。”
Unix文件系统是一个挂载在ROOT的树形目录结构,每一个目录节点都可以挂载一棵子树。
“一切皆文件”意味着这棵树上可以挂载一切。比如nfs就可以将网络上另外一台主机的文件系统挂载到本机的目录树上,想想看,这棵文件树上的一个文件竟然在另一台机器上,这是多么不可思议。
但这终究只是个理想。
“一切皆文件”之殇
Unix宣称的 “一切皆文件” 并没有完全做到。我们看两个破坏优雅的反例:
奇怪的ioctl
奇怪的BSD socket
“一切皆文件”的背后是一切操作都可以抽象成open,read,write,close。但是ioctl是什么鬼?
有一些行为很难用read和write来定义,比如光盘播放时快进。ioctl的出现弥补了read/write的缺失。但是ioctl有自己的问题:
无法根据一个文件描述符确定ioctl命令列表,只能根据错误码来判断。
ioctl命令和设备紧耦合,重依赖设备类型,控制命令呈暴增趋势。
…
解决这个问题非常简单,为每一个设备增加一个名叫ctrl的文件。将ioctl的调用转换为针对ctrl文件的读写即可。典型的例子参见PCIe设备的配置空间的读写。
总体而言,ioctl增加了文件操作的复杂性。
…
现在说说socket的问题。
虽然socket也是一个文件描述符,它的操作接口和标准文件接口非常不同:
创建socket必须用socket调用而不是open,socket在打开之前不能存在。
bind,connect,accept等都是独立的系统调用,没有标准文件操作与之对应。
…
socket一开始是作为一种封装TCP/IP网络流的IPC机制出现的,而TCP/IP一开始就没有被抽象成文件。下图来自关于socket的wiki:
可见,socket几乎就是为TCP量身定制的接口,和TCP状态机相互对应。换句话说,socket并不是严格意义上的文件。
这意味着很难用统一的方法处理socket的IO流和普通文件的IO流。
Unix “一切皆文件” 退化成了“一切皆文件描述符”:
一切皆文件: 文件属于Unix/Linux目录树,编址于统一命名空间。
一切皆文件描述符: 文件描述符属于进程打开文件表,进程内可见。
同样奇怪的是pipe调用,它创建了一对文件描述符,但也仅仅是文件描述符,而没有被纳入到统一命名空间的Unix/Linux目录树中。
Unix哲学中的“一切皆文件”和其它的原则比如“组合小程序”等是相辅相成的。如果“一切皆文件”被破坏,那么便很难简单串接小程序实现复杂逻辑:
socket没有标准文件的open和close操作,不能cat一个socket,也没法向一个socket里echo数据。
因此就出现了socat,netcat这种大家都说好,但实际上没有必要的微型网络程序。
如果一个网络连接也是一个系统目录树上的文件,便可以如下打开一个连接:
sd = open("/sys/udp/1.1.1.1/53", ...);
sacat,netcat没有必要了,直接在shell上就能完成所有的操作。比如发包可以这么做:
echo aaaaaaa >/sys/udp/1.1.1.1/53
对应收包操作如下:
cat /sys/udp/1.1.1.1/53
你甚至可以这样dup文件描述符:
exec 6<>/sys/udp/1.1.1.1/53
echo aaaaaaa >&6
read -ru6 # cat <&6 将面临EOF问题。
socat,netcat这些微型网络程序实际上就是标准文件IO接口对socket IO接口的封装。
其实,bash shell中,就隐藏着这么一个socket文件的机制: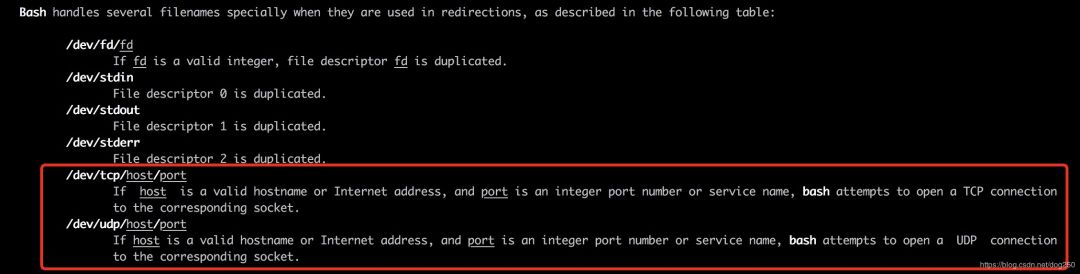
我们可以在bash中如下访问baidu的主页:
bash-3.2$ exec 6<>/dev/tcp/www.baidu.com/80
bash-3.2$ echo 'GET /index.html HTTP/1.1' >&6
bash-3.2$ echo >&6
bash-3.2$ cat <&6
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: Keep-Alive
Content-Length: 14615
Content-Type: text/html
...
