Lecture 11 检测与分割
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lecture 11 检测与分割相关的知识,希望对你有一定的参考价值。
参考技术A我们之前都是图像分类的任务,最后一个全连接层得到所有分类的得分。现在我们来研究计算机视觉的其他任务,比如语义分割、图像分类与定位、目标检测、实例分割等。
在 语义分割 任务中,输入一张图片,希望输出能对图像的每个像素做出分类,判断这个像素是属于物体或者背景,不再像之前那样整张图片都是一个类。语义分割不会区分实例,只关心像素,所以如果图中有两头牛,会把两块像素都归为牛,不会分开每一头,以后会讲到 实例分割 (Instance Segmentation)可以区分实例。
实现语义分割的一个想法是 滑动窗口 ,即将图像分成一个个的小块,然后使用CNN网络计算小块的中心元素属于哪个分类。这样做的一个问题是,需要为每个像素计算一次,很多运算都是重复的,实际上没人会这么做。
另一个想法是 全卷积 ( Fully Convolutional),将网络的所有层都设计成卷积层,这样就能实现一次对图像的所有像素进行预测。比如使用3x3的卷积层然后使用零填充保持输入输出的空间尺寸,最终得到一个CxHxW的特征图,其中C是像素分类的数量,这样的一个特征图就一次计算了所有像素的分类得分。然后使用交叉熵损失、取平均、反向传播等操作进行训练。由于要为每个像素设置标签,这样的数据集花费是非常昂贵的。这里的数据集需要先确定图像属于哪个类别,比如猫,然后对图像的像素点设置类别。实际应用中,如果一直保持空间尺寸的话计算量会很庞大,所以不能设置这种结构。
使用全卷积网络的一种好的形式是在网络内部使用 降采样 (downsampling)然后使用 升采样 (upsampling),只在最初的几个卷积层保持尺寸,然后降采样比如池化或跨进卷积(strided convolution)来降低尺寸,进行一系列卷积后升采样到原来的尺寸。之所以需要去池化是因为池化减少了像素值,降低了图像的清晰度,丢失了图像空间结构,不知道这些像素原来在哪里,所以也就不明确边界应该在什么位置,所以需要进行去池化得到这些空间信息。
然后问题是如何进行升采样呢?
在一维中可能会表现的更清晰:滤波器被输入加权后直接放到输出中,输出的步长为2,下一个位置要平移两个像素,重叠的部分直接相加。最后为了使输出是输入的两倍,需要裁掉一个像素。
之所以称作转置卷积,可以通过矩阵乘法来解释,以一个一维的输入为例 a = [a, b, c, d],现在做 3x1 的卷积,卷积核为 [x, y, z],步长1填充1,此时的卷积可以看作是卷积核组成的一个大的矩阵 X 与输入 a 做乘法,如下图左边所示。(图上应为xyz,书写错误。)卷积核在输入 a 上滑动对应元素相乘后相加得到输出的过程,完全等价于卷积核组成的大矩阵与输入 a 的乘法。然后将 X 转置与 a 相乘,即转置卷积,结果就是一个正常的卷积,改变的只是填充规则。
现在如果步长为2,情况就不一样了。左边的卷积仍然可以看作是乘法,而右侧的转置卷积就变成用输入加权后的卷积核在输出上的叠加。
综上,语义分割任务的实现方法如下图所示:
此外, 多视角3D重建 ( Multi-view 3D Reconstruction)也使用了降采样和升采样的方法。
定位 ( Localization)往往是与 分类 (Classificatio)结合在一起的,如果图片分类是一只猫,同时我们也想知道猫在这张图片的什么位置,要用一个框给框起来。这与 目标检测 (Object Detection)是不同的,定位是一旦图像已经归为哪一类,比如猫,这样我们就会有一个明确的目标去寻找,找出它的边界即可。而目标检测是要检测出图像上存在的物体。
