硬核干货!7600字带你学会 Redis 性能优化点, 建议收藏!
Posted Java之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了硬核干货!7600字带你学会 Redis 性能优化点, 建议收藏!相关的知识,希望对你有一定的参考价值。
来源:rrd.me/gteAC
在一些网络服务的系统中,Redis 的性能,可能是比 mysql 等硬盘数据库的性能更重要的课题。比如微博,把热点微博[1],最新的用户关系,都存储在 Redis 中,大量的查询击中 Redis,而不走 MySQL。
那么,针对 Redis 服务,我们能做哪些性能优化呢?或者说,应该避免哪些性能浪费呢?
Redis 性能的基本面
在讨论优化之前,我们需要知道,Redis 服务本身就有一些特性,比如单线程运行。除非修改 Redis 的源代码,不然这些特性,就是我们思考性能优化的基本面。
那么,有哪些 Redis 基本特性需要我们考虑呢?Redis 的项目介绍中概括了它特性:
Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported.
首先,Redis 使用操作系统提供的虚拟内存来存储数据。而且,这个操作系统一般就是指 Unix。Windows 上也能运行 Redis,但是需要特殊处理。如果你的操作系统使用交换空间,那么 Redis 的数据可能会被实际保存在硬盘上。
其次,Redis 支持持久化,可以把数据保存在硬盘上。很多时候,我们也确实有必要进行持久化来实现备份,数据恢复等需求。但持久化不会凭空发生,它也会占用一部分资源。
第三,Redis 是用 key-value 的方式来读写的,而 value 中又可以是很多不同种类的数据;更进一步,一个数据类型的底层还有被存储为不同的结构。不同的存储结构决定了数据增删改查的复杂度以及性能开销。
最后,在上面的介绍中没有提到的是,Redis 大多数时候是单线程运行[2]的(single-threaded),即同一时间只占用一个 CPU,只能有一个指令在运行,并行读写是不存在的。很多操作带来的延迟问题,都可以在这里找到答案。
关于最后这个特性,为什么 Redis 是单线程的,却能有很好的性能(根据 Amdahl’s Law,优化耗时占比大的过程,才更有意义),两句话概括是:Redis 利用了多路 I/O 复用机制[3],处理客户端请求时,不会阻塞主线程;Redis 单纯执行(大多数指令)一个指令不到 1 微秒[4],如此,单核 CPU 一秒就能处理 1 百万个指令(大概对应着几十万个请求吧),用不着实现多线程(网络才是瓶颈[5])。
优化网络延时
Redis 的官方博客在几个地方都说,性能瓶颈更可能是网络[6],那么我们如何优化网络上的延时呢?
首先,如果你们使用单机部署(应用服务和 Redis 在同一台机器上)的话,使用 Unix 进程间通讯来请求 Redis 服务,速度比 localhost 局域网(学名 loopback)更快。官方文档[7]是这么说的,想一想,理论上也应该是这样的。
但很多公司的业务规模不是单机部署能支撑的,所以还是得用 TCP。
Redis 客户端和服务器的通讯一般使用 TCP 长链接。如果客户端发送请求后需要等待 Redis 返回结果再发送下一个指令,客户端和 Redis 的多个请求就构成下面的关系:
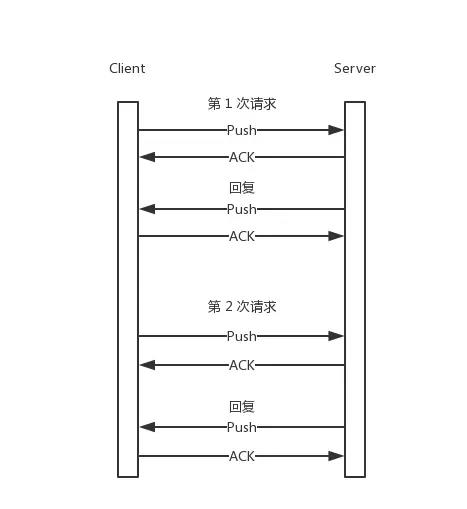
(备注:如果不是你要发送的 key 特别长,一个 TCP 包完全能放下 Redis 指令,所以只画了一个 push 包)
这样这两次请求中,客户端都需要经历一段网络传输时间。
但如果有可能,完全可以使用 multi-key 类的指令来合并请求,比如两个 GET key 可以用 MGET key1 key2 合并。这样在实际通讯中,请求数也减少了,延时自然得到好转。
如果不能用 multi-key 指令来合并,比如一个 SET,一个 GET 无法合并。怎么办?
