对 Linux 内核中的 eBPF JIT 漏洞进行 fuzz
Posted 星阑科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对 Linux 内核中的 eBPF JIT 漏洞进行 fuzz相关的知识,希望对你有一定的参考价值。
点击蓝字
前言
本文仅为翻译,供技术爱好者学习使用。在受到 Manfred Paul 的一篇 eBPF JIT 验证器漏洞 writeup 文章启发之后,我也想确认在 Manfred Paul 找到的漏洞发布以后,Linux eBPF 验证器是否已经有较大的变化,以及是否有一种简单的方法可以来对验证器进行 fuzz 。
结果发现,对 Manfred 之前发现的漏洞进行修复的时候,验证器还引入了一个新的漏洞,也就是 CVE-2020-27194。
本篇文章主要讲我针对 Linux eBPF 所编写的 fuzzer 的架构,以及所编写的自定义生成器的设计。之后过段时间,我将会发布 fuzzer 的代码以及我发现的漏洞的利用代码 poc。在我写这部分的时候,在 Ubuntu 20.10 里 bug 依然没有被修补。
如果你对 BPF 不熟悉,我推荐在继续读下面内容之前,先阅读上面我所链接的 writeup 。
另外,如果愿意也可以直接跳到 CVE-2020-27194 去看下。
现有项目
在我开始写代码之前,我先是看了下之前关于 fuzz eBPF JIT 验证器的项目。我发现,其实已经有一个关于这个的 fuzzer 了,发布在了这个 github repo 里。
引用下 repo 页面里的内容:
“本项目的动机是希望在用户空间测试验证器,这样可以利用上 llvm 的 sanitizer 以及 fuzzer 框架。”
然后我就在想,为什么这个项目的创造者选择这么麻烦地把一个如此复杂的内核组件编译到用户空间,而不是直接使用现有的解决方案,比如 Syzkaller。我觉得可能有如下两个方面的原因:
1、内核与用户空间比起来是非常慢的,特别是考虑到上下文切换的时间以及缺失对内存分配器的控制。
2、BPF 验证器,包括 JIT 编译器部分,都是被 mutex 所保护的,所以如果用多于一个核进行 fuzz 就会扩展得很差。
我们先过一下利用 hook 将调用到的内核函数编译到用户空间的过程,这也是这个 fuzz 所用到的技术。
//将内核组件编译为用户空间程序
我们所提到的 fuzz 用的方法就是,首先,利用 linux build 系统以及头文件来生成预处理后的、包含 eBPF 验证器以及其主过程 bpf_check() 的代码。这意味着,编译器其实并不会编译任何东西,只是会处理宏、头文件包含,然后把原始的结果代码写入到 .i 文件中。
这一步的目的是为获取验证器引用到的所有内核符号声明,这样才能够简单地把结果文件编译到用户空间,也就是下一步需要做的。
一个生成这样的 linux 源代码 .i 文件的小例子大概像这样:
KERNEL_SRC=/path/to/kernel/to/fuzz-testprocess_example:cd $(KERNEL_SRC) &&make HOSTCC=clang CC=clang kernel/bpf/verifier.i
使用 Linux build 系统的优点就在于这一步会十分简单。
下一步其实就是把生成每一个的 .i 文件进行编译,然后把它们链接起来。这一步就是开始复杂的一步了。虽然我们在第一步已经获取到了验证器会用到的所有符号的声明,但是这其实不代表我们已经获取到了所有的定义。