是不是连telnet也不需要了呢?嗯,wget,curl都可以消失。
事实上,我们可以用和处理普通文件完全一样的程序来处理socket,理论上只要有cat/read和echo/write两类4个命令就可以了。
遗憾的是, /dev/tcp/www.baidu.com/80 文件并不存在,这只是bash为我们提供的一种善意的假象。
如果你用过socat(可以直接用yum install安装),你会发现更酷的玩法,我们来看一个TCP服务器用socat怎么实现:
[root@localhost ~]# socat tcp-listen:1234,reuseaddr,fork exec:bash,pty,stderr
不用写一行代码。此时从另一个终端,我们便可以用telnet登录这个服务器:
[root@localhost ~]# telnet 127.0.0.1 1234
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
bash: 此 shell 中无任务控制
[root@localhost ~]# pwd
pwd
/root
当然了,你可以同样用socat,这么干:
[root@localhost ~]# socat -,raw,echo=0 tcp:host:1234
…
如果一个连接可以表示成目录树中的一个文件,我们就不需要socat,telnet了,我们只需要cat/read和echo/write等两类命令即可完成所有这一切。
我们可以自己实现这样的机制。
插曲-“一切皆文件”之Plan 9原教旨
写这篇文章的想法源自于我在班车上刷知乎,偶然间看到了Plan 9这个出自汤普森,里奇这帮人之手号称要取代Unix的下一代分布式操作系统(好长的描述)…
Plan 9承诺彻底贯彻执行 一切皆文件。 这将使其有能力对外提供统一的文件系统视图,以实现分布式。
Plan 9是一个真正的分布式系统,它可以将分布在不同位置的所有资源作为文件统一在同一棵目录树中,这便是Unix最初的愿景: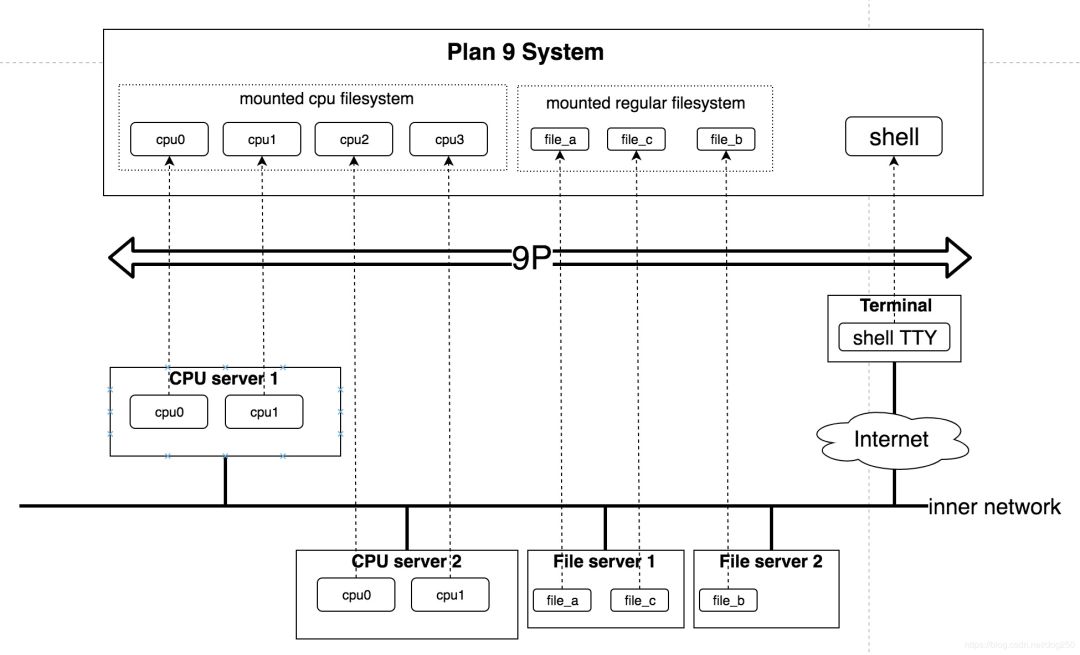
看上图,一台机器上的一个可执行文件可以运行在另一台机器的CPU上,这一切对于用户都是透明的,Plan 9用9P屏蔽了底层的通信细节。之所以能实现这样的效果,全部拜“一切皆文件”所赐。
Plan 9的创举在于,它将分散的计算机的内部硬件组件和软件组件(而不是计算机本身)看成了独立的资源,而不管它们之间是如何连接的:
同一台机器内部的资源通过内部总线连接。
不同机器的资源通过网络连接。
让我们领略一下Plan 9中的“一切皆文件”对于TCP而言意味着什么: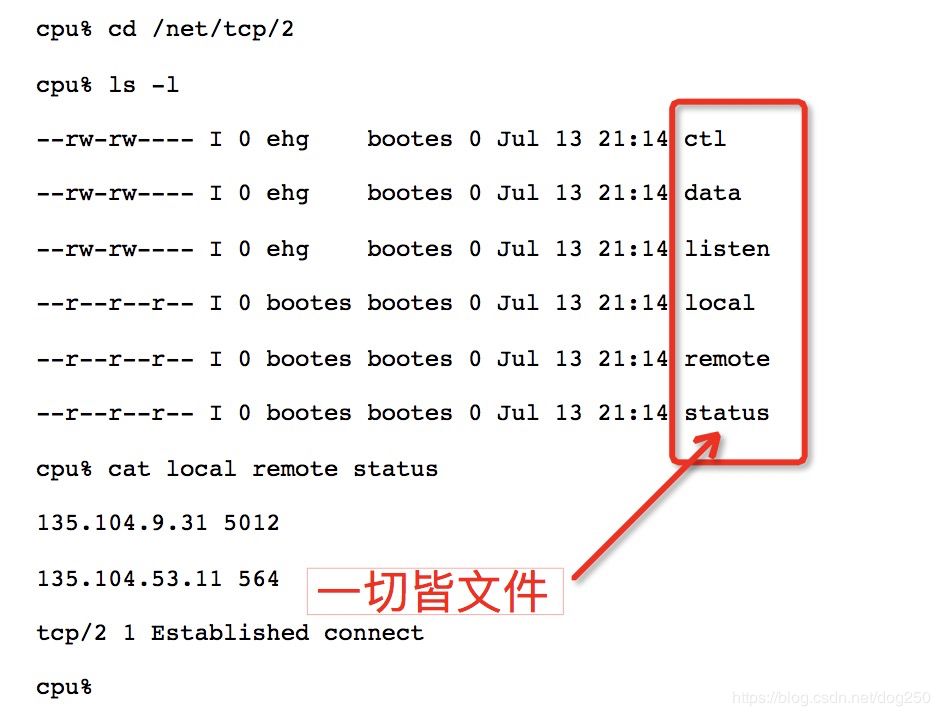