定位可以复用分类的方法,比如AlexNet。如下图所示,最后一个全连接层,除了得到1000个类别的得分,还会得到一个长为4的向量,表示目标的位置。这样最后就有两个损失,一个是正确分类的Softmax损失,另一个是正确位置的L2损失,L1、L2等损失也称作 回归损失 (Regression Loss)。最后将两个损失通过某些超参数加权得到总损失,和之前的超参数不同的是,以前的超参数改变是为了减小损失,而这里的加权超参数直接会改变损失值的表达式,损失变大变小都有可能。使用总损失求梯度。这里使用的网络是使用ImageNet 预训练过的模型,进行迁移学习。
目标检测任务是这样的:我们有几个感兴趣的类别,比如猫狗鱼等等,现在输入一张图像,图像上有几个物体事先是不知道的,当我们我们感兴趣的物体在图像上出现时,我们希望模型能自动标记出目标物体的位置,并判断出具体的分类。这实际上是很有挑战的任务,也是计算机视觉中很核心的任务,对此的研究已经经历了很多年,也有非常多的方法。
与定位最大的区别是,我们不知道图上会有多少对象。比如图像上只有一只猫,我们最终的输出只有一个位置四个数字;有两只狗一只猫,会输出3个位置12个数字;那么有一群鸭子呢?数量就很多了。所以目标检测问题不能看作定位中的回归问题。
另一个想法是把目标检测问题看作分类问题。类似语义分割的想法,将图像分成一个个的小块,让每一个小块通过卷积网络判断这块是背景?是猫?是狗?可以这么想,但是这个小块该怎么获得呢?不同的物体可能会有不同的大小、位置以及长宽比,这将是无数的情况,如果都要进行卷积,那么计算量是非常大的。
实际上,更实用的方法是 候选区域 (Region Proposals )方法。 选择性搜索 (Selective Search )方法就是在目标对象周围设定2000个形状大小位置不一的候选区域,目标物体在候选区域的可能性还是比较大的。然后对这些区域卷积,找到目标物体,虽然大多数区域都是无用的。与寻找几乎个区域比起来,这种方法要高效的多。此外,这不是深度学习的方法,是机器学习算法。 R-CNN 就是基于这种观点提出的。首先对输入图片使用区域备选算法,获取2000个感兴趣的区域(Regions of interest, roi),由于这些区域大小不一,所以需要处理成同样的尺寸才能通过CNN,之后使用SVM对区域进行分类。可以使用线性回归损失来校正包围框,比如虽然这个框选中的物体是一个缺少头部的狗,就需要对包围框进行校正。总之,这是一个多损失网络。
R-CNN的问题是计算消耗大、磁盘占用多、运行速度慢,即使测试时也要30秒测试一张图片,因为有2000个区域。解决方法时使用 快速R-CNN (Fast R-CNN ),不在原始图像生成备选区域,而是先整张图片通过卷积网络得到特征图,然后在特征图上使用备选区域算法得到感兴趣的区域在特征图的映射,之后使用 Rol Pool将所有区域变成同样尺寸。然后一方面使用softmax损失进行分类,一方面使用回归损失比如L1平滑损失校正包围框,总损失是两部分的和,然后反向传播进行训练。
如下图所示,效果还是很明显的。但是快速R-CNN也有一个问题是运行时间被区域备选方案限制。
解决方案是 更快的R-CNN (Faster R-CNN)。这种方法的改进是与其使用固定的算法得到备选区域,不如让网络自己学习自己的备选区域应该是什么。如下图所示,前面仍然是通过卷积网络获得特征图,然后通过一个 备选区域网络 (Region Proposal Network,RPN),该网络会做两件事,一是计算分类损失,选择的区域是目标还是不是目标;二是校正包围框。得到备选区域后接下来的步骤就和快速R-CNN一致了,也是得到最后的分类得分和校正包围框。训练的过程会综合这四个损失,最终效果很好。