Redis 中有至少这样两个方法能合并多个指令到一个 request 中,一个是 MULTI/EXEC,一个是 script。前者本来是构建 Redis 事务的方法,但确实可以合并多个指令为一个 request,它到通讯过程如下。至于 script,最好利用缓存脚本的 sha1 hash key 来调起脚本,这样通讯量更小。
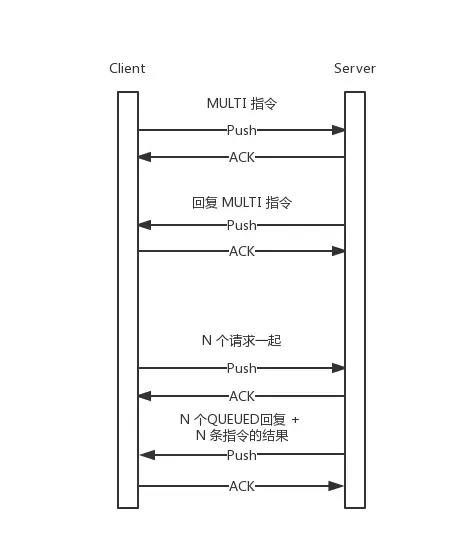
这样确实更能减少网络传输时间,不是么?但如此以来,就必须要求这个 transaction / script 中涉及的 key 在同一个 node 上,所以要酌情考虑。
如果上面的方法我们都考虑过了,还是没有办法合并多个请求,我们还可以考虑合并多个 responses。比如把 2 个回复信息合并:
这样,理论上可以省去 1 次回复所用的网络传输时间。这就是 pipeline 做的事情。举个 ruby 客户端使用 pipeline 的例子:
require 'redis'
@redis = Redis.new()
@redis.pipelined do
@redis.get 'key1'
@redis.set 'key2' 'some value'
end
# => [1, 2]
据说,有些语言的客户端,甚至默认就使用 pipeline 来优化延时问题,比如 node_redis。
另外,不是任意多个回复信息都可以放进一个 TCP 包中,如果请求数太多,回复的数据很长(比如 get 一个长字符串),TCP 还是会分包传输,但使用 pipeline,依然可以减少传输次数。
pipeline 和上面的其他方法都不一样的是,它不具有原子性。所以在 cluster 状态下的集群上,实现 pipeline 比那些原子性的方法更有可能。
小结一下:
-
使用 unix 进程间通信,如果单机部署 -
使用 multi-key 指令合并多个指令,减少请求数,如果有可能的话 -
使用 transaction、script 合并 requests 以及 responses -
使用 pipeline 合并 response
警惕执行时间长的操作
在大数据量的情况下,有些操作的执行时间会相对长,比如 KEYS *,LRANGE mylist 0 -1,以及其他算法复杂度为 O(n) 的指令。因为 Redis 只用一个线程来做数据查询,如果这些指令耗时很长,就会阻塞 Redis,造成大量延时。
尽管官方文档中说 KEYS * 的查询挺快的,(在普通笔记本上)扫描 1 百万个 key,只需 40 毫秒(参见:https://redis.io/commands/keys),但几十 ms 对于一个性能要求很高的系统来说,已经不短了,更何况如果有几亿个 key(一台机器完全可能存几亿个 key,比如一个 key 100字节,1 亿个 key 只有 10GB),时间更长。
所以,尽量不要在生产环境的代码使用这些执行很慢的指令,这一点 Redis 的作者在博客[8]中也提到了。另外,运维同学查询 Redis 的时候也尽量不要用。甚至,Redis Essential 这本书建议利用 rename-command KEYS '' 来禁止使用这个耗时的指令。
除了这些耗时的指令,Redis 中 transaction,script,因为可以合并多个 commands 为一个具有原子性的执行过程,所以也可能占用 Redis 很长时间,需要注意。
如果你想找出生产环境使用的「慢指令」,那么可以利用 SLOWLOG GET count 来查看最近的 count 个执行时间很长的指令。至于多长算长,可以通过在 redis.conf 中设置 slowlog-log-slower-than 来定义。
除此之外,在很多地方都没有提到的一个可能的慢指令是 DEL,但 redis.conf 文件的注释[9]中倒是说了。长话短说就是 DEL 一个大的 object 时候,回收相应的内存可能会需要很长时间(甚至几秒),所以,建议用 DEL 的异步版本:UNLINK。后者会启动一个新的 thread 来删除目标 key,而不阻塞原来的线程。
更进一步,当一个 key 过期之后,Redis 一般也需要同步的把它删除。其中一种删除 keys 的方式是,每秒 10 次的检查一次有设置过期时间的 keys,这些 keys 存储在一个全局的 struct 中,可以用 server.db->expires 访问。检查的方式是:
-
从中随机取出 20 个 keys -
把过期的删掉。 -
如果刚刚 20 个 keys 中,有 25% 以上(也就是 5 个以上)都是过期的,Redis 认为,过期的 keys 还挺多的,继续重复步骤 1,直到满足退出条件:某次取出的 keys 中没有那么多过去的 keys。