暂时不要恋战,先把本文看完,因为我下面的UDP的实例算是Plan实践的简版,理解了这个简版,再仔细阅读下面的链接以体会原汁原味的Plan 9-The Organization of Networks in Plan 9:
http://doc.cat-v.org/plan_9/4th_edition/papers/net/
Plan 9并没有由于其设计的先进性而变得流行起来,不过幸运的是,它的思想被Linux吸收了。我们便有机会在熟悉的Linux系统实现憧憬中的socket文件机制了。
“一切皆文件”之Linux
Linux贯彻一切皆文件的程度要远远超过传统Unix。Linux除了普通文件,目录,设备文件,管道等之外,实现非常多的特殊文件,这些都是直接或间接来自Plan 9:
procfs【此乃Plan 9的嫡系】
sysfs
cpuset
debugfs
cgroup
…
真的是一切皆文件了。你无需调用特殊的接口,只需要echo就可以在sysfs中通过写文件的方式将CPU进行热插拔:
[root@localhost ~]# echo 0 >/sys/devices/system/cpu/cpu0/online
[root@localhost ~]# echo 0 >/sys/devices/system/cpu/cpu2/online
结果就只剩2个CPU了
[root@localhost ~]# cat /proc/cpuinfo |grep processor
processor : 1
processor : 3
[root@localhost ~]#
Linux sysfs实现UDP socket文件机制
UDP socket文件就是基于这种sysfs实现的,我称它UDP socket sysfs。
本文不是讲sysfs原理的,这方面的资源已经很多了,我就不再赘述。这里仅仅提sysfs的最基本特征:
每一个可以表示为文件的对象Obj都是sysfs中的一个目录。
每一个Obj的任何属性都表示为该Obj对应目录下的一个文件。
以上面的CPU热插拔为例,/sys/devices/system/cpu是一个目录,它表示系统的所有CPU,其属性为:
cpu0 cpu1 cpu2 cpu3 cpuidle isolated kernel_max microcode modalias nohz_full offline online possible power present uevent
我们查看其offline属性,它表示已经下掉的CPU,只需要读该文件即可:
[root@localhost ~]# cat /sys/devices/system/cpu/offline
0,2
Linux sysfs使传统的ioctl系统调用再无必要。
为了获得第一即视感,我先演示UDP socket sysfs文件的效果,然后再给出源码。