举例来讲,验证器有可能会包含声明内核分配器函数,像是 kmalloc() 这样的头文件,然后 kmalloc() 的定义属于另一个完全不同的内核子系统,所以链接器没办法成功链接验证器 object 文件。
为解决这个问题,BPF fuzzer 的作者编写了用户空间 hook,也就是说,他们自己实现了像 kmalloc() 这样的调用。以kmalloc 为例,他们直接在 kmalloc() 函数的定义里边调用了用户空间标准函数 malloc() 。下面是一个示例:
void *kmalloc(size_t size, unsigned int flags){return malloc(size);}
只要它们的行为相同(返回一个分配了的内存块或是返回错误指针),对将在用户空间运行的 BPF 验证器来说,kmalloc() 函数这样的 "hook" 就是透明的。然后,编译器就可以成功将这个函数和 BPF 的 object 文件进行链接。
对验证器里引用的每一个未定义引用进行 hook 是非常累的,但是考虑其带来的性能提升,还是十分划算的。
//这个fuzzer与已有的项目有何不同
我大概把编译内核组件为用户空间程序的过程剖析了一下。我上面提到的现有项目的作者用了这个方法,这是个很有意思的方法,现在他们就可以直接用 libffuzer 来 fuzz BPF 验证器了。
然而,我的目标并不是去找验证器代码中的内存破坏,而是去找 JIT 的逻辑漏洞,例如验证器认为这个内存存储操作是在范围内的,所以是安全的,但是其实不是。
为了满足这个要求,用一个循环去调用 BPF 验证器,然后等其崩溃是不够的。一个输入的整个执行流程而应该差不多像下面这样:
1、生成或是变异一个 BPF 程序
2、用 BPF 验证器去执行验证
3、如果程序是合法的,通过运行真正的 bpf() 系统调用,然后加载程序进行分流
4、触发程序,然后利用某种 in place 的机制来检查漏洞
5、重复
整个流程如下:
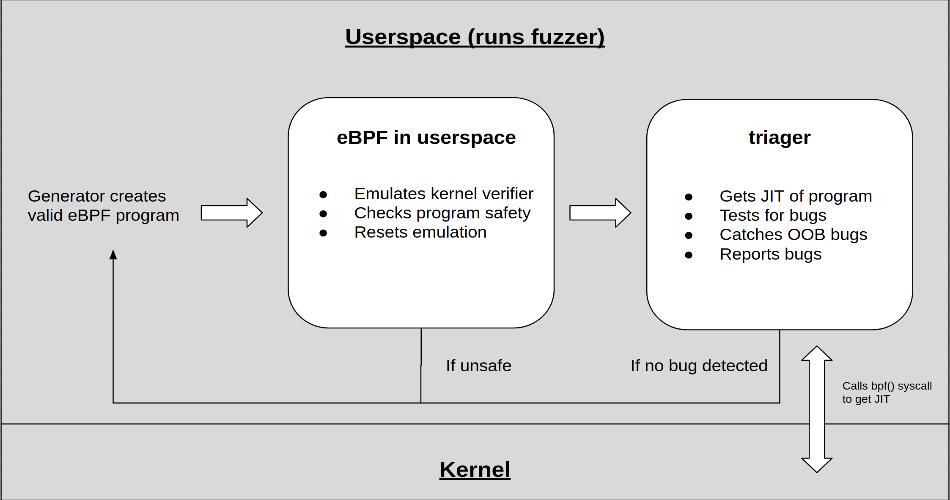
//Fuzzer架构
为了有高效的实现我上面提到的执行流程,我决定用一种能够尽可能扩展的方法。
因为这个原因,我写了个管理器。管理器的作用是启动许多运行用于测试的 linux 内核的虚拟机。管理器然后会利用 SSH 连接到虚拟机上,执行一系列 eBPF fuzz 进程。每一个 fuzz 进程都会运行自己的生成器,然后将其喂到用户空间的 BPF 验证器例。如果生成的输入是合法的,fuzzer 就会通过 bpf() 系统调用加载 BPF 程序,然后触发程序执行。之后,其会用一个漏洞检查机制来确认程序是确实安全的。
漏洞检测
JIT 的漏洞检测是个困难问题,因为漏洞可能并不会让内核崩溃。举个例子,验证器很自信地认为有一个程序分支是一定会进入的,但是其实可能并不是一定的。
这个问题的一种解决方案就是用一些运行时断言来扩展 JIT ,不过我用了一种更简单的方法。
我的目标是找到指针计算错误漏洞,也就是验证器认为一个内存加载或是存储是界内的,但是其实有可能不是。
出于这个原因,漏洞检测原理大概是这样:
1、加载一个 BPF map ,将一个指向它的指针移动到寄存器里
2、在一个或多个寄存器中进行随机数量的 BPF ALU 和跳转操作
3、使用一个寄存器,在指向 map 的指针进行至少一次或多次指针运算操作,寄存器的状态被操作所改变
4、向指针指向的位置写入一个随机值
如果一个 BPF 验证器在程序上运行,然后认为其是安全的,那么我就得到了一个保证,认为无论我进行随机 ALU 操作的寄存器是什么值,然后加减 map 指针的值,内存操作应该一直是在界内的,也就是说,map 的值必须能改变。