这里对于性能的影响是,如果真的有很多的 keys 在同一时间过期,那么 Redis 真的会一直循环执行删除,占用主线程。
对此,Redis 作者的建议[10]是警惕 EXPIREAT 这个指令,因为它更容易产生 keys 同时过期的现象。我还见到过一些建议是给 keys 的过期时间设置一个随机波动量。最后,redis.conf 中也给出了一个方法,把 keys 的过期删除操作变为异步的,即,在 redis.conf 中设置 lazyfree-lazy-expire yes。
优化数据结构、使用正确的算法
一种数据类型(比如 string,list)进行增删改查的效率是由其底层的存储结构决定的。
我们在使用一种数据类型时,可以适当关注一下它底层的存储结构及其算法,避免使用复杂度太高的方法。举两个例子:
-
ZADD的时间复杂度是 O(log(N)),这比其他数据类型增加一个新元素的操作更复杂,所以要小心使用。 -
若 Hash 类型的值的 fields 数量有限,它很有可能采用 ziplist 这种结构做存储,而 ziplist 的查询效率可能没有同等字段数量的 hashtable 效率高,在必要时,可以调整 Redis 的存储结构。
如何做出更好的权衡?我觉得得深挖 Redis 的存储结构才能让自己安心。这方面的内容我们下次再说。
以上这三点都是编程层面的考虑,写程序时应该注意啊。下面这几点,也会影响 Redis 的性能,但解决起来,就不只是靠代码层面的调整了,还需要架构和运维上的考虑。
考虑操作系统和硬件是否影响性能
Redis 运行的外部环境,也就是操作系统和硬件显然也会影响 Redis 的性能。在官方文档中,就给出了一些例子:
-
CPU:Intel 多种 CPU 都比 AMD 皓龙系列好 -
虚拟化:实体机比虚拟机好,主要是因为部分虚拟机上,硬盘不是本地硬盘,监控软件导致 fork 指令的速度慢(持久化时会用到 fork),尤其是用 Xen 来做虚拟化时。 -
内存管理:在 linux 操作系统中,为了让 translation lookaside buffer,即 TLB,能够管理更多内存空间(TLB 只能缓存有限个 page),操作系统把一些 memory page 变得更大,比如 2MB 或者 1GB,而不是通常的 4096 字节,这些大的内存页叫做 huge pages。同时,为了方便程序员使用这些大的内存 page,操作系统中实现了一个 transparent huge pages(THP)机制,使得大内存页对他们来说是透明的,可以像使用正常的内存 page 一样使用他们。但这种机制并不是数据库所需要的,可能是因为 THP 会把内存空间变得紧凑而连续吧,就像 mongodb 的文档 [11]中明确说的,数据库需要的是稀疏的内存空间,所以请禁掉 THP 功能。Redis 也不例外,但 Redis 官方博客上给出的理由是:使用大内存 page 会使 bgsave 时,fork 的速度变慢;如果 fork 之后,这些内存 page 在原进程中被修改了,他们就需要被复制(即 copy on write),这样的复制会消耗大量的内存(毕竟,人家是 huge pages,复制一份消耗成本很大)。所以,请禁止掉操作系统中的 transparent huge pages 功能。 -
交换空间:当一些内存 page 被存储在交换空间文件上,而 Redis 又要请求那些数据,那么操作系统会阻塞 Redis 进程,然后把想要的 page,从交换空间中拿出来,放进内存。这其中涉及整个进程的阻塞,所以可能会造成延时问题,一个解决方法是禁止使用交换空间(Redis Essentials 中如是建议,如果内存空间不足,请用别的方法处理)。
考虑持久化带来的开销
Redis 的一项重要功能就是持久化,也就是把数据复制到硬盘上。基于持久化,才有了 Redis 的数据恢复等功能。
但维护这个持久化的功能,也是有性能开销的。
首先说,RDB 全量持久化。
这种持久化方式把 Redis 中的全量数据打包成 rdb 文件放在硬盘上。但是执行 RDB 持久化过程的是原进程 fork 出来一个子进程,而 fork 这个系统调用是需要时间的,根据Redis Lab 6 年前做的实验[12],在一台新型的 AWS EC2 m1.small^13 上,fork 一个内存占用 1GB 的 Redis 进程,需要 700+ 毫秒,而这段时间,redis 是无法处理请求的。
虽然现在的机器应该都会比那个时候好,但是 fork 的开销也应该考虑吧。为此,要使用合理的 RDB 持久化的时间间隔,不要太频繁。
接下来,我们看另外一种持久化方式:AOF 增量持久化。
这种持久化方式会把你发到 redis server 的指令以文本的形式保存下来(格式遵循 redis protocol),这个过程中,会调用两个系统调用,一个是 write(2),同步完成,一个是 fsync(2),异步完成。