我们希望用sysfs下的文件表示UDP socket,因此我们要创建一个表示UDP socket的目录:
[root@localhost sysfs_test]# ls /sys/kobject_udp/
ctrl
该目录表示UDP socket的汇总,它有一个属性文件,即ctrl,对其读写将会触发一系列的事件:
写create到ctrl:创建一个UDP socket。
写shutdown到ctrl:销毁UDP socket。
[root@localhost sysfs_test]# echo -n create >/sys/kobject_udp/ctrl
[root@localhost sysfs_test]# ls /sys/kobject_udp/
ctrl instance_0
[root@localhost sysfs_test]# ls /sys/kobject_udp/instance_0/
ctrl data
[root@localhost sysfs_test]#
创建一个UDP socket sysfs实例相当于在kobject_udp创建了一个目录instance_0,该UDP socket sysfs实例有两个属性:
data:用于数据的收发。
ctrl:用于控制,读写该文件可以实现connect,bind,set/getsockopt等。
数据和控制相分离,但是它们都是Linux系统目录树中的可读写的文件,写ctrl就能达到对socket进行控制的效果:
[root@localhost sysfs_test]# echo -n bind 127.0.0.1:123 >/sys/kobject_udp/instance_0/ctrl
[root@localhost sysfs_test]# netstat -anup
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 0.0.0.0:123 0.0.0.0:* -
[root@localhost sysfs_test]#
可见,通过写入UDP socket sysfs实例的ctrl文件,新建的socket便bind到本地123端口,可以通过netstat看出来操作已经成功。
接下来我们将其connect到本地的另一个端口,试试数据的收发: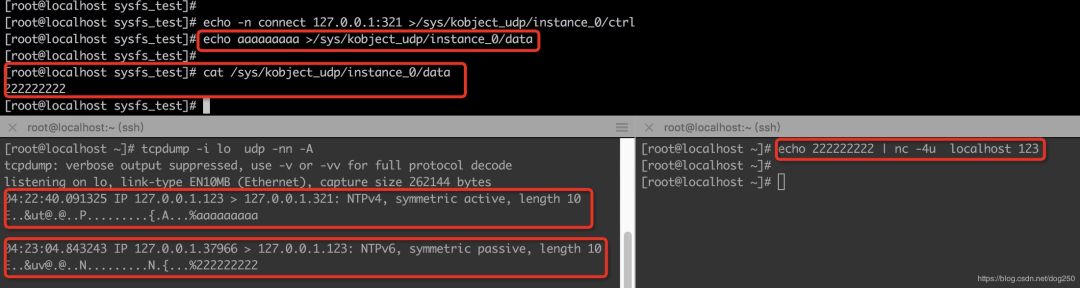
现在仿照bash的/dev/udp/
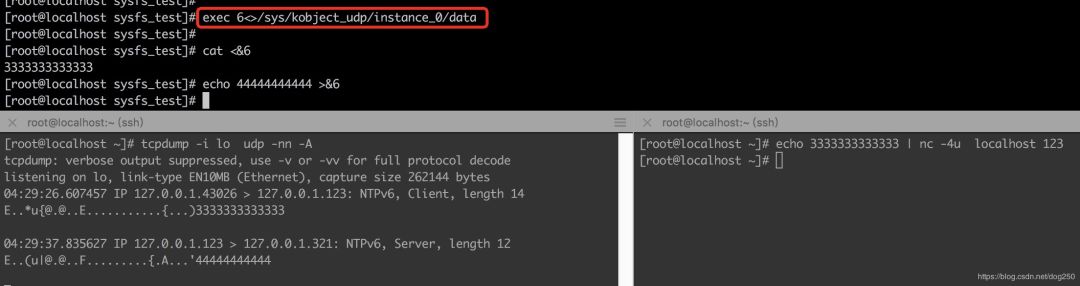
OK,工作的不错。就是要这样的效果。
好了,现在该给出源码了:
// sysudp.c
// make -C /lib/modules/`uname -r`/build SUBDIRS=`pwd` modules
// insmod ./sysudp.ko
#include <linux/module.h>
