对redis基础知识记录
Posted 大胖与小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对redis基础知识记录相关的知识,希望对你有一定的参考价值。
首先直入主题,理解下非关系型数据库的特点:
1、存储非结构化的数据,比如文本、图片、音频、视频。
2、表与表之间没有关联,可扩展性强。
3、保证数据的最终一致性。遵循 BASE理论。Basically Available(基本
可用);Soft-state(软状态);Eventually Consistent(最终一致性)。
4、支持海量数据的存储和高并发的高效读写。
5、支持分布式,能够对数据进行分片存储,扩缩容简单。其实写了我也记不住,所以明白这个意思就行,接着我们回忆下,有多少种非关系型数据库,并且适用什么场景,对于不同的数据应该选用哪种。
1、KV 存储,用 Key Value 的形式来存储数据。比较常见的有 Redis 和 MemcacheDB
2、文档存储,MongoDB
3、列存储,HBase
4、图存储,这个图(Graph)是数据结构,不是文件格式。Neo4j
5、对象存储我们这里记录的是redis,redis默认有 16 个库(0-15),可以在配置文件中修改,默认使用第一个 db0。并且Redis 是字典结构的存储方式,采用 key-value 存储。key 和 value 的最大长度限制 是 512M,redis的数据类型:
基本类型:String、Hash、Set、List、Zset、
其他类型:Hyperloglog、Geo、StreamsRedis 的特性:
1)更丰富的数据类型
2)进程内与跨进程;单机与分布式
3)功能丰富:持久化机制、过期策略
4)支持多种编程语言
5)高可用,集群Redis 基本数据类型
string字符串
是redis中最基本的数据类型,一个key对应一个value。String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
常用命令:
设置多个值(批量操作,原子性)
mset qingshan 2673 jack 666
设置值,如果 key 存在,则不成功
setnx qingshan
基于此可实现分布式锁。用 del key 释放锁。
但如果释放锁的操作失败了,导致其他节点永远获取不到锁,怎么办?
加过期时间。单独用 expire 加过期,也失败了,无法保证原子性,怎么办?多参数
set key value [expiration EX seconds|PX milliseconds][NX|XX]
使用参数的方式
set lock1 1 EX 10 NX
(整数)值递增
incr qingshan
incrby qingshan 100
(整数)值递减
decr qingshan
decrby qingshan 100
浮点数增量
set f 2.6
incrbyfloat f 7.3
获取多个值
mget qingshan jack
获取值长度
strlen qingshan
字符串追加内容
append qingshan good