这两部都可能是延时问题的原因:
-
write 可能会因为输出的 buffer 满了,或者 kernal 正在把 buffer 中的数据同步到硬盘,就被阻塞了。 -
fsync 的作用是确保 write 写入到 aof 文件的数据落到了硬盘上,在一个 7200 转/分的硬盘上可能要延时 20 毫秒左右,消耗还是挺大的。更重要的是,在 fsync 进行的时候,write 可能会被阻塞。
其中,write 的阻塞貌似只能接受,因为没有更好的方法把数据写到一个文件中了。但对于 fsync,Redis 允许三种配置,选用哪种取决于你对备份及时性和性能的平衡:
-
always:当把 appendfsync 设置为 always,fsync 会和客户端的指令同步执行,因此最可能造成延时问题,但备份及时性最好。 -
everysec:每秒钟异步执行一次 fsync,此时 redis 的性能表现会更好,但是 fsync 依然可能阻塞 write,算是一个折中选择。 -
no:redis 不会主动出发 fsync (并不是永远不 fsync,那是不太可能的),而由 kernel 决定何时 fsync
使用分布式架构 —— 读写分离、数据分片
以上,我们都是基于单台,或者单个 Redis 服务进行优化。下面,我们考虑当网站的规模变大时,利用分布式架构来保障 Redis 性能的问题。
首先说,哪些情况下不得不(或者最好)使用分布式架构:
-
数据量很大,单台服务器内存不可能装得下,比如 1 个 T 这种量级 -
需要服务高可用 -
单台的请求压力过大
解决这些问题可以采用数据分片或者主从分离,或者两者都用(即,在分片用的 cluster 节点上,也设置主从结构)。
这样的架构,可以为性能提升加入新的切入点:
-
把慢速的指令发到某些从库中执行 -
把持久化功能放在一个很少使用的从库上 -
把某些大 list 分片
其中前两条都是根据 Redis 单线程的特性,用其他进程(甚至机器)做性能补充的方法。
当然,使用分布式架构,也可能对性能有影响,比如请求需要被转发,数据需要被不断复制分发。(待查)
后话
其实还有很多东西也影响 Redis 的性能,比如 active rehashing(keys 主表的再哈希,每秒 10 次,关掉它可以提升一点点性能),但是这篇博客已经写的很长了。而且,更重要不是收集已经被别人提出的问题,然后记忆解决方案;而是掌握 Redis 的基本原理,以不变应万变的方式决绝新出现的问题。
参考资料
热点微博: https://www.infoq.cn/article/weibo-relation-service-with-redis
[2]单线程运行: https://redis.io/topics/latency#single-threaded-nature-of-redis
[3]多路 I/O 复用机制: https://redis.io/topics/clients#how-client-connections-are-accepted
[4]1 微秒: https://redis.io/topics/latency#redis-latency-problems-troubleshooting
[5]网络才是瓶颈: https://redis.io/topics/benchmarks#factors-impacting-redis-performance
[6]网络: https://redis.io/topics/latency#latency-induced-by-network-and-communication
[7]官方文档: https://redis.io/topics/benchmarks#factors-impacting-redis-performance
[8]博客: https://redis.io/topics/latency#i39ve-little-time-give-me-the-checklist
[9]注释: https://github.com/antirez/redis/blob/5.0/redis.conf#L669
[10]建议: https://redis.io/topics/latency#latency-generated-by-expires
[11]mongodb 的文档: https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
[12]实验: 参见:https://redis.io/topics/latency#fork-time-in-different-systems
有道无术,术可成;有术无道,止于术
好文章,我在看❤️
以上是关于硬核干货!7600字带你学会 Redis 性能优化点, 建议收藏!的主要内容,如果未能解决你的问题,请参考以下文章