#include <linux/init.h>
#include <linux/sysfs.h>
#include <linux/ip.h>
#include <linux/in.h>
static struct kobject *udp_kobject, *srv;
static char ctrl, cctrl, data;
struct socket *ksock;
struct sockaddr_in addr, raddr;
struct msghdr msg;
struct iovec iov;
mm_segment_t oldfs;
static int bind_socket(unsigned short port)
{
memset(&addr, 0, sizeof(struct sockaddr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port);
if (ksock->ops->bind(ksock, (struct sockaddr*)&addr, sizeof(struct sockaddr)) < 0)
return -1;
return 0;
}
static ssize_t cctrl_store(struct kobject *kobj, struct kobj_attribute *attr, char *buf, size_t count)
{
// 为了代码简短,未做字符串解析,采用了硬编码,且仅支持一个socket的创建
if (!strcmp(buf, "connect 127.0.0.1:321")) { // 写ctrl文件实现connect
memset(&raddr, 0, sizeof(struct sockaddr));
raddr.sin_family = AF_INET;
raddr.sin_addr.s_addr = htonl(0x7f000001);
raddr.sin_port = htons(321);
} else if (strstr(buf, "bind 127.0.0.1:123")) { // 写ctrl文件实现bind
bind_socket(123);
} else if (strstr(buf, "setsockopt")) { // sockopt也是写文件完成
// TODO
}
return count;
}
static ssize_t cctrl_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf)
{
return sprintf(buf, "bind x.x.x.x:yyy
connect x.x.x.x:yyy
setsockopt value
[TODO]....