获取指定范围的字符
getrange qingshan 0 8存储(实现)原理
1:数据模型
set hello word 为例,因为 Redis 是 KV 的数据库,它是通过 hashtable 实现的(把这个叫做外层的哈希)。所以每个键值对都会有一个 dictEntry对象, 里面指向了 key 和 value 的指针。next 指向下一个 dictEntry对象。
typedef struct dictEntry {
void *key; /* key 关键字定义 */
union {
void *val; uint64_t u64; /* value 定义 */
int64_t s64; double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;k/v说明:
key :是字符串,但是 Redis 没有直接使用 C 的字符数组,而是存储在自定义的 SDS 中。
value :既不是直接作为字符串存储,也不是直接存储在 SDS 中,而是存储在 redisObject 中。
实际上五种常用的数据类型的任何一种,都是通过 redisObject 来存储的。2:redisObject理解:
typedef struct redisObject {
unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */
int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了
*/
void *ptr; /* 指向对象实际的数据结构 */
} robj;redisObject来表示真正的数据类型,五种数据类型,都是通过它来存储的。我们可以通过命令type来查看对外的类型:

3:redisObject的内部编码:
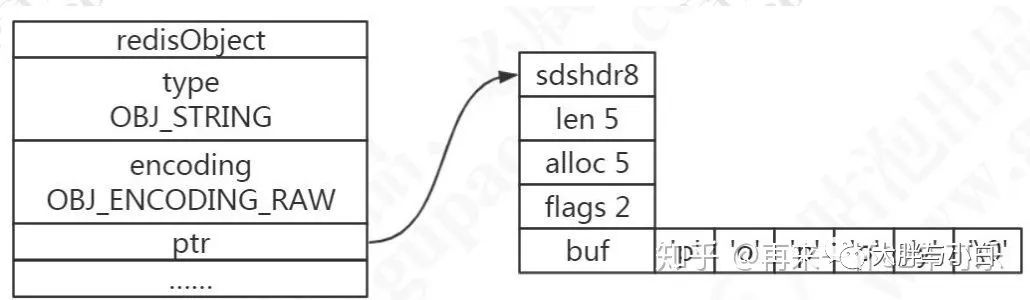
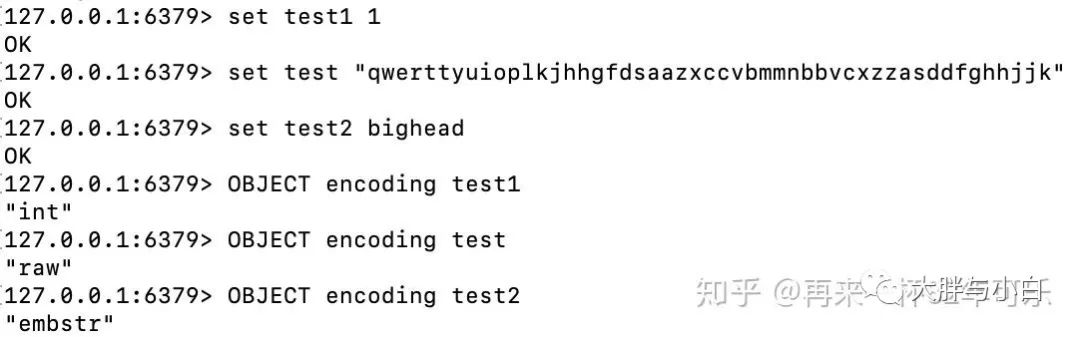
字符串类型的内部编码有三种:
1、int,存储 8 个字节的长整型(long,2^63-1)。
2、embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),
存储小于 44 个字节的字符串。
3、raw,存储大于 44 个字节的字符串应用场景
1:缓存,例如热点数据缓存
2:分布式共享session
3:分布式锁:set nx 和 set ex 两个命令一起使用实现。不过推荐多参数的 set nx ex,相信大家应该理解的不用细说
4:全局ID实现,INT 类型,INCRBY增量值,利用原子性,分库分表的场景,一次性拿一段
5:计数器实现,INT 类型,INCR增加1,文章的阅读量,微博点赞数,允许一定的延迟,先写入 Redis 再定时同步到数据库。
6:限流,INCR增加1,超过一定的值直接丢弃,可以用来实现限流中的漏斗算法Hash哈希
包含键值对的无序散列表。value 只能是字符串,不能嵌套其他类型。
同样是存储字符串,Hash 与 String 的主要区别?