Mask R-CNN是在Faster R-CNN基础上改进而来,是2017年发布的方法。首先将整张图像通过卷积网络和候选框生成网络,得到候选特征在特征图上的映射再调整尺寸,到这里和Faster R-CNN都是相同的;现在不仅是得到分类得分和校正包围框,还要增加一个分支通过卷积网络对每一个候选框预测一个分割区域模板。这个新增的分支就是一个在候选框中进行的微型语义分割任务。这样上下两个分支的任务就很明确了——上面的分支需要计算分类得分确定候选框中的目标属于哪个分类以及通过对候选框坐标的回归来预测边界框的坐标;下面的分支基本类似一个微型语义分割网络,会对候选框中的每个像素进行分类,判断每个像素是否属于候选框的中目标。
Mask R-CNN综合了上面讲的很多方法,最终的效果也是非常好的。比如下图最左边,不仅框出了每个物体还分割了像素,即使很远地方的人也被清晰的分割出来了。
此外,Mask R-CNN也可以识别动作,方法是在上面分支中增加一个关节坐标损失,这样就能同时进行分类、检测、动作识别、语义分割。此外,基于Faster R-CNN,运行速度也是非常快的。下图展示的效果是很令人惊讶的,可以同时识别出图上有多少人,分割出他们的像素区域,并且会标示他们的动作姿势。
使用前馈模型。
YOLO 即 “You Only Look Once” 和 SSD 即 “Single-Shot MultiBox Detector”,这两个模型是在同一时期提出的(2016),它们不会使用候选框分别进行处理,而是尝试将其作为回归问题,通过一个大的卷积网络,一次完成所有预测。给定输入图像,分成网格状比如7x7,然后在每个小单元中心处使用 B 个基本的边界框,比如高的、宽的、正方形的,这样总共有 7x7xB个基本框。现在想对每个网格单元的所有基本边界框预测目标物体,首先要预测每个基本边界框偏移来确定边界框和真实物体的位置差值,使用5个值(dx, dy, dh, dw, confidence)来表示偏差;然后预测每个网格单元里目标的 C 个分类(包括背景)得分,这样每个网格单元都会得到一个分类得分,即目标所属类别。最终的输出就是一个三维的张量:7x7x(5*B+C)。
TensorFlow Detection API(Faster RCNN, SSD, RFCN, Mask R-CNN): 点击这里
二维平面的目标检测只需确定 [x, y, w, h],3D的定位框需要确定的坐标为 [x, y, z, roll, pitch, yaw],简化后可以不需要 roll 和 pitch。比2D目标检测要复杂的多。
NIPS2018实时联合目标检测与语义分割网络

本文发表于第32届神经信息处理系统会议(NIPS 2018),是法国汽车零部件供应商法雷奥集团(Valeo)研究提出的一种用于自动驾驶领域的多任务神经网络,可同时执行目标检测与语义分割任务。
代码开源地址:https://github.com/MarvinTeichmann/MultiNet
Abstract
卷积神经网络(CNN)被成功地用于各种视觉感知任务,包括目标检测、语义分割、光流、深度估计和视觉SLAM。通常,这些任务是独立探索和建模的。
本文提出了一种同时进行学习目标检测和语义分割的联合多任务网络设计。主要目的是通过共享两个任务的编码器来实现低功耗嵌入式SOC的实时性能。我们使用一个类似于ResNet10的小型编码器构建了一个高效的体系结构,该编码器为两个解码器所共享。目标检测使用YOLOv2类解码器,语义分割使用FCN作为解码器。
我们在两个公共数据集(Kitti,Cityscapes)和我们的私有鱼眼摄像机数据集中对所提出的网络进行了评估,并证明了联合网络与单独网络具有相同的准确率。我们进一步优化了网络,使1280x384分辨率的图像达到30fps。
1. Introduction
卷积神经网络(CNNs)已经成为自动车辆中大多数视觉感知任务的标准构件。目标检测是CNN在行人和车辆检测中的首批成功应用之一。近年来,语义分割逐渐成熟,从检测道路、车道、路缘等道路对象开始。尽管嵌入式系统的计算能力有了很大提高,专用CNN硬件加速器的趋势也在不断发展,但高精度的语义分割的实时性能仍然具有挑战性。本文提出了一种语义分割和目标检测的实时联合网络,覆盖了自动驾驶中所有的关键对象。