");
}
static ssize_t data_store(struct kobject *kobj, struct kobj_attribute *attr, char *buf, size_t count)
{
int size = 0;
if (ksock->sk == NULL) return 0;
iov.iov_base = buf;
iov.iov_len = count;
msg.msg_flags = 0;
msg.msg_name = &raddr;
msg.msg_namelen = sizeof(struct sockaddr_in);
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = NULL;
oldfs = get_fs();
set_fs(KERNEL_DS);
size = sock_sendmsg(ksock, &msg, count);
set_fs(oldfs);
return size;
}
static ssize_t data_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf)
{
int size = 2048;
if (ksock->sk == NULL) return 0;
iov.iov_base = buf;
iov.iov_len = size;
msg.msg_flags = 0;
msg.msg_name = &addr;
msg.msg_namelen = sizeof(struct sockaddr_in);
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = NULL;
oldfs = get_fs();
set_fs(KERNEL_DS);
size = sock_recvmsg(ksock, &msg, size, msg.msg_flags);
set_fs(oldfs);
return size;
}
static struct kobj_attribute ctrl_attribute =__ATTR(ctrl, 0660, cctrl_show, cctrl_store);
static struct kobj_attribute data_attribute =__ATTR(data, 0660, data_show, data_store);
static ssize_t ctrl_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf)
{
return sprintf(buf, "create
shutdown
[TODO]....
");
}
static int create_socket()
{
if (sock_create(AF_INET, SOCK_DGRAM, IPPROTO_UDP, &ksock) < 0)
return -1;
return 0;
}
static ssize_t ctrl_store(struct kobject *kobj, struct kobj_attribute *attr, char *buf, size_t count)
{
// 仅支持一个socket
if (!strcmp(buf, "create")) { // 写ctrl文件创建socket实例
if (!srv) {
srv = kobject_create_and_add("instance_0", udp_kobject);
sysfs_create_file(srv, &ctrl_attribute.attr);
sysfs_create_file(srv, &data_attribute.attr);
create_socket();
}
} else if (!strcmp(buf, "shutdown")) { // 写ctrl文件销毁socket实例
if (srv)
if (ksock)
sock_release(ksock);
kobject_put(srv);
srv = NULL;
}
return count;
}
static struct kobj_attribute foo_attribute =__ATTR(ctrl, 0660, ctrl_show, ctrl_store);
static int __init sysudp_init (void)
{
int error = 0;
srv = NULL;
udp_kobject = kobject_create_and_add("kobject_udp", NULL);
if(!udp_kobject)
return -ENOMEM;
error = sysfs_create_file(udp_kobject, &foo_attribute.attr);
return error;
}
static void __exit sysudp_exit (void)
{
if (srv) {
if (ksock)
sock_release(ksock);