1、把所有相关的值聚集到一个 key 中,节省内存空间
2、只使用一个 key,减少 key 冲突
3、当需要批量获取值的时候,只需要使用一个命令,减少内存/IO/CPU 的消耗Hash 不适合的场景:
1、Field 不能单独设置过期时间
2、没有 bit 操作
3、需要考虑数据量分布的问题(value 值非常大的时候,无法分布到多个节点)常用命令
1:HDEL key field1 [field2]
删除一个或多个哈希表字段
2:HEXISTS key field
查看哈希表 key 中,指定的字段是否存在。
3:HGET key field
获取存储在哈希表中指定字段的值。
4:HGETALL key
获取在哈希表中指定 key 的所有字段和值
5:HINCRBY key field increment
为哈希表 key 中的指定字段的整数值加上增量 increment 。
6:HINCRBYFLOAT key field increment
为哈希表 key 中的指定字段的浮点数值加上增量 increment 。
7:HKEYS key
获取所有哈希表中的字段
8:HLEN key
获取哈希表中字段的数量
9:HMGET key field1 [field2]
获取所有给定字段的值
10:HMSET key field1 value1 [field2 value2 ]
同时将多个 field-value (域-值)对设置到哈希表 key 中。
11:HSET key field value
将哈希表 key 中的字段 field 的值设为 value 。
12:HSETNX key field value
只有在字段 field 不存在时,设置哈希表字段的值。
13:HVALS key
获取哈希表中所有值
14:HSCAN key cursor [MATCH pattern] [COUNT count]
迭代哈希表中的键值对。存储(实现)原理
Redis 的 Hash 本身也是一个 KV 的结构,类似于 Java 中的 HashMap。
外层的哈希(Redis KV 的实现)只用到了 hashtable。当存储 hash 数据类型时, 我们把它叫做内层的哈希。内层的哈希底层可以使用两种数据结构实现:
ziplist:OBJ_ENCODING_ZIPLIST(压缩列表)
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,
而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,
是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
hashtable:OBJ_ENCODING_HT(哈希表)
数组加链表结构,数据结构类似hashmap那种
ziplist 的内部结构理解
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>

typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度 */
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数 */
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;hashtable(dict) 结构理解:
在 Redis 中,hashtable 被称为字典(dictionary),它是一个数组+链表的结构。前面我们知道了,Redis 的 KV 结构是通过一个 dictEntry 来实现的。Redis 又对 dictEntry 进行了多层的封装。
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 掩码大小,用于计算索引值。总是等于 size-1 */
unsigned long used; /* 已有节点数 */
} dictht;dictht放到了dict里面:
typedef struct dict {
dictType *type; /* 字典类型 */
void *privdata; /* 私有数据 */
dictht ht[2]; /* 一个字典有两个哈希表 */
long rehashidx; /* rehash 索引 */