论文的其余部分结构如下。第二节回顾了目标检测在自动驾驶中的应用,并提供了使用多任务网络解决该问题的动机。第三部分详细介绍了实验装置,讨论了所提出的体系结构和实验结果。最后,第四部分对论文进行了总结,并提出了未来可能的研究方向。
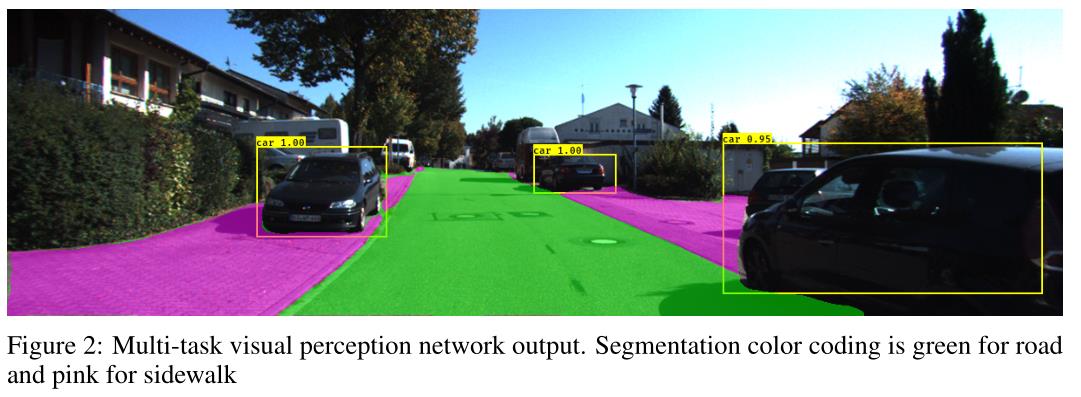
2. Multi-task learning in Automated Driving
多任务的联合学习属于机器学习的一个子分支,称为多任务学习。多任务联合学习背后的基本理论是,网络在接受多任务训练时可以表现得更好,因为它们通过利用任务间规则来更快地学习游戏规则。这些网络不仅具有较好的通用性,而且降低了计算复杂度,使其在低功耗嵌入式系统中非常有效。最近的进展表明,CNN可以用于各种任务[6],包括运动目标检测[13]、深度估计[8]和视觉SLAM[9]。
我们的工作最接近于最近的MultiNet[14]。我们的不同之处在于,我们关注的是更小的网络,更多类的两个任务,以及在三个数据集中进行的更广泛的实验。
2.1 Important Objects for Automated Driving
流行的语义分割汽车数据集有CamVid[1]和较新的City Scenes[3]。后者具有5000个注释帧的大小,这是相对较小的。在这个数据集上训练的算法不能很好地推广到在其他城市和隧道等看不见的对象上测试的数据。为了弥补这一点,我们创建了像Synthia[11]和Virtual Kitti[4]这样的合成数据集。有一些文献表明,在较小的数据集中,组合会产生合理的结果。但对于自动驾驶系统的商业部署来说,它们仍然有限。因此,最近正在努力构建更大的语义细分数据集,如Mapillary vistas数据集[10]和ApolloScape[7]。Mapillary数据集由25,000幅图像组成,共100类。ApolloScape数据集由50个类别的143,000张图像组成。
2.2 Pros and Cons of MTL
在本文中,我们提出了一种具有共享编码器的网络结构,该编码器可以共同学习。其主要优点是提高了效率、可伸缩性,可以利用先前的功能添加更多任务,并通过归纳迁移(任务的学习可转移特征)实现更好的泛化。我们将在下面更详细地讨论共享网络的优缺点。
共享网络的优点:
- 计算效率:共享功能背后简单易懂的直觉提高了计算效率。假设有两个类和两个独立的网络,分别占用50%的处理能力。如果有可能在两个网络之间共享30%,则每个网络都可以重复使用额外的15%来单独创建一个稍大的网络。有大量的经验证据表明,网络的初始层是与任务无关的(oriented Gabor filters),我们应该能够进行一定程度的共享,越多越好。
- 泛化和准确性:在忽略计算效率的情况下,共同学习的网络往往泛化得更好、更准确。这就是为什么ImageNet上的迁移学习非常流行的原因,那里有网络学习非常复杂的类别,比如区分特定种类的狗。因为拉布拉多犬和博美拉多犬这两个物种之间的细微差别是后天习得的,所以它们更善于检测一项更简单的犬类检测任务。另一个论点是,当他们共同学习时,过度适应某项特定任务的可能性较小。
- 可扩展到更多任务,如流量估计、深度、通信和跟踪。因此,可以协调共同的CNN特写流水线,以用于各种任务。
共享网络的缺点:
- 在非共享网络的情况下,算法是完全独立的。这可以使数据集设计、体系结构设计、调优、硬负面挖掘等变得更简单、更容易管理。
- 调试共享网络(尤其是当它不工作时)相对较难。
3. Proposed Algorithm and Results
3.1 Network Architecture
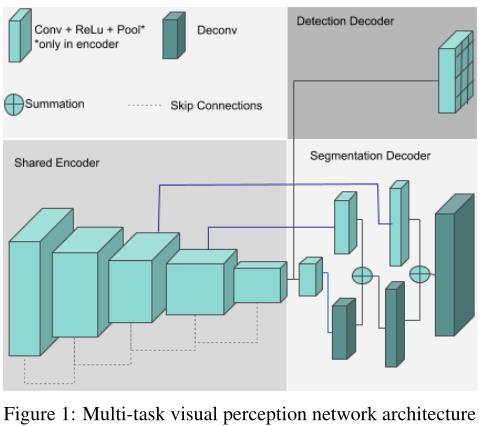