kobject_put(srv);
}
kobject_put(udp_kobject);
}
MODULE_LICENSE("GPL");
module_init(sysudp_init);
module_exit(sysudp_exit);
Review源码,我们发现了socket sysfs和socket接口的两点最大不同,socket sysfs文件有以下性质:
socket用sysfs的一个目录表示
即socket sysfs文件作为一个对象在sysfs是一个目录,该目录下两个属性文件用于实际操作,一个是数据通信用的data属性文件,一个是作为控制使用的ctrl属性文件。消除了socket的open行为
这是最精妙的。socket只能被创建而不是被打开,只有存在的东西才能被打开。能被打开的是socket的data属性文件和ctrl文件,打开它们的目的是读写它们,这就是“一切皆文件”在socket上的体现。
在这个源码之后,其实还有很多的TODO:
socket文件的访问控制如何做
以往的socket文件描述符的作用域是创建它的进程,如果采用sysfs文件的话,将会是全局可见,如何进程访问控制,需要设计一套规则。性能问题
本文到此为止没有涉及任何有关性能的问题,但是在实际实现中,这个是必须要考虑的。…
UDP socket sysfs文件实现后,TCP呢?我们需要实现一个TCP的socket sysfs文件机制,从而可以用shell脚本粘合独立的小程序实现复杂的TCP客户端和TCP服务器。
TCP客户端比较容易实现,和UDP socket文件实现类似,TCP服务端需要做的更多。典型是如何实现连接管理。或者说,到底还需不需要连接管理,需不需要socket的listen,accept那一套也都是疑问。
bash没有实现类似 /dev/tcp/$host/$port 那样的伪设备文件来实现TCP脚本服务器,但是zsh的ztcp module可以做到。这里给出一个zsh脚本实现的TCP服务器:
#!/usr/bin/zsh
# 加载ztcp模块
zmodload zsh/net/tcp
# 处理IO,其实就是一个echo
handle-io() (
# 从TCP client读取一行。这里用cat <&4会有问题,因为没有EOF
read -ru4 line
# 打印收到的东西
echo from client: $line
# 把收到的内容echo回对端
echo echo from server: $line >&4
# 关闭描述符
exec 4>&-
)
ztcp -l -d 3 12345
while ztcp -ad4 3; do
# 在子进程中处理TCP client
(handle-io)
# 父进程关闭TCP client
exec 4>&-
done
多么典型的TCP accept/fork编程模型啊。
写一个sysfs内核模块,实现以下机制即可:
实现ztcp -l:通过写TCP目录的ctrl文件实现
实现ztcp -a:接收连接后自动创建TCP client目录
实现TCP通信:通过读写TCP client目录的data文件实现。
这并不困难。
我们憧憬着,将来netcat,socat,telnet,ztcp这类专门处理简单网络操作的微型程序将不再需要,我们只需要cat/read,echo/write即可。而这个憧憬在Plan 9上已经成了现实。
思考
本文结束之前,我们来思考一个问题:
是设计一个新的API,还是用不同的参数调用既有API?
以文件操作为例,假设文件IO的read和write都工作的很好,现在又个新的需求,要实现的业务逻辑我们称之为business,如何实现这个需求不外乎以下两种:
将business的逻辑封装成一个新的API,使用者直接调用
将business的逻辑抽象成数据流暴露给使用者
这就又回到了一文中的例子。请实现式子
的计算。
对于第1种方案,显然是要这么做:
int business(int a, int b, int c)
{
return (a+b)/c;
}
简单直接,实现又快。
对于第2种思路,便需要如下步骤:
分别写一个表示两个数加法和两个数相除的程序。
用管道将这些程序组织起来,获取结果。
显然没有第1种方法直接快速。但是,如果这个要求解的式子换成一元二次方程的求根公式怎么办?是重新重构business函数呢,还是重新组合运算符程序用管道连接它们呢?
之所以会出现ioctl以及socket接口这种奇怪的API,因为它们足够直接,实现足够快速,才因此破坏了Unix“一切皆文件”的原则。
read和write则不然,参数只是一个裸buffer,在API层面没有任何自解释特征,所以,少就是多,无则是全,read和write事实上可以完成 “任意” 操作!
这便是“一切皆文件”的精髓,这便是我写sysfs UDP socket文件模块的缘由,欣赏这种美并宣扬它便是我写这篇文章的动机。
浙江温州皮鞋湿,下雨进水不会胖。
(完)
更多精彩,尽在"Linux阅码场",扫描下方二维码关注
你的随手转发或点个在看是对我们最大的支持!
以上是关于实例演绎Unix/Linux的"一切皆文件"思想的主要内容,如果未能解决你的问题,请参考以下文章