这样的话,如果在测试的 BPF 程序触发以后,我用来测试的 map 的内容没有改变,那我就知道 fuzzer 写到了不在 map 中的内存区域,那么就检测到了错误的指针运算。
输入生成
一样的,如果你对 BPF 不太熟悉,下面几节读起来读不太懂的话,我推荐阅读一下 Manfred Paul 的 writeup 然后再回来读。
//程序有效性vs程序安全性
我决定自己从头写一个生成器,而不是用像 libfuzzer 一样的,现有的结构无关 fuzzer 来进行变异和生成。这一点的原因是,虽然通过覆盖率引导反馈,libfuzzer 可以在某个时间点生成合法的程序,甚至是在有输入语料库之后还可以生成复杂的程序,但是有大量的变异的输入都不是合法的。
一个合法的 BPF 程序需要遵循 BPF 语言的规则,例如,保留的域必须是 0 。另外一个规则是,条件跳转必须向前跳,而且必须在界内。还有一个规则,寄存器在读取之前必须被初始化了。总得来说,BPF 程序是高度结构化、状态化的,在这样的情况下,将输入认为是二进制的无结构数据且并不检测无效状态的覆盖率引导 fuzzer 并不是最有效的解决方案。
通过写一个自定义的生成器就可以一直生成合法的输入,满足 BPF 程序的所有规则。验证器可能还是会在认为程序是不安全的时候拒绝程序,但是程序总是可以通过基本的检查,例如保留域没有设置或是只允许使用有效的寄存器。
//寄存器状态
为了给像 BPF 验证器一样的状态机编写生成器,这个生成器必须要某种程度上对可能的状态有所感知。我之前提到了寄存器状态,所以我想更细致地讲讲这是怎么回事。
BPF 支持 10 个寄存器:BPF_REG_1 - BPF_REG_10。
在 BPF 程序用来作为包过滤器时,程序会在传入的包上触发、运行,寄存器 R1 和 R10 是仅有的已初始化寄存器。BPF_REG_R1 是指向输入包的指针,而 BPF_REG_R10 指向这个 BPF 程序执行的栈帧,其他的寄存器在程序入口处都是未初始化的,但是可以是以下的任意一种状态:
NOT_INIT: 寄存器的默认状态,此时不能被读取。
SCALAR_VALUE: 寄存器包含一个 scalar 值,这个值要么是一个已知的常量,要么是一个范围,例如 1 - 5 。
PTR_TO_MAP_VALUE_OR_NULL:寄存器可以包含指向 map 的指针或是 NULL 。如果要使用这个指针,必须先对其进行检查,检查其指针是否为 NULL 。
PTR_TO_MAP_VALUE:一个寄存器包含已经被检查过的 map 指针。可以被用来对 map 进行读或写。
其实还有更多的状态,但是它们与我们现在没什么关系。有了这些知识以后,我们就可以继续讨论生成器了。
//在生成器中使用BPF框架程序
之前我提到,为能够高效地对产生 JIT 漏洞的 eBPF 程序进行 fuzz 以及对它们进行检测,在每次测试用例中必须有特定的指令。出于这个原因,我设计了一个生成器用来产生包含头部、身体和尾部的输入。
01
头部
因为我们是打算测试不正确的指针计算验证,我们需要获取一个指向 BPF map 的指针,这个指针我们需要能够读取以及之后写入。这一部分是测试用例总是需要有的,可以认为是初始化,所以属于头部部分,由下面的 BPF 指令静态地生成:
// prepare the stack for map_lookup_elem// 准备 map_lookup_elem 的栈BPF_MOV64_IMM(BPF_REG_0, 0),BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4),BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4),// make the call to map_lookup_elem// 执行对 map_lookup_elem 的调用BPF_LD_MAP_FD(BPF_REG_1, BPF_TRIAGE_MAP_FD),BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),// verify the map so that we can use it// 验证 map,这样我们才可以用到它BPF_JMP_IMM(BPF_JNE, BPF_REG_0, 0, 1),BPF_EXIT_INSN(),
在这个操作进行之后,我们现在就可以使用 BPF_REG_0作为指向 map 的指针,然后在我们想要的时候进行指针运算了。
然后我写了代码来将两个寄存器初始化为 map 上读取的未知值:
BPF_LDX_MEM(BPF_DW, this->reg1, BPF_REG_0, 0),BPF_LDX_MEM(BPF_DW, this->reg2, BPF_REG_0, 8),
这里的两个寄存器都初始化为了 map 上读取的 64 位值,这样就会让它们的状态从 NOT_INIT 转换为 SCALAR_VALUE。在这个时候,寄存器的值可以是 0 到 2**64 之间的任何一个,因为他是个 64 位的寄存器。另外如果不采用从 map 上加载两个未知值的方法,也可以很简单地生成一个指令来加载来个随机的立即数到寄存器里的方法。
为了能够使寄存器的边界与测试程序的 map 大小接近,头部的下一步就是生成条件跳转来检测两个寄存器的最小和最大值。
下面的代码负责生成寄存器的最小边界:
inline struct bpf_insn input::generate_min_bounds(unsigned reg, int64_t val){bool is64bit = this->rg->one_of(2);this->min_bound = val == -1 ? this->rg->rand_int_range(-FUZZ_MAP_SIZE, FUZZ_MAP_SIZE): val;if (is64bit)return BPF_JMP_IMM(BPF_JSGT, reg, this->min_bound, 1);elsereturn BPF_JMP32_IMM(BPF_JSGT, reg, this->min_bound, 1);}
可以看到,其实它就是生成了一个条件跳转,这个条件跳转在值比最小边界,也就是随机生成的从 -FUZZ_MAP_SIZE 到 FUZZ_MAP_SIZE (我将其设置为了 8192)范围内的数要大的时候就是 true。
02
身体部分
头部用常量或是一个在 map 大小附近范围内的一个值初始化了两个寄存器。身体部分现在就负责在这两个寄存器之间生成随机数量的 ALU 操作。
身体部分用了一个循环,然后就很简单地选择了两个可以进行 ALU 或跳转指令的寄存器,之后生成随机的指令。
for (size_t i = 0; i < num_instr; i++) {int reg1, reg2;this->chose_registers(®1, ®2);if (rg->n_out_of(8, 10) || i == this->num_instr - 1) {alu_instr a;a.generate(this->rg, reg1, reg2);this->instructions[index++] = a.instr;}else {branch_instr b(this->header_size, this->header_size + this->num_instr, index);b.generate(this->rg, reg1, reg2);this->instructions[index++] = b.instr;generated_branch = true;}}