unsigned long iterators; /* 当前正在使用的迭代器数量 */
} dict;从最底层到最高层 dictEntry——dictht——dict——OBJ_ENCODING_HT
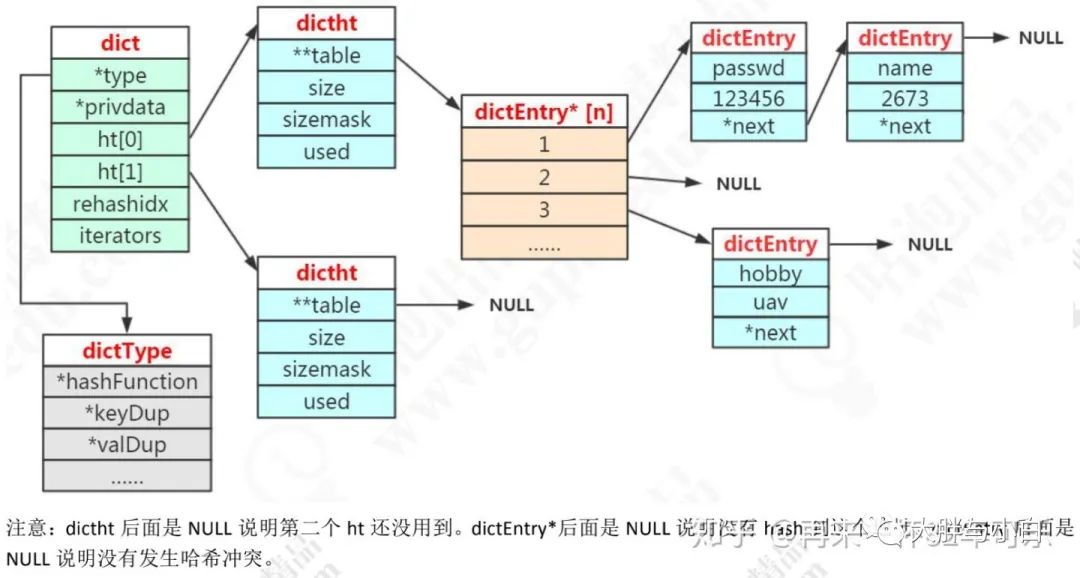
应用场景
1:购物车:key:用户 id;field:商品 id;value:商品数量。+1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen。
2:存储对象类型的数据,比如对象或者一张表的数据,比 String 节省了更多 key 的空间,也更加便于集中管理。
3:String能做的,它基本都能做。List列表
List 说白了就是链表(redis 使用双端链表实现的 List),是有序的,value可以重复,可以通过下标取出对应的value值,左右两边都能进行插入和删除数据。
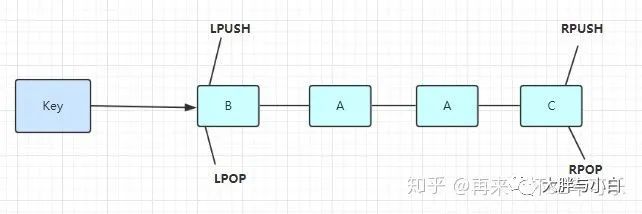
常用命令
1:BLPOP key1 [key2 ] timeout
移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
2:BRPOP key1 [key2 ] timeout
移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
3:BRPOPLPUSH source destination timeout
从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它;如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
4:LINDEX key index
通过索引获取列表中的元素
5:LINSERT key BEFORE|AFTER pivot value
在列表的元素前或者后插入元素
6:LLEN key
获取列表长度
7:LPOP key
移出并获取列表的第一个元素
8:LPUSH key value1 [value2]
将一个或多个值插入到列表头部
9:LPUSHX key value
将一个值插入到已存在的列表头部
10:LRANGE key start stop
获取列表指定范围内的元素
11:LREM key count value
移除列表元素
12:LSET key index value
通过索引设置列表元素的值
13:LTRIM key start stop
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
14:RPOP key
移除列表的最后一个元素,返回值为移除的元素。
15:RPOPLPUSH source destination
移除列表的最后一个元素,并将该元素添加到另一个列表并返回
16:RPUSH key value1 [value2]
在列表中添加一个或多个值
17:RPUSHX key value
为已存在的列表添加值存储(实现)原理
统一用 quicklist 来存储。quicklist 存储了一个双向链表,每个节点都是一个 ziplist。
quicklist结构
quicklist记录双向链表的头和尾,以及count等信息,链表实际是由quicklistNode组成的,quicklistNode对象里面会指向前一个和后一个,并且又zl属性,指向实际的zplist链表。
quicklist(快速列表)是 ziplist 和 linkedlist 的结合体。
quicklist属性head 和 tail 分别指向双向列表的表头和表尾
typedef struct quicklist {
quicklistNode *head; /* 指向双向列表的表头 */
quicklistNode *tail; /* 指向双向列表的表尾 */
unsigned long count; /* 所有的 ziplist 中一共存了多少个元素 */
unsigned long len; /* 双向链表的长度,node 的数量 */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* 压缩深度,0:不压缩;*/
} quicklist;quicklistNode 中的*zl 指向一个 ziplist,一个 ziplist 可以存放多个元素。