在本节中,我们将报告我们计划改进的基线网络设计的结果。我们在图1的高级框图中提出了一种联合学习的共享编码器网络体系结构。我们实现了一个由3个分割类(背景、道路、人行道)和3个对象类(汽车、人、骑车人)组成的两任务网络。
为了在低功耗嵌入式系统上实现可行性,我们使用了一个名为 Resnet10 的小型编码器,该编码器完全共享这两个任务。FCN8 作为语义分割的解码器,YOLO 作为目标检测的解码器。语义分割的损失函数是最小化误分类的交叉熵损失。对于几何函数,以平方误差损失的形式将目标定位的平均精度作为误差函数。对于这两个任务,我们使用单个损失的加权和 L = w s e g ∗ L s e g + w d e t ∗ L d e t L=w_seg∗L_seg+w_det∗L_det L=wseg∗Lseg+wdet∗Ldet。在鱼眼相机具有较大空间变异畸变的情况下,我们使用多项式模型实现了镜头畸变校正。
3.2 Experiments
在这一部分中,我们将解释实验设置,包括使用的数据集、训练算法细节等,并讨论结果。
我们在包含5000张图像和两个公开可用的数据集Kitti[5]和CitySces[3]的内部鱼眼数据集上进行了训练和评估。我们使用Keras[2]实现了不同提出的多任务架构。我们使用了来自ImageNet的预先训练好的Resnet10编码器权重,然后针对这两个任务进行了微调。FCN8上采样层使用随机权重进行初始化。
我们使用ADAM优化器,因为它提供了更快的收敛速度,学习率为0.0005。优化器采用分类交叉熵损失和平方误差损失作为损失函数。以平均类IOU(交集)和每类IOU作为语义分割的精度度量,以平均平均精度(MAP)和每类平均精度作为目标检测的精度度量。由于多个任务需要内存,所有输入图像的大小都调整为1280x384。
表1总结了在Kitti、Citycapes和我们的内部鱼眼数据集上STL网络和MTL网络所获得的结果。这旨在为合并更复杂的多任务学习技术提供基准精度。我们将分割网络(STL Seg)和检测网络(STL Det)与执行分割和检测的MTL网络(MTL、MTL100和MTL100)进行比较。
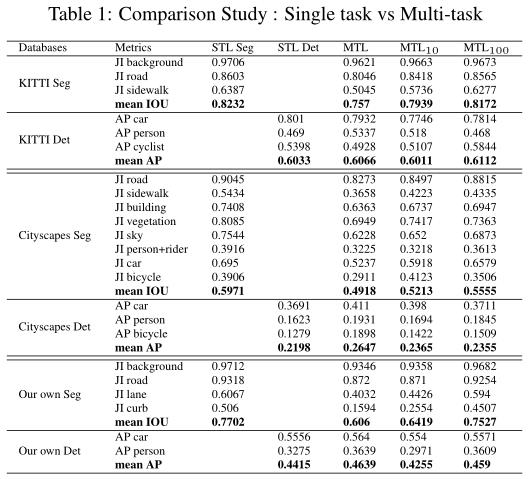
我们测试了MTL损耗的3种配置,第一种配置(MTL)使用分割损耗和检测损耗的简单和 ( w s e g = w d e t = 1 ) (w_seg=w_det=1) (wseg=wdet=1)。另外两个配置MTL10和MTL100使用任务损失的加权和,其中分割损失分别用权重 w s e g = 10 w_seg=10 wseg=10 和 w s e g = 100 w_seg=100 wseg=100加权。这弥补了任务损失尺度的差异:在训练过程中,分割损失是检测损失的10-100倍。
MTL网络中的这种加权提高了3个数据集的分割任务的性能。即使分割任务的MTL结果略低于STL(Single-task Learning)结果,本实验也表明,通过正确调整参数,多任务网络具有学习更多的能力。此外,通过保持几乎相同的精度,我们在内存和计算效率方面有了显著的提高。我们利用几种标准的优化技术来进一步改善运行时间,并在汽车级低功耗SOC上实现30fps。
4 Conclusion
本文中,我们讨论了多任务学习在自动驾驶环境中的应用,用于联合语义分割和目标检测任务。首先,我们激发了完成这两项任务的需要而不仅仅是语义分割。
然后我们讨论了使用多任务方法的利弊。我们通过精心选择编解码器,构建了一个高效的联合网络,并对其进行了进一步优化,在低功耗的嵌入式系统上达到了30fps。
我们分享了在三个数据集上的实验结果,证明了联合网络的有效性。在未来的工作中,我们计划探索增加视觉感知任务,如深度估计、流量估计和视觉SLAM。
更多精彩内容,请关注我的公众号【AI 修炼之路】!
以上是关于Lecture 11 检测与分割的主要内容,如果未能解决你的问题,请参考以下文章