指令的生成非常简单,考虑 ALU 操作的情况,生成器会随机选可用的指令的其中一个,例如 BPF_ADD 、BPF_MUL、BPF_XOR 等等。之后,生成器需要决定哪个寄存器是操作的源寄存器,哪个是操作的目标寄存器。最后,返回生成的 BPF 指令。
跳转指令的情况也类似,首先会选择一个有效的跳转操作码,然后要么用第二个寄存器,要么用立即数。生成器会考虑到程序的大小以及指令所在位置的索引,然后总是会生成合法的跳转指令。
03
尾部部分
为保证每个输入都会对 map 进行一次内存写,尾部部分会选两个修改后的寄存器中的一个然后基于这个寄存器生成一些指针运算指令。这部分生成和 ALU 指令生成的逻辑相同,但是只用加法和减法,因为这是唯二允许使用的指针运算操作。
void range_input::generate_footer(){size_t index = this->header_size + this->num_instr;// generate the random pointer arithmetic with one of the registers// 利用其中一个寄存器生成随机的指针运算int reg1, reg2 = -1;this->chose_registers(®1, ®2);alu_instr ptr_ar;ptr_ar.generate_ptr_ar(this->rg, BPF_REG_4, reg1);this->instructions[index++] = ptr_ar.instr;this->instructions[index++] = this->generate_mem_access(BPF_REG_4);this->instructions[index++] = BPF_MOV64_IMM(BPF_REG_0, 1);this->instructions[index++] = BPF_EXIT_INSN();}
之后就可以进行内存操作,然后最终将立即数移动到 BPF_REG_0中,来保证有一个合法的返回值,然后退出。
Fuzzer的总结
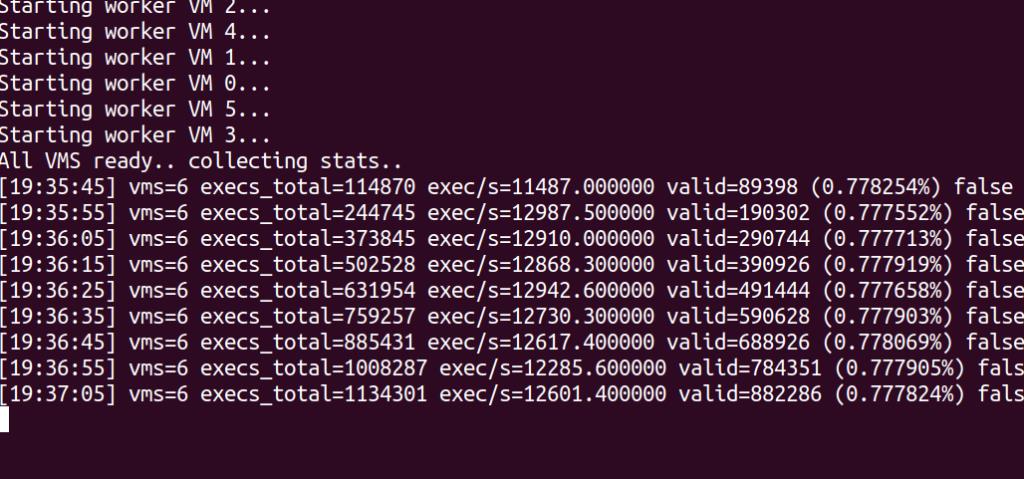
上面的截图展示了用 6 个 vm 进行 fuzz 时的 fuzzer 输出。在上面的情况中,每个 vm 生成、验证、分流以及测试大约每秒 1200 个程序。在我写本文的时候,生成了大约 0.77% 的程序且被认为是正确的然后进行了测试。需要注意的重点是,fuzz 的时间大多花在了测试程序的过程中,所以内核才是瓶颈。下一步可以做的事情就是在用户空间执行最后的 JIT 程序,从而完全避免与内核进行交互,这样就可以极大的提高速度。
在利用这个 fuzzer 进行 fuzzing 以及调试的过程中,得到的其中一个结果就是 CVE-2020-27194 ,是一个由于 OR ALU 操作导致的 BPF 验证器漏洞,利用其可以得到完整的本地提权 exp 。
星阑科技
以上是关于对 Linux 内核中的 eBPF JIT 漏洞进行 fuzz的主要内容,如果未能解决你的问题,请参考以下文章
Linux内核 eBPF基础:perf:perf_event在内核中的初始化