typedef struct quicklistNode {
struct quicklistNode *prev; /* 前一个节点 */
struct quicklistNode *next; /* 后一个节点 */
unsigned char *zl; /* 指向实际的 ziplist */
unsigned int sz; /* 当前 ziplist 占用多少字节 */
unsigned int count : 16; /* 当前 ziplist 中存储了多少个元素,占 16bit(下同),最大 65536 个 */
unsigned int encoding : 2; /* 是否采用了 LZF 压缩算法压缩节点,1:RAW 2:LZF */
unsigned int container : 2; /* 2:ziplist,未来可能支持其他结构存储 */
unsigned int recompress : 1; /* 当前 ziplist 是不是已经被解压出来作临时使用 */
unsigned int attempted_compress : 1; /* 测试用 */
unsigned int extra : 10; /* 预留给未来使用 */
} quicklistNode;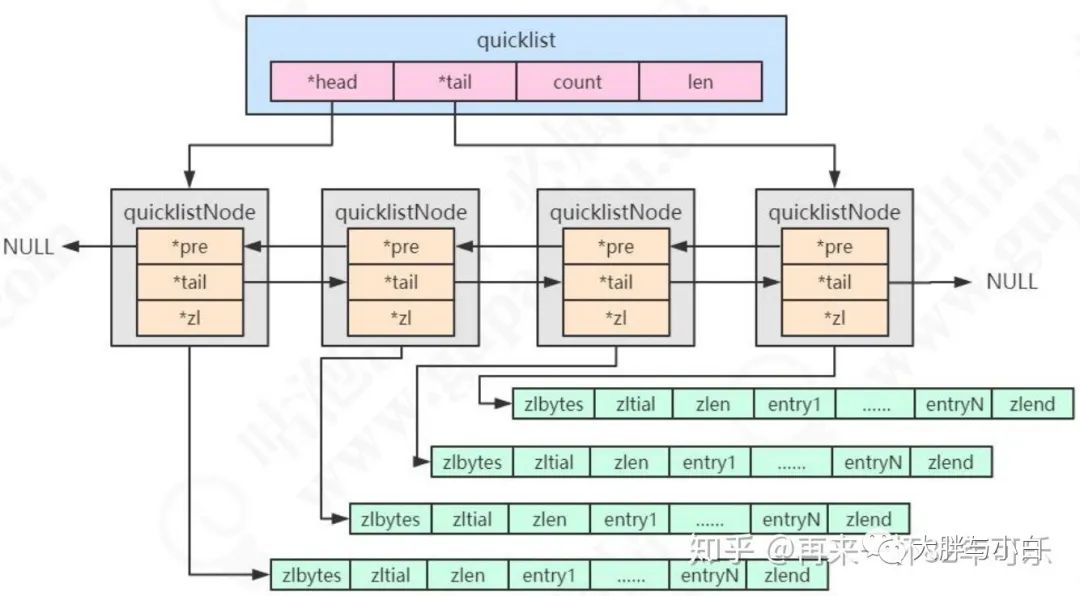
应用场景
1:用户消息时间线,因为 List 是有序的,可以用来做用户时间线
2:消息对列实现,并且还有阻塞的实现
lpush+lpop=Stack(栈)
lpush+rpop=Queue(队列)
lpush+ltrim=Capped Collection(有限集合)
lpush+brpop=Message Queue(消息队列)Set集合
String 类型的无序集合,最大存储数量 2^32-1(40 亿左右)。. 不允许有重复的元素,2.集合中的元素是无序的,不能通过索引下标获取元素,3.支持集合间的操作,可以取多个集合取交集、并集、差集。
常用命令
1:SADD key member1 [member2]
向集合添加一个或多个成员
2:SCARD key
获取集合的成员数
3:SDIFF key1 [key2]
返回给定所有集合的差集
4:SDIFFSTORE destination key1 [key2]
返回给定所有集合的差集并存储在 destination 中
5:SINTER key1 [key2]
返回给定所有集合的交集
6:SINTERSTORE destination key1 [key2]
返回给定所有集合的交集并存储在 destination 中
7:SISMEMBER key member
判断 member 元素是否是集合 key 的成员
8:SMEMBERS key
返回集合中的所有成员
9:SMOVE source destination member
将 member 元素从 source 集合移动到 destination 集合
10:SPOP key
移除并返回集合中的一个随机元素
11:SRANDMEMBER key [count]
返回集合中一个或多个随机数
12:SREM key member1 [member2]
移除集合中一个或多个成员
13:SUNION key1 [key2]
返回所有给定集合的并集
14:SUNIONSTORE destination key1 [key2]
所有给定集合的并集存储在 destination 集合中
15:SSCAN key cursor [MATCH pattern] [COUNT count]
迭代集合中的元素存储(实现)原理
Redis 用 intset 或 hashtable 存储 set。如果元素都是整数类型,就用 inset 存储。如果不是整数类型,就用 hashtable(数组+链表的存来储结构)。
应用场景
1:抽奖,随机获取元素 ,spop key命令
2:点赞、签到、打卡,
微博的 ID 是 t1001,用户 ID 是 u3001。
用key = like:t1001 来维护 t1001 这条微博的所有点赞用户。
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
比关系型数据库简单许多。
3:商品标签,用 tags:i5001 来维护商品所有的标签。
4:商品塞选,获取差集、交集、并集等
5:用户关注等ZSet有序集合
有序集合和集合有着必然的联系,保留了集合不能有重复成员的特性,区别是,有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。有序集合中的元素不可以重复,但是score 分数 可以重复。
常用命令
1:ZADD key score1 member1 [score2 member2]
向有序集合添加一个或多个成员,或者更新已存在成员的分数
2:ZCARD key
获取有序集合的成员数
3:ZCOUNT key min max
计算在有序集合中指定区间分数的成员数
4:ZINCRBY key increment member
有序集合中对指定成员的分数加上增量 increment
5:ZINTERSTORE destination numkeys key [key ...]
计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中
6:ZLEXCOUNT key min max
在有序集合中计算指定字典区间内成员数量
7:ZRANGE key start stop [WITHSCORES]
通过索引区间返回有序集合指定区间内的成员
8:ZRANGEBYLEX key min max [LIMIT offset count]
通过字典区间返回有序集合的成员
9:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT]
通过分数返回有序集合指定区间内的成员
10:ZRANK key member
返回有序集合中指定成员的索引
11:ZREM key member [member ...]
移除有序集合中的一个或多个成员
12:ZREMRANGEBYLEX key min max
移除有序集合中给定的字典区间的所有成员
13:ZREMRANGEBYRANK key start stop
移除有序集合中给定的排名区间的所有成员
14:ZREMRANGEBYSCORE key min max
移除有序集合中给定的分数区间的所有成员
15:ZREVRANGE key start stop [WITHSCORES]
返回有序集中指定区间内的成员,通过索引,分数从高到低
16:ZREVRANGEBYSCORE key max min [WITHSCORES]
返回有序集中指定分数区间内的成员,分数从高到低排序
17:ZREVRANK key member
返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
18:ZSCORE key member
返回有序集中,成员的分数值
19:ZUNIONSTORE destination numkeys key [key ...]
计算给定的一个或多个有序集的并集,并存储在新的 key 中
20:ZSCAN key cursor [MATCH pattern] [COUNT count]
迭代有序集合中的元素(包括元素成员和元素分值)存储(实现)原理
同时满足以下条件时使用 ziplist 编码:
元素数量小于 128 个
所有 member 的长度都小于 64 字节
在 ziplist 的内部,按照 score 排序递增来存储。插入的时候要移动之后的数据。
对应 redis.conf 参数:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
超过阈值之后,使用 skiplist+dict 存储。应用场景
1:排行榜实现:id 为 6001 的新闻点击数加 1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的 15 条:zrevrange hotNews:20190926 0 15 withscores到这位置,我们对redis的一些基本类型,除了用之外,对于它的数据结构基本上的了解还是有的了。还有其他的一些类型streams等可以看,好的就这样,潦草收工:
redis的五种常用数据结构、Pub/Sub数据结构、Stream数据结构_数据库_weixin_40663800的博客-CSDN博客 blog.csdn.net
以上是关于对redis基础知识记录的主要内容,如果未能解决你的问题,请参考